system design primer
1.0.0
Английский ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Добавить перевод
Помогите перевести это руководство!
Научитесь проектировать крупномасштабные системы.
Подготовка к собеседованию по проектированию системы.
Изучение того, как проектировать масштабируемые системы, поможет вам стать лучшим инженером.
Проектирование системы — это обширная тема. В сети разбросано огромное количество ресурсов, посвящённых принципам проектирования систем.
Этот репозиторий представляет собой организованную коллекцию ресурсов, которые помогут вам научиться создавать системы в большом масштабе.
Это постоянно обновляемый проект с открытым исходным кодом.
Вклады приветствуются!
Помимо написания кода собеседования, во многих технологических компаниях обязательным компонентом процесса технического собеседования является проектирование системы.
Отработайте общие вопросы на собеседовании по проектированию системы и сравните свои результаты с примерами решений : обсуждениями, кодом и диаграммами.
Дополнительные темы для подготовки к собеседованию:
В предоставленных колодах карточек Anki используются интервальные повторения, чтобы помочь вам запомнить ключевые концепции проектирования системы.
Отлично подходит для использования в дороге.
Ищете ресурсы, которые помогут вам подготовиться к собеседованию по программированию ?
Ознакомьтесь с родственным репозиторием Interactive Coding Challenges , который содержит дополнительную колоду Anki:
Учитесь у сообщества.
Не стесняйтесь отправлять запросы на вытягивание, чтобы помочь:
Контент, требующий некоторой доработки, находится в разработке.
Ознакомьтесь с Руководством по участию.
Краткое изложение различных тем проектирования систем, включая плюсы и минусы. Все является компромиссом .
Каждый раздел содержит ссылки на более подробные ресурсы.
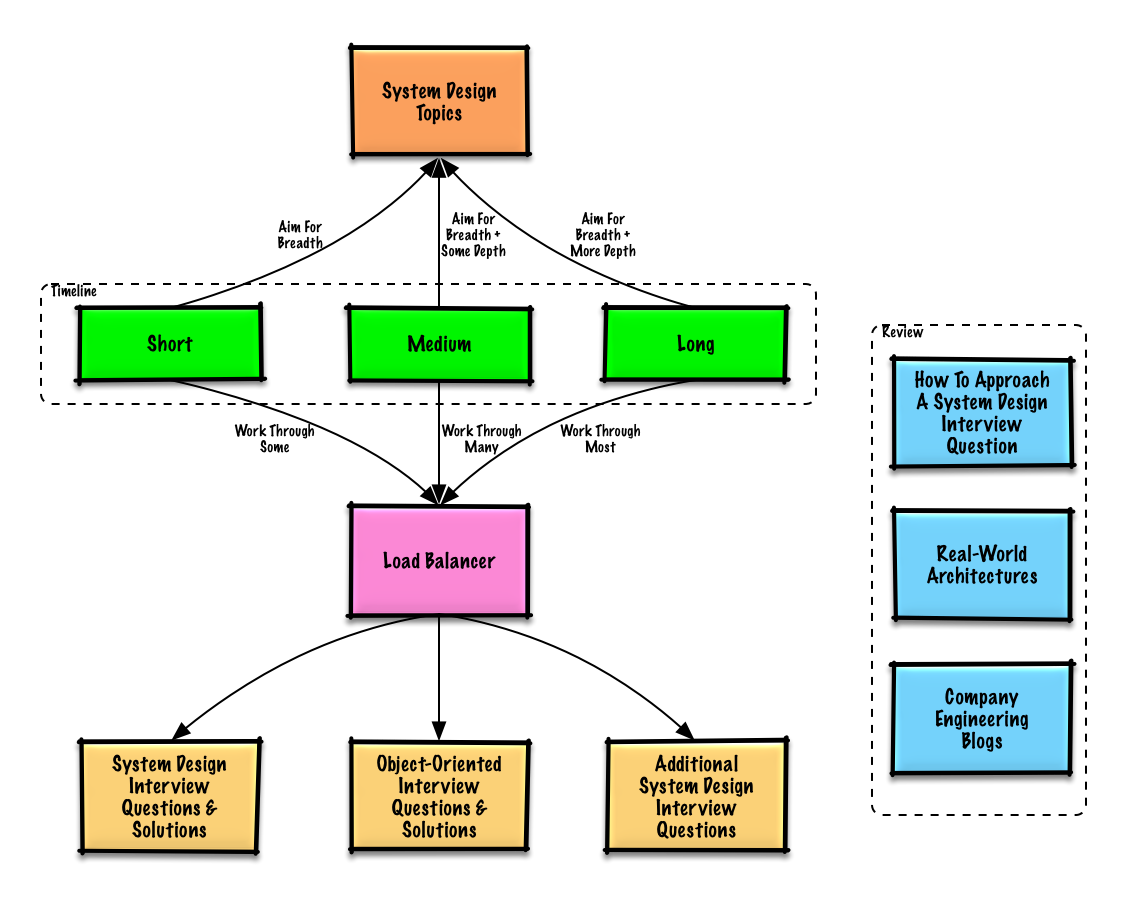
Рекомендуемые темы для рассмотрения в зависимости от графика вашего собеседования (короткое, среднее, длинное).
Вопрос: Для интервью мне нужно знать здесь все?
