idt
1.0.0

Инструмент набора данных изображений (IDT) — это приложение CLI, разработанное для упрощения и ускорения создания наборов данных изображений, которые будут использоваться для глубокого обучения. Инструмент достигает этого, собирая изображения из нескольких поисковых систем, таких как Duckgo, Bing и Deviantart. IDT также оптимизирует набор данных изображений, хотя эта функция не является обязательной, пользователь может уменьшить масштаб и сжать изображения для достижения оптимального размера и размеров файла. Образец набора данных, созданный с помощью idt и содержащий в общей сложности 23 688 файлов изображений, весит всего 559,2 мегабайта.
Я с гордостью сообщаю о нашей новейшей версии! ??
Что изменилось
Вы можете установить его через pip или клонировать этот репозиторий.
user@admin:~ $ pip3 install idt
ИЛИ
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
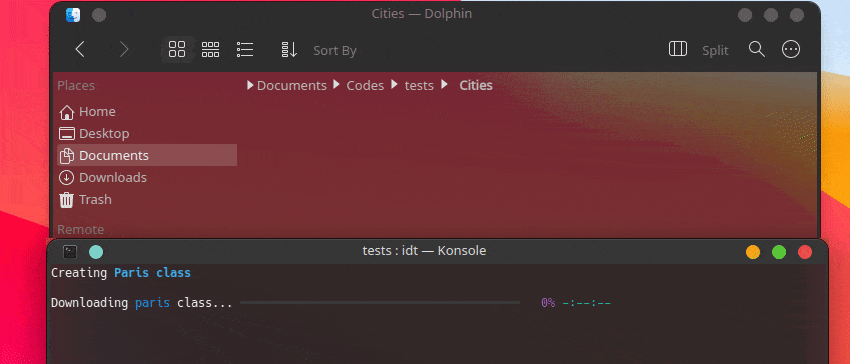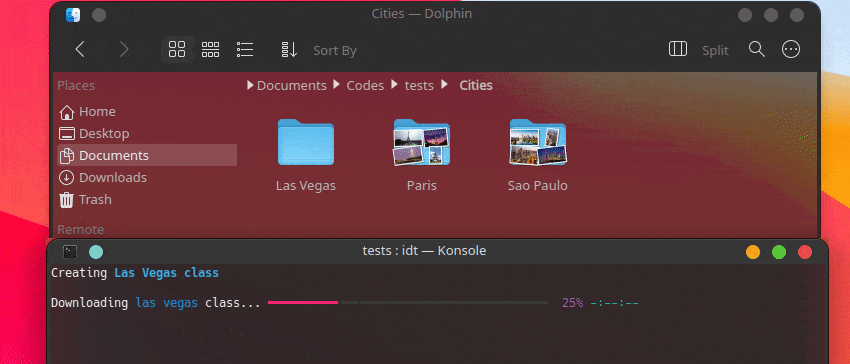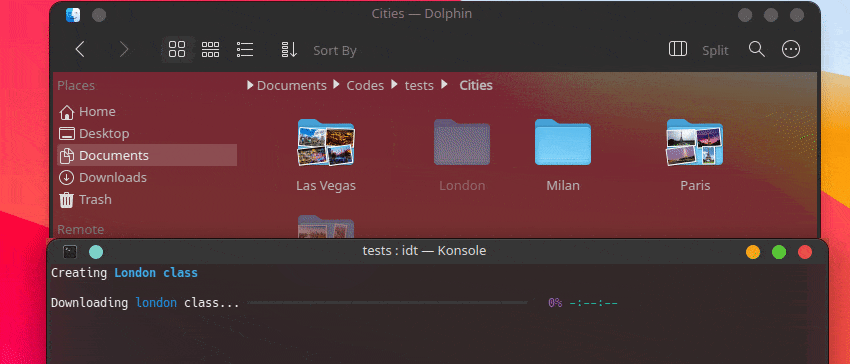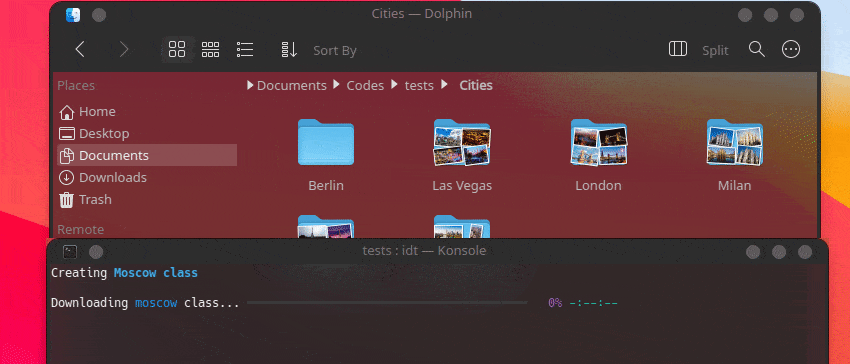
Самый быстрый способ начать работу с IDT — выполнить простую команду «Выполнить». Просто напишите в своей любимой консоли что-то вроде:
user@admin:~ $ idt run -i apples Это позволит быстро загрузить 50 изображений яблок. По умолчанию для этого используется поисковая система Duckgo. Команда запуска принимает следующие параметры:
| Вариант | Описание |
|---|---|
| -i или --input | ключевое слово для поиска нужных изображений. |
| -s или --size | количество изображений, которые необходимо загрузить. |
| -e или --engine | желаемая поисковая система (варианты:uckgo, bing, bing_api и flickr_api) |
| --resize-метод | выберите метод изменения размера изображений. (варианты: long_side, short_side и smartcrop) |
| -is или --image-size | возможность установить желаемое соотношение размеров изображения. по умолчанию = 512 |
| -ak или --api-key | Если вы используете поисковую систему, для которой требуется ключ API, эта опция обязательна. |
IDT требуется файл конфигурации, в котором указано, как должен быть организован ваш набор данных. Вы можете создать его с помощью следующей команды:
user@admin:~ $ idt initЭта команда запустит создатель файла конфигурации и запросит нужные параметры набора данных. В этом примере давайте создадим набор данных, содержащий изображения ваших любимых автомобилей. Первые параметры, которые задаст эта команда, — какое имя должно иметь ваш набор данных? В этом примере назовем наш набор данных «Мои любимые автомобили».
