mind x
1.0.0

Этот проект демонстрирует возможность использования персонализированных LLM (или LMM) в качестве личных помощников, идя в ногу с быстрым ростом этих моделей.
Мы внедрили метод дополнительной генерации (RAG), чтобы преодолеть ограничения традиционной быстрой настройки, которая имеет контекстные границы, и точной настройки, которая страдает от проблем с обновлением данных в реальном времени и галлюцинациями.
Традиционно RAG использовался для поиска в таких базах данных, как Chroma, через LangChain в качестве хранилища, но этот метод работает в фиксированных контекстах, что является ограничением.
Поэтому мы планируем построить собственную RAG-систему. Этот процесс может включать в себя решение проблем вывода и регрессии, которые может предложить LangChain.
Мы стремимся к быстрому развитию и вскоре обеспечим многоязычную совместимость. В настоящее время система полностью поддерживает английский язык, в ближайшее время планируется поддержка корейского, японского и других языков. Кроме того, в ближайшее время будут включены системы регрессии и вывода.
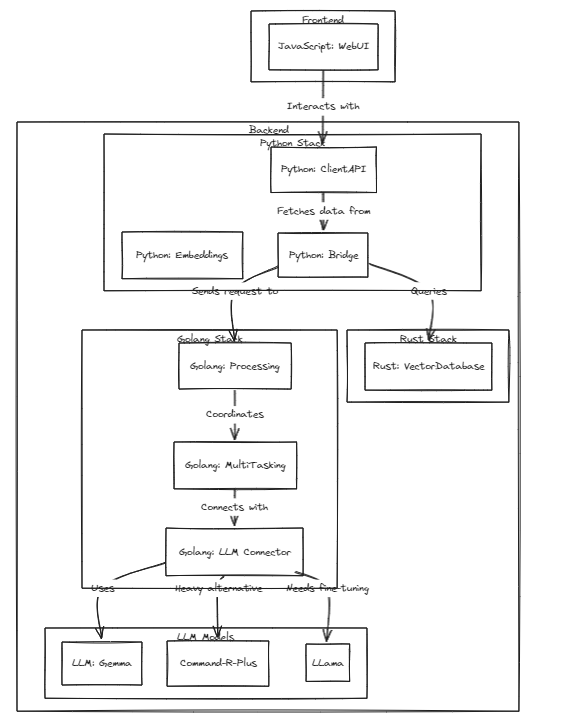
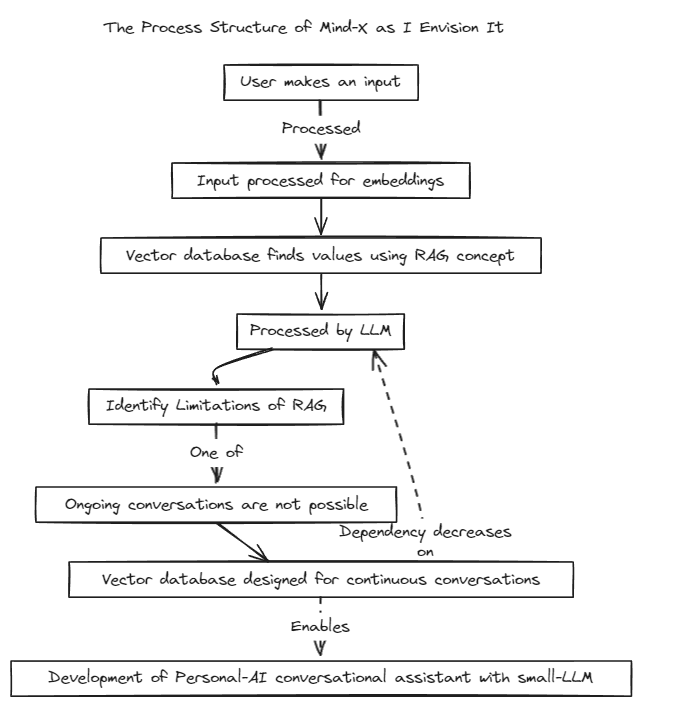
Чтобы запустить тесты, выполните следующую команду
# start embeddings server
cd embd & pip install -r requirements.txt
python app.py
# start mindx-v server (vector-database)
# not using cgo, only assembly
cd mindx-v & go run cmd/mxvd/main.go
# start processor server
cd processor & go run cmd/main.go
# start demo client
cd sample_client & npm start
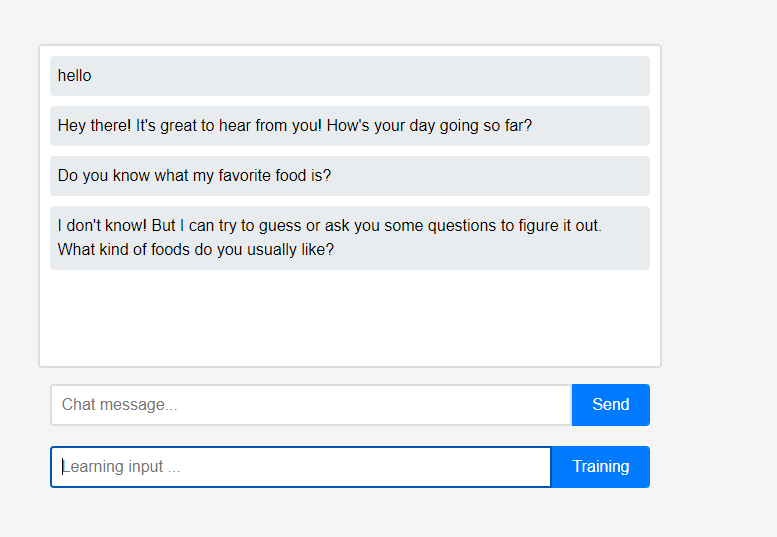 Изначально помощник ничего не знает о пользователе.