О: Нет, здесь не обязательно знать все, чтобы подготовиться к собеседованию .
То, что вас спрашивают на собеседовании, зависит от таких переменных, как:
Обычно ожидается, что более опытные кандидаты будут знать больше о проектировании систем. Можно ожидать, что архитекторы или руководители групп знают больше, чем отдельные участники. Ведущие технологические компании, скорее всего, проведут один или несколько раундов дизайнерских собеседований.
Начните с широкого и идите глубже в нескольких областях. Это поможет вам немного узнать о различных ключевых темах проектирования систем. Скорректируйте следующее руководство в зависимости от вашего графика, опыта, на какие должности вы проходите собеседование и в какие компании вы проходите собеседование.
| Короткий | Середина | Длинный | |
|---|---|---|---|
| Прочтите разделы по проектированию систем, чтобы получить общее представление о том, как работают системы. | ? | ? | ? |
| Прочтите несколько статей в инженерных блогах компаний, у которых вы берете интервью. | ? | ? | ? |
| Прочтите несколько реальных архитектур. | ? | ? | ? |
| Обзор Как подойти к вопросу собеседования по проектированию системы | ? | ? | ? |
| Проработайте вопросы собеседования по проектированию системы с решениями | Некоторый | Много | Большинство |
| Проработайте вопросы собеседования по объектно-ориентированному дизайну с решениями | Некоторый | Много | Большинство |
| Обзор дополнительных вопросов для собеседования по проектированию системы | Некоторый | Много | Большинство |
Как ответить на вопрос на собеседовании по проектированию системы.
Собеседование по проектированию системы — это открытый разговор . Ожидается, что вы возглавите его.
Вы можете использовать следующие шаги для направления обсуждения. Чтобы закрепить этот процесс, проработайте раздел «Вопросы для собеседования по проектированию системы и решения», выполнив следующие действия.
Соберите требования и определите масштаб проблемы. Задавайте вопросы, чтобы прояснить варианты использования и ограничения. Обсудите предположения.