Insert a name for your dataset: : My favorite carsЗатем инструмент спросит, сколько образцов на каждый поиск требуется для монтирования вашего набора данных. Чтобы создать хороший набор данных для глубокого обучения, требуется много изображений, а поскольку мы используем поисковую систему для очистки изображений, для монтирования набора данных хорошего размера требуется множество поисков с разными ключевыми словами. Это значение будет соответствовать тому, сколько изображений должно быть загружено при каждом поиске. В этом примере нам нужен набор данных с 250 изображениями в каждом классе, и мы будем использовать 5 ключевых слов для монтирования каждого класса. Итак, если мы введем здесь число 50, IDT загрузит 50 изображений по каждому предоставленному ключевому слову. Если мы предоставим 5 ключевых слов, мы должны получить необходимые 250 изображений.
How many samples per search will be necessary? : 50Теперь инструмент запросит соотношение размеров изображения. Поскольку использование больших изображений для обучения нейронных сетей нецелесообразно, мы можем при желании выбрать одно из следующих соотношений размеров изображений и уменьшить наши изображения до этого размера. В этом примере мы выберем размер 512x512, хотя 256x256 будет еще лучшим вариантом для этой задачи.
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1Затем выберите «longer_side» для метода изменения размера.
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
Теперь вы должны выбрать, сколько классов/папок должно иметь ваш набор данных. В данном примере эта часть может быть очень личной, но мои любимые автомобили: Chevrolet Impala, Range Rover Evoque, Tesla Model X и (почему бы и нет) АвтоВАЗ Lada. Итак, в данном случае у нас есть 4 класса, по одному на каждого любимца.
How many image classes are required? : 4После этого вам будет предложено выбрать одну из доступных поисковых систем. В этом примере мы будем использовать DuckGO для поиска изображений.
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1Теперь нам нужно выполнить повторяющееся заполнение формы. Мы должны назвать каждый класс и все ключевые слова, которые будут использоваться для поиска изображений. Обратите внимание, что эту часть позже можно изменить с помощью вашего собственного кода, чтобы создать больше классов и ключевых слов.
Class 1 name: : Chevrolet ImpalaПосле ввода имени первого класса нам будет предложено ввести все ключевые слова для поиска набора данных. Помните, что мы сказали программе загрузить 50 изображений по каждому ключевому слову, поэтому в этом случае мы должны предоставить 5 ключевых слов, чтобы получить все 250 изображений. Каждое ключевое слово ДОЛЖНО быть разделено запятыми (,)
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
Затем повторите процесс заполнения имени класса и его ключевых слов, пока не заполните все 4 требуемых класса.
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!Файл конфигурации набора данных создан. Теперь просто введите следующую команду и увидите, как произойдет волшебство:
user@admin:~ $ idt buildИ подождите, пока монтируется набор данных:
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
В конце все ваши изображения будут доступны в папке с именем набора данных. Кроме того, в корневую папку набора данных также включен CSV-файл со статистикой набора данных.
Поскольку глубокое обучение часто требует разделения набора данных на подмножество папок обучения/проверки, этот проект также может сделать это за вас! Просто запустите:
user@admin:~ $ idt splitТеперь вы должны выбрать пропорцию поезд/действительность. В этом примере я выбрал, что 70% изображений будут зарезервированы для обучения, а остальные — для проверки:
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: yИ все! Разделение набора данных теперь должно быть найдено в соответствующих подкаталогах train/valid.
Этот проект разрабатывается в мое свободное время, и ему еще нужно приложить много усилий, чтобы не было ошибок. Запросы на включение и участники очень признательны, не стесняйтесь вносить свой вклад любым возможным способом!