Изначально помощник ничего не знает о пользователе.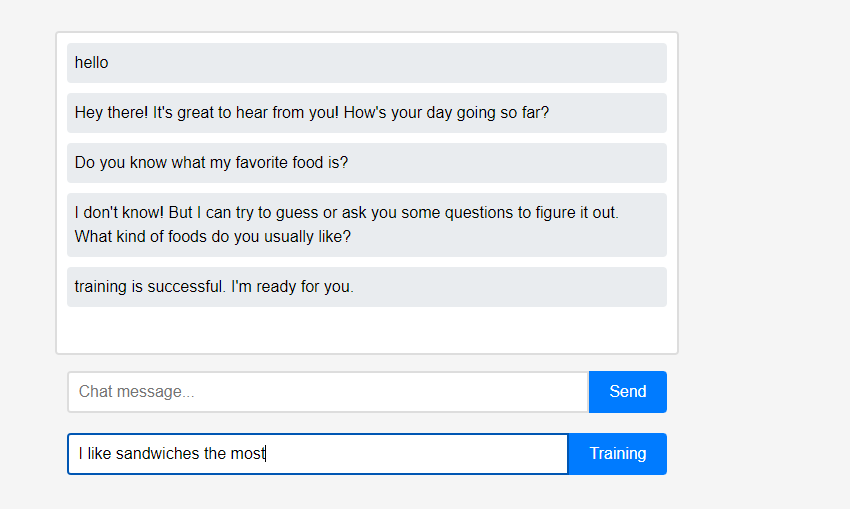 Однако пользователи могут рассказать помощнику о себе в режиме реального времени.
Однако пользователи могут рассказать помощнику о себе в режиме реального времени.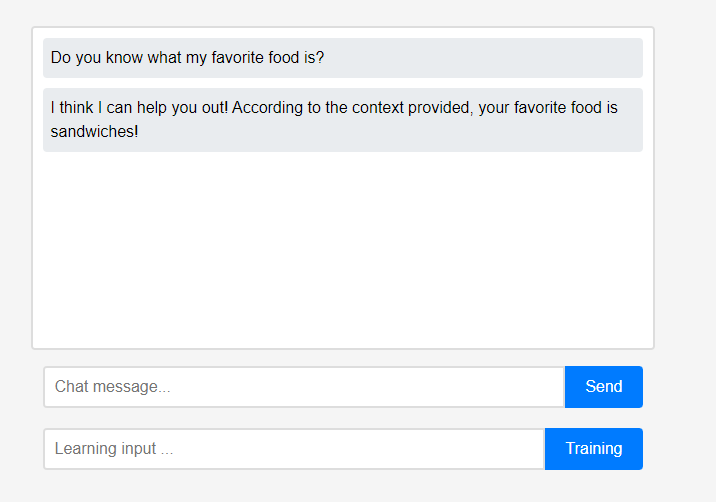 (Из-за характеристик LLM можно было неправильно понять, что он запоминался как цепочка разговоров, а не как обучение, поэтому это было сделано после обновления.) Изученные данные были немедленно отражены, и это можно рассматривать как первую персонализацию помощника.
(Из-за характеристик LLM можно было неправильно понять, что он запоминался как цепочка разговоров, а не как обучение, поэтому это было сделано после обновления.) Изученные данные были немедленно отражены, и это можно рассматривать как первую персонализацию помощника.
Все эти функции проекта могут поддерживаться локально без необходимости интеграции внешнего облака или подключения к Интернету.



query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/bad.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )
query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/good.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )