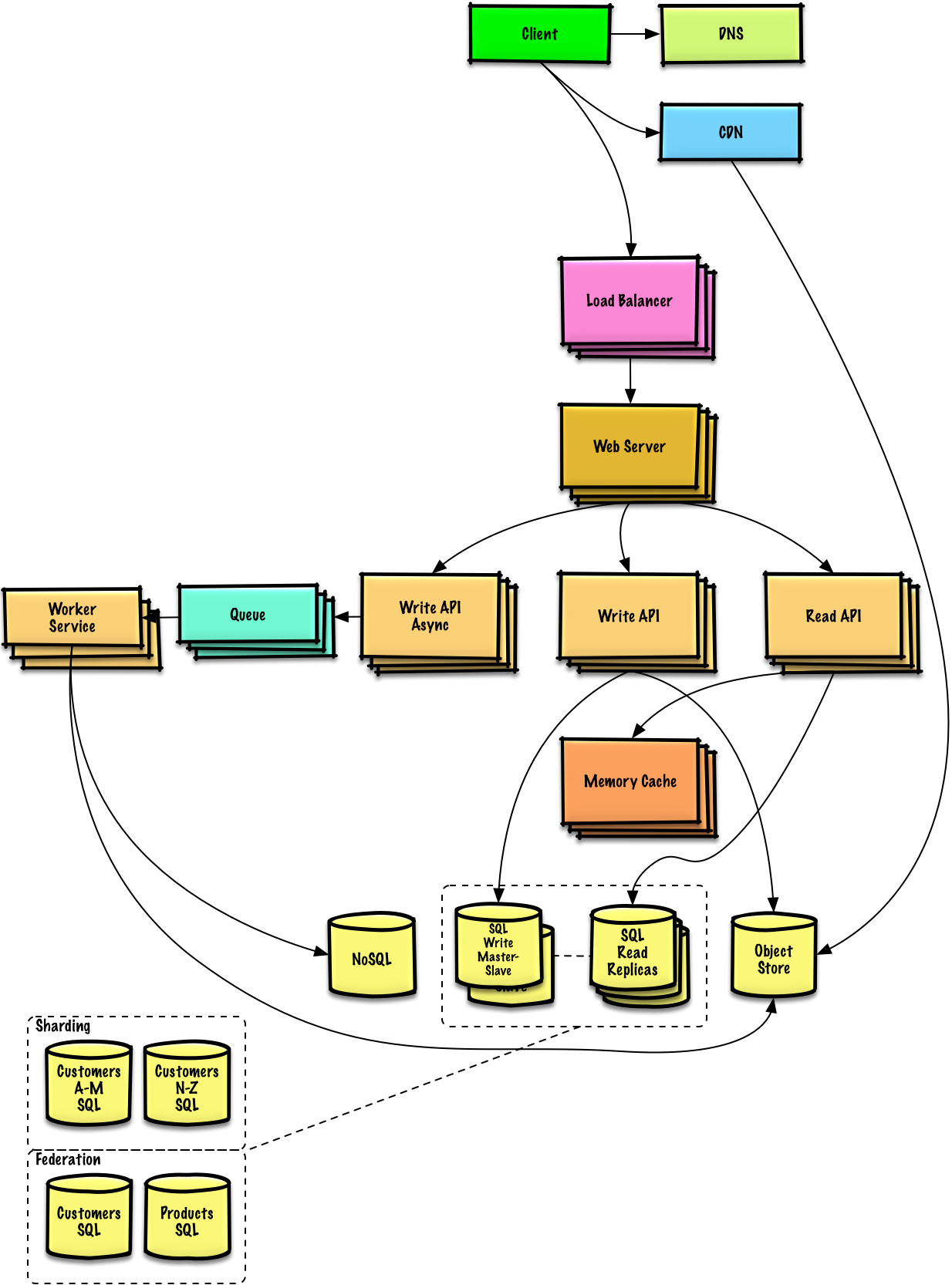
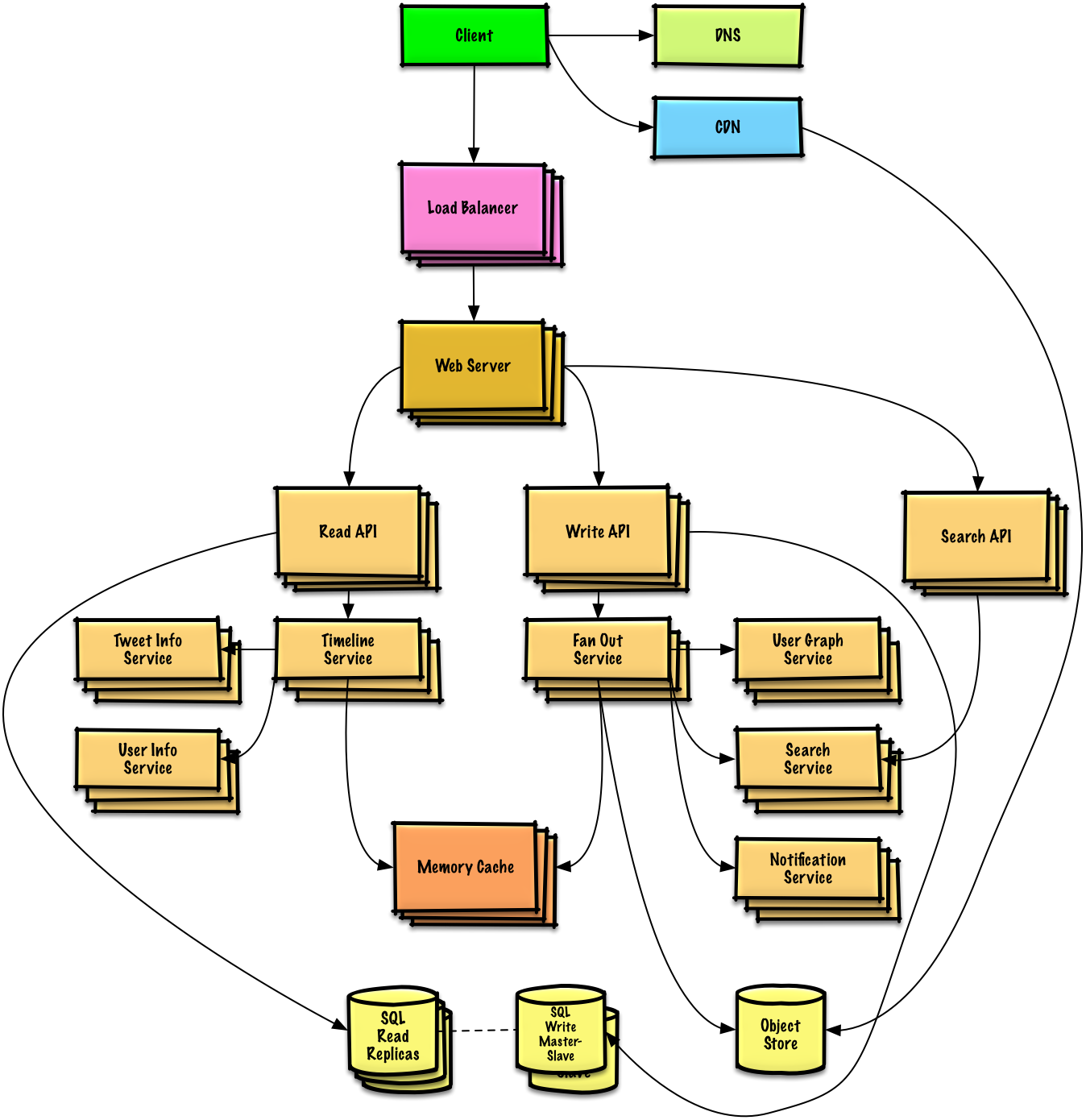
Набросайте высокоуровневый проект со всеми важными компонентами.
Подробное описание каждого основного компонента. Например, если вас попросили разработать службу сокращения URL-адресов, обсудите:
Выявляйте и устраняйте узкие места с учетом ограничений. Например, нужно ли вам следующее для решения проблем масштабируемости?
Обсудите потенциальные решения и компромиссы. Все является компромиссом. Устраняйте узкие места, используя принципы проектирования масштабируемых систем.
