context search engine
1.0.0

Основная цель этого проекта — продемонстрировать возможности векторного поиска путем предоставления удобного интерфейса, который позволяет пользователям выполнять контекстный поиск в корпусе текстовых документов. Используя возможности BERT Hugging Face и FAISS Facebook, мы возвращаем очень релевантные отрывки текста, основанные на семантическом значении запроса пользователя, а не просто на совпадении ключевых слов. Этот проект служит отправной точкой для разработчиков, исследователей и энтузиастов, которые хотят глубже погрузиться в мир контекстуализированного текстового поиска и улучшить свои приложения с помощью современных методов НЛП.
Моя цель — обеспечить понимание векторной базы данных с нуля.
Снимок экрана приложения:
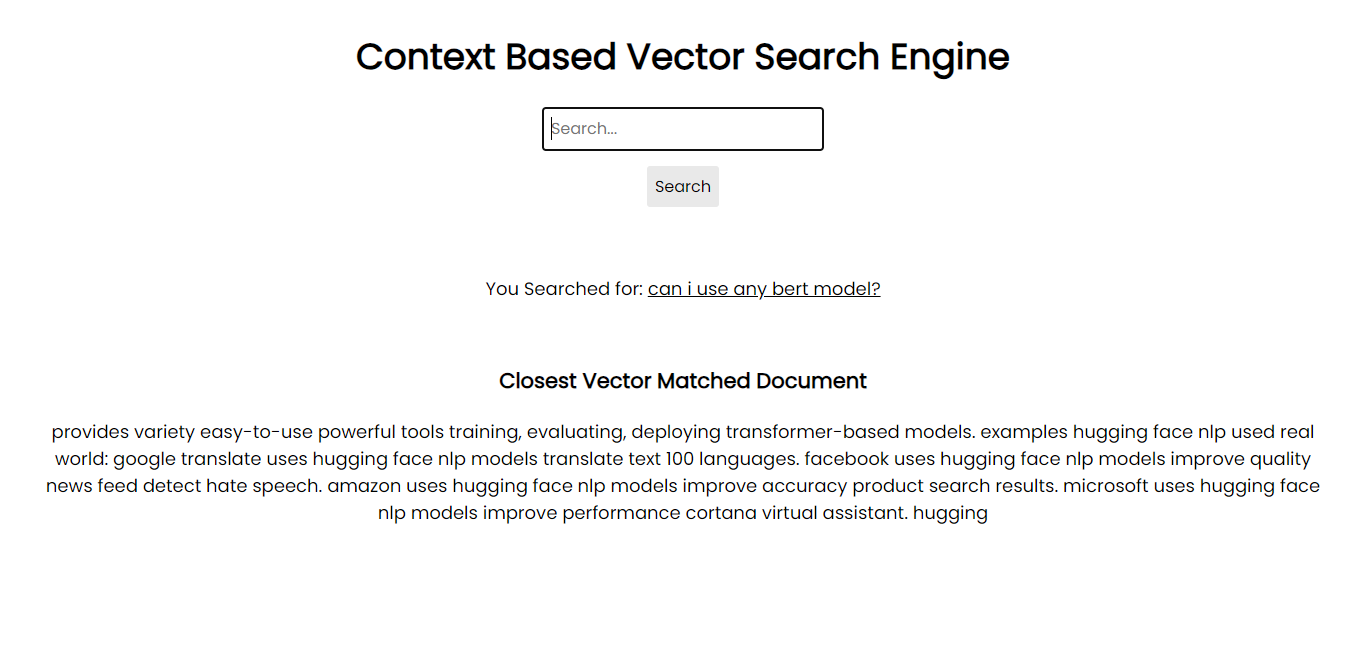
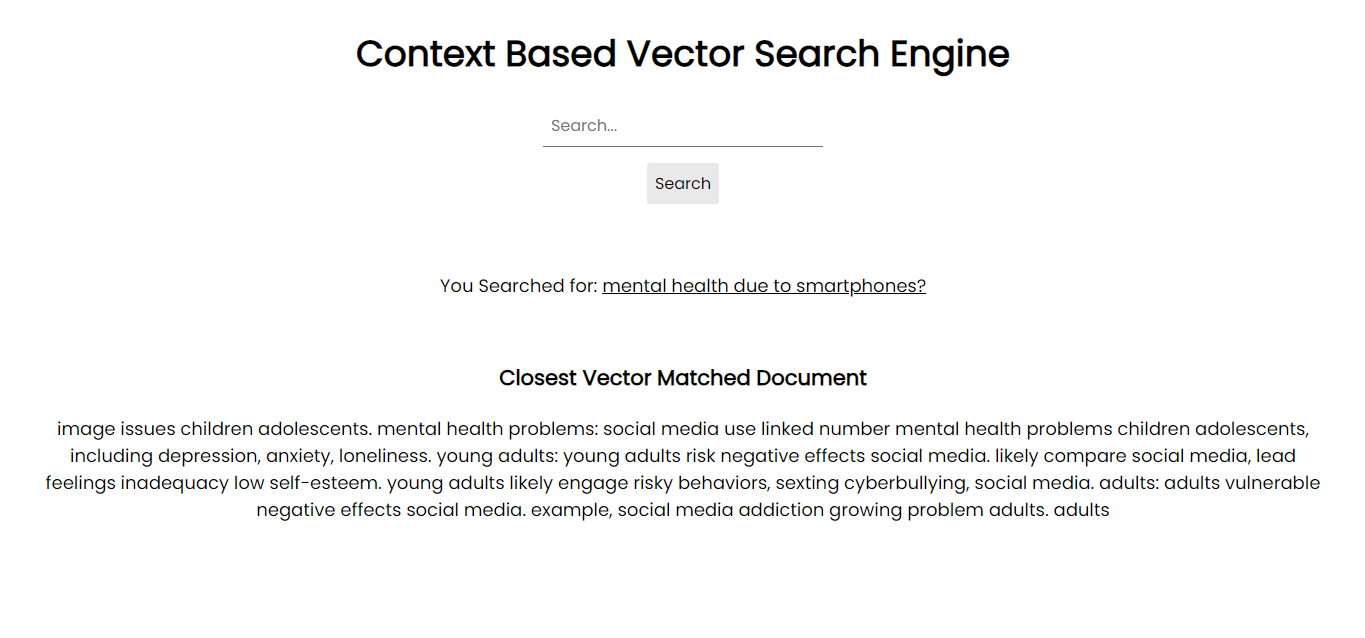
Для запуска в вашей системе вы можете установить все необходимые пакеты через pip, используя файлы требований:
pip install -r requirements.txtК вашему сведению, я использую Python 3.10.1.
Однако, если у вас есть графический процессор, вам будет предложено установить графический процессор FAISS для более быстрой и масштабной интеграции баз данных.
Текущая версия проекта включает в себя:
