T5Elasticsearch
1.0.0
Ниже приведен пример поиска работы:
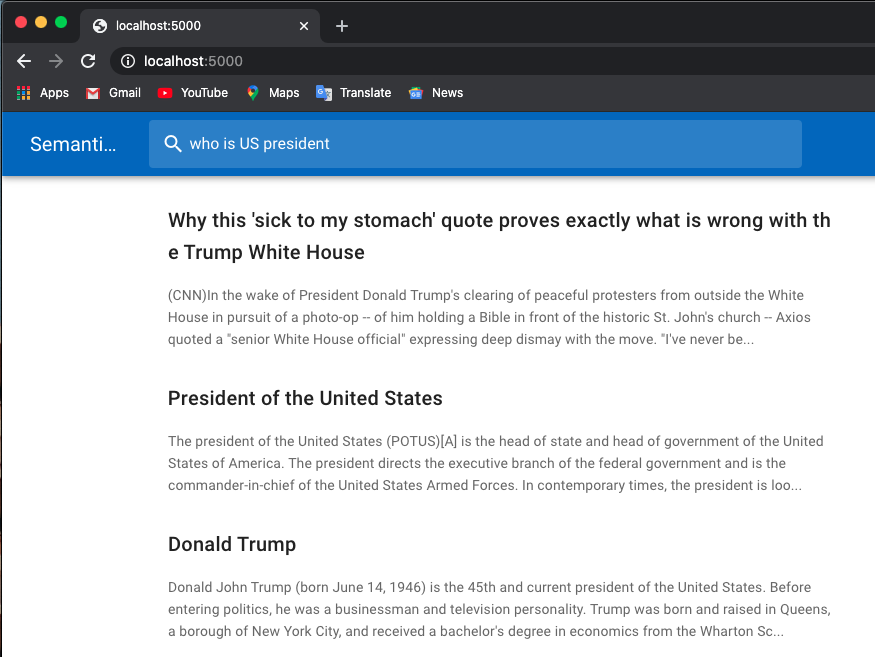
Я использую предварительно обученные модели из трансформеров Huggingface.
Вручную загрузите предварительно обученный токенизатор и модель t5/bert в локальные каталоги. Вы можете проверить модели здесь.
Я использую модель «t5-small», проверьте здесь и нажмите List all files in model чтобы загрузить файлы. 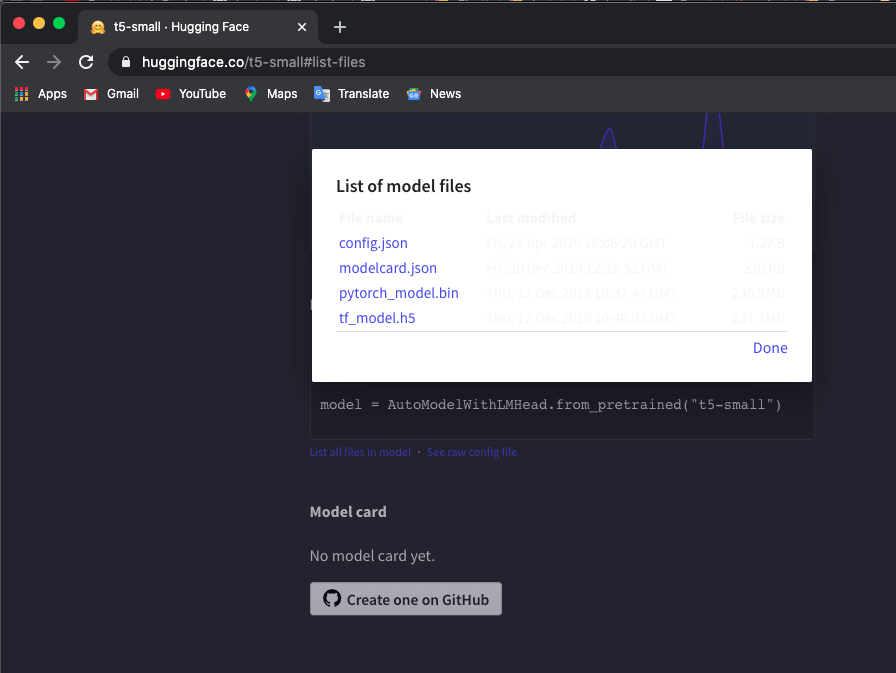
Обратите внимание на структуру каталога загруженных вручную файлов.
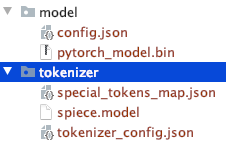
Вы можете использовать другие модели T5 или Bert.
Если вы загружаете другие модели, проверьте список моделей трансформеров Hugaface с предварительной трассировкой, чтобы проверить название модели.
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --build Я также использую docker system prune , чтобы удалить все неиспользуемые контейнеры, сети и изображения, чтобы получить больше памяти. Увеличьте память докера (я использую 8GB ), если вы столкнулись с Container exits with non-zero exit code 137 .
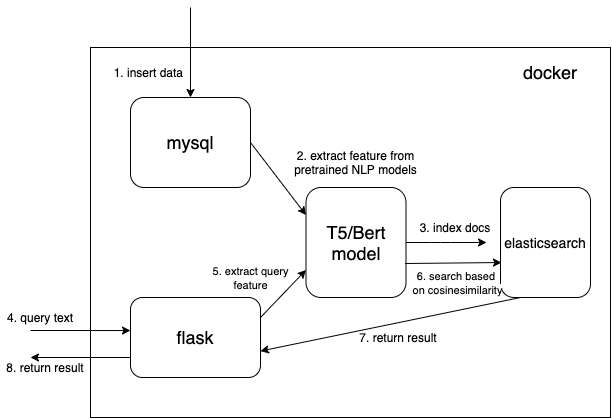
Мы используем тип данных плотного вектора для сохранения извлеченных функций из предварительно обученных моделей НЛП (здесь t5 или bert, но вы можете добавить интересующие вас предварительно обученные модели самостоятельно)
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
} Размеры dims:512 для моделей T5. Измените dims на 768, если вы используете модели Bert.
Прочтите документ из MySQL и преобразуйте документ в правильный формат JSON для последующего использования в elasticsearch.
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'Перейдите по адресу http://127.0.0.1:5000.
Ключевым кодом для использования предварительно обученной модели для извлечения функций является функция get_emb в файлах ./index_files/indexing_files.py и ./web/app.py .
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()Вы можете изменить код и использовать свою любимую предварительно обученную модель. Например, вы можете использовать модель GPT2.
вы также можете настроить свой elasticsearch, используя собственную функцию оценки вместо cosineSimilarity в .webapp.py .
Этот представитель модифицирован на основе Hironsan/bertsearch, которые используют пакеты bert-serving для извлечения функций bert. Это ограничивается TF1.x