Вас могут попросить сделать некоторые оценки вручную. В приложении вы найдете следующие ресурсы:
Ознакомьтесь со следующими ссылками, чтобы лучше понять, чего ожидать:
Общие вопросы для собеседования по проектированию системы с примерами обсуждений, кодом и диаграммами.
Решения связаны с содержимым в папке
solutions/.
| Вопрос | |
|---|---|
| Создайте Pastebin.com (или Bit.ly) | Решение |
| Создайте ленту и поиск в Twitter (или ленту и поиск в Facebook) | Решение |
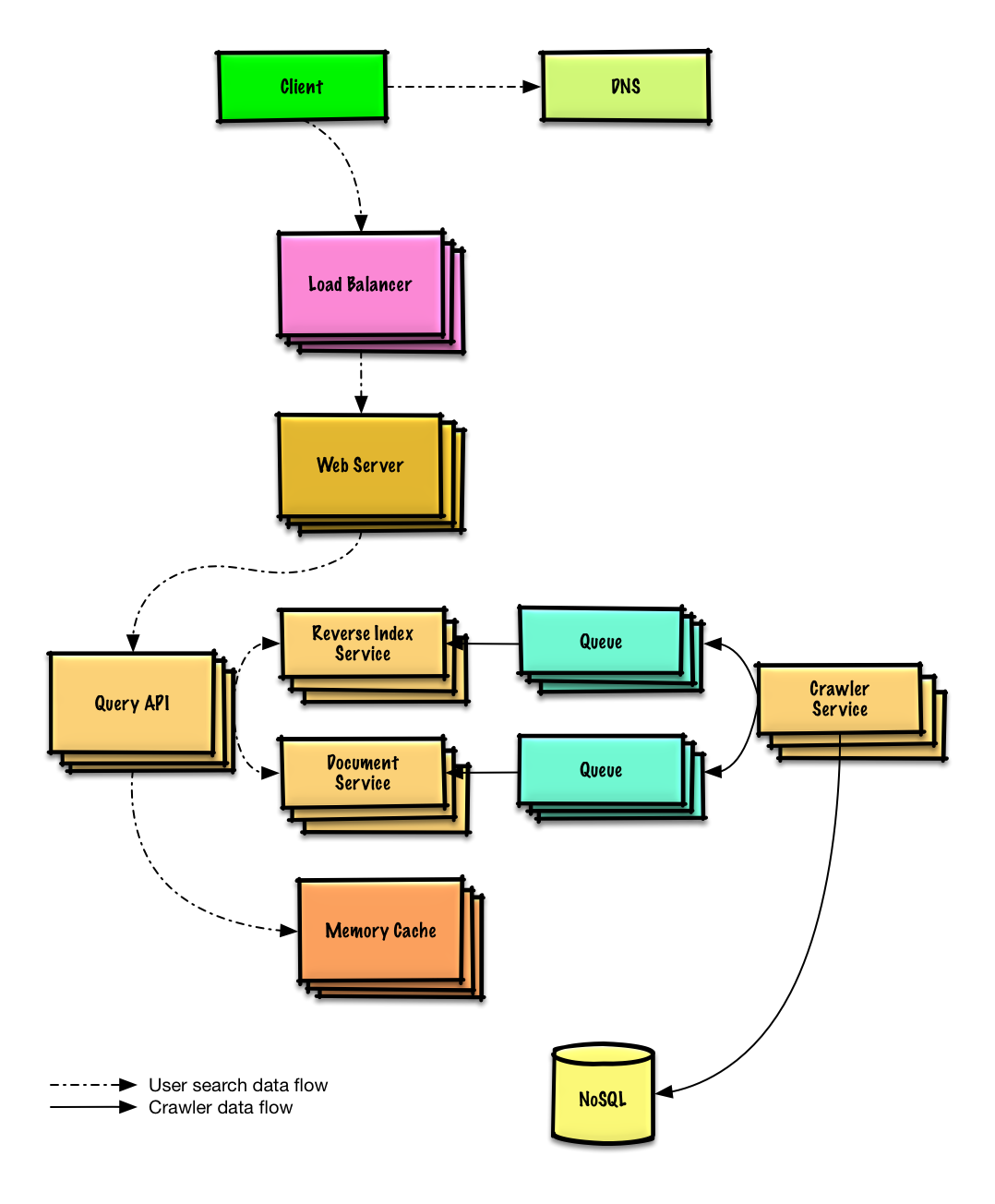
| Разработка веб-сканера | Решение |
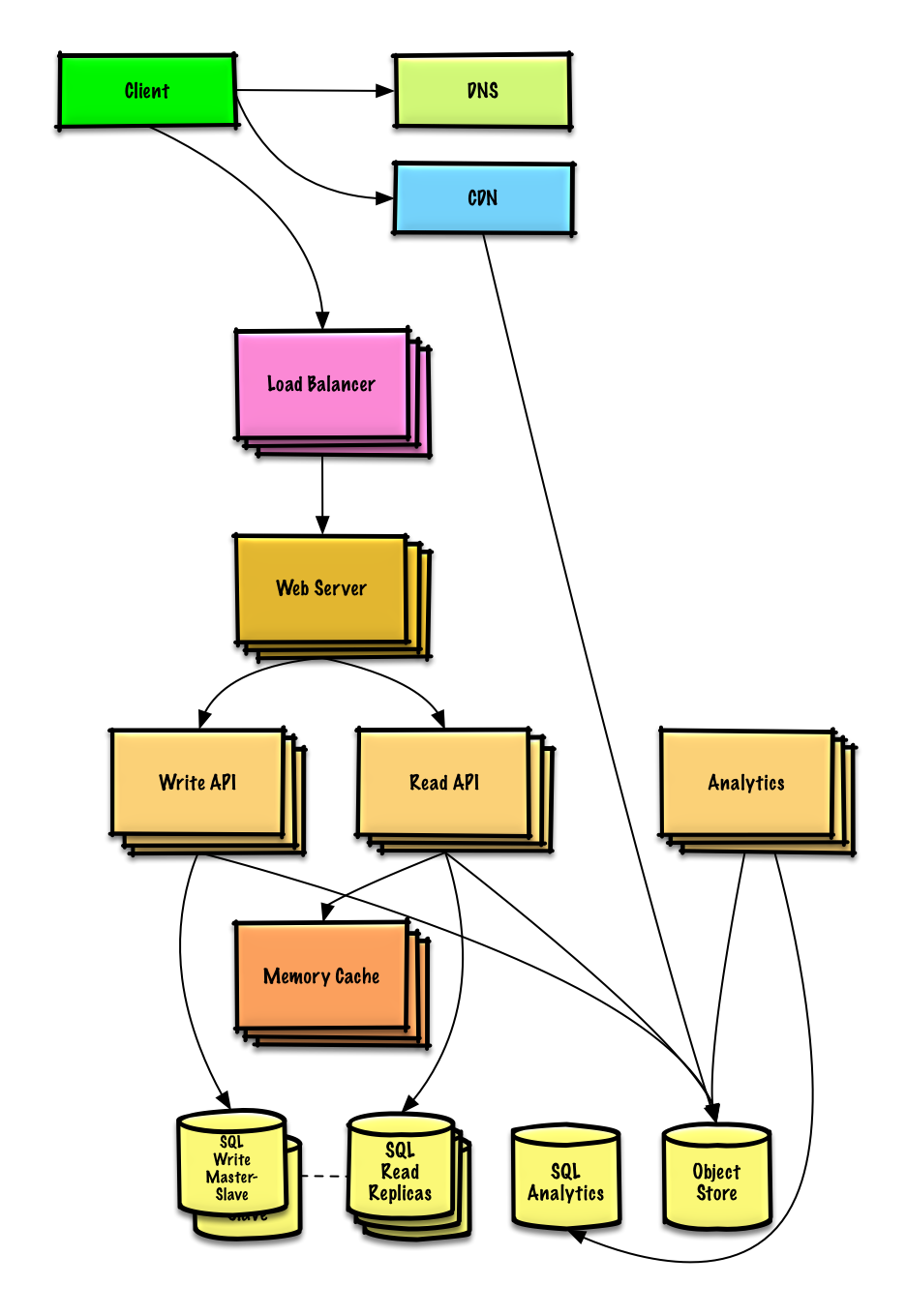
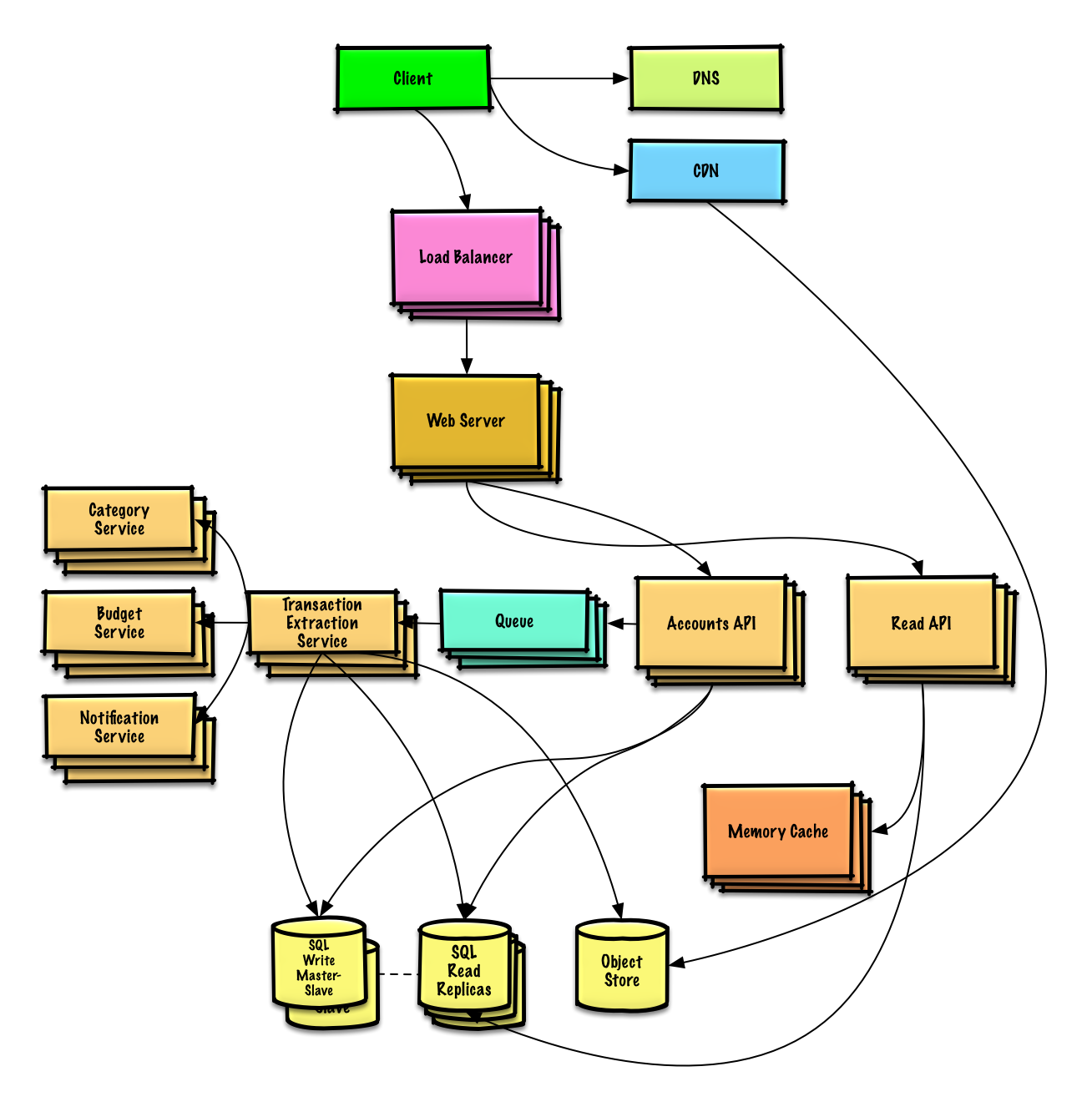