Хотя проект предлагает функциональную систему контекстного поиска, он спроектирован как модульный, что позволяет потенциально расширять и интегрировать его в более крупные системы или приложения.
В основе этого проекта лежит вера в то, что современные методы НЛП могут предложить гораздо более точные и контекстуально релевантные результаты поиска по сравнению с традиционными методами, основанными на ключевых словах. Вот разбивка нашего подхода:
Исходя из подхода, я разделил проект на 2 раздела:
Раздел 1. Генерация векторных данных с возможностью поиска
В этом разделе мы сначала читаем входные данные из документов, разбиваем их на более мелкие фрагменты, создаем векторы с использованием модели на основе BERT, а затем эффективно сохраняем их с помощью FAISS. Вот блок-схема, которая иллюстрирует то же самое.
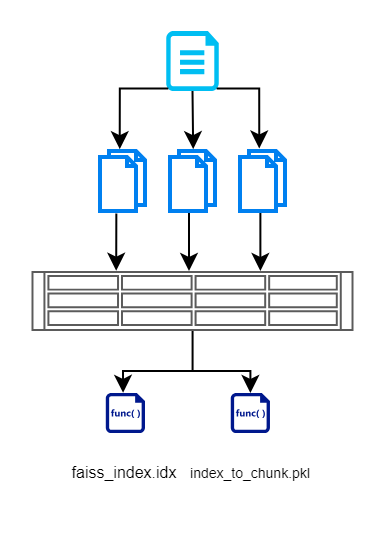
Мы создаем индексный файл FAISS, который содержит векторное представление разбитого на части документа. Мы также храним индекс каждого фрагмента. Это сделано для того, чтобы нам не приходилось снова запрашивать базу данных/документы. Это помогает нам удалить избыточные операции чтения.
Мы выполняем этот раздел, используя create_index.py. Он сгенерирует вышеуказанные 2 файла. Если вам нужно использовать другие модели, вы можете сделать это через HuggingFace Hub?
Примечание. Если вы обнаружите проблемы при настройке гиперпараметра для измерения, проверьте файл config.json модели, чтобы найти подробную информацию об измерении модели, которую вы пытаетесь использовать.
Раздел 2. Создание интерфейса приложения с возможностью поиска
В этом разделе моя цель — создать интерфейс, который позволит пользователям взаимодействовать с документами. Я отдаю предпочтение минималистичному дизайну, не создавая дополнительных препятствий.
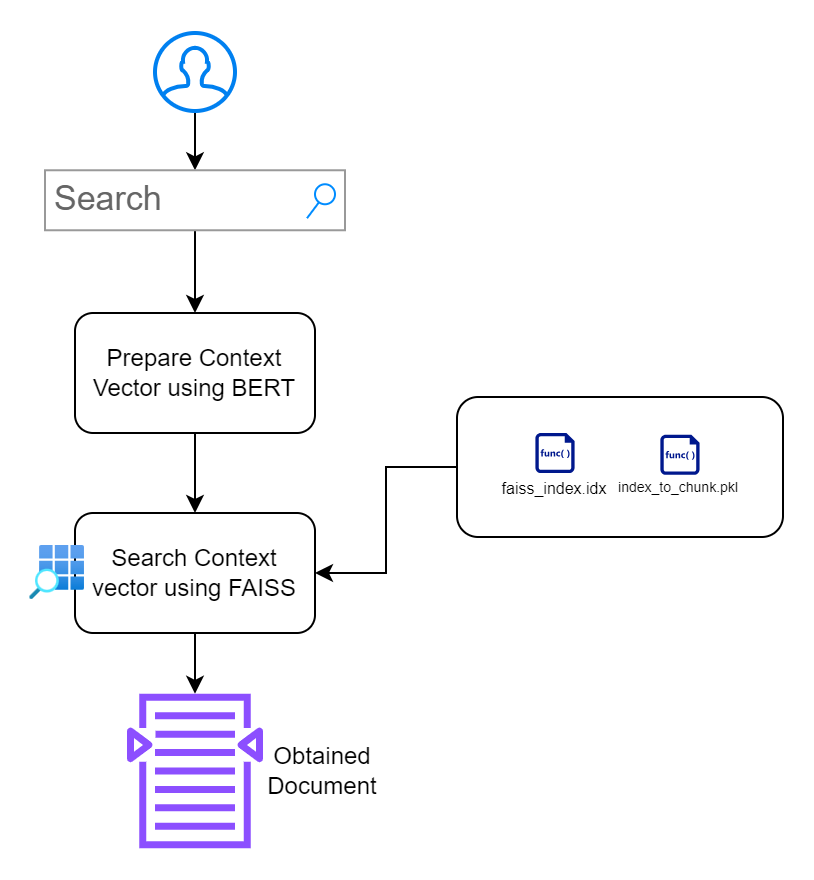
index.html : интерфейсная HTML-страница для ввода поисковых запросов.app.py : приложение Flask, которое обслуживает внешний интерфейс и обрабатывает поисковые запросы.search_engine.py : содержит логику для генерации встраивания, поиска FAISS и выделения ключевых слов. /context_search/
- templates/
- index.html
- static/
- css/
- style.css
- images/
- img1.png
- img2.png
- Approach.png files
- app.py
- search_engine.py
- create_index.py
- index_to_chunk.pkl
- faiss_index.idxfaiss_index.idx ) и сопутствующее сопоставление индекса с текстовым фрагментом ( index_to_chunk.pkl ). python app.py
-- OR --
flask run --host=127.0.0.1 --port=5000
http://localhost:5000 .Всегда есть место для улучшений. Вот некоторые потенциальные улучшения и дополнительные функции, которые можно интегрировать:
Этот проект находится под лицензией MIT. Не стесняйтесь использовать, цитируя, изменяя, распространяя и внося свой вклад. Читать далее.
Если вы заинтересованы в улучшении этого проекта, ваш вклад приветствуется! Пожалуйста, откройте запрос на включение или проблему в этом репозитории. По сути, я отдаю предпочтение вышеуказанным вещам, которые необходимо сделать для улучшения. Другие запросы на включение также будут рассмотрены, но им не будет придаваться приоритета.
Заранее спасибо за ваш интерес. :счастливый: .