| Дизайн Mint.com | Решение |
| Проектирование структур данных для социальной сети | Решение |
| Создайте хранилище ключей-значений для поисковой системы. | Решение |
| Создайте рейтинг продаж Amazon по категориям | Решение |
| Создайте систему, которая масштабируется для миллионов пользователей AWS. | Решение |
| Добавить вопрос по проектированию системы | Способствовать |
Посмотреть упражнение и решение
Посмотреть упражнение и решение
Посмотреть упражнение и решение
Посмотреть упражнение и решение
Посмотреть упражнение и решение
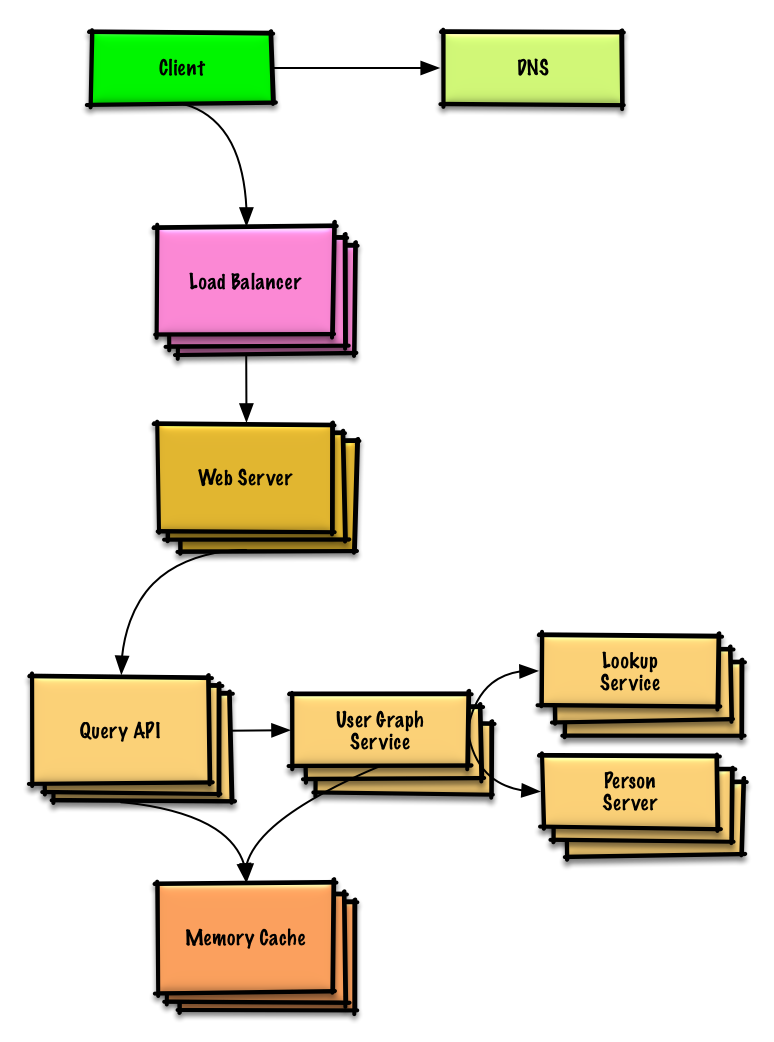
Посмотреть упражнение и решение
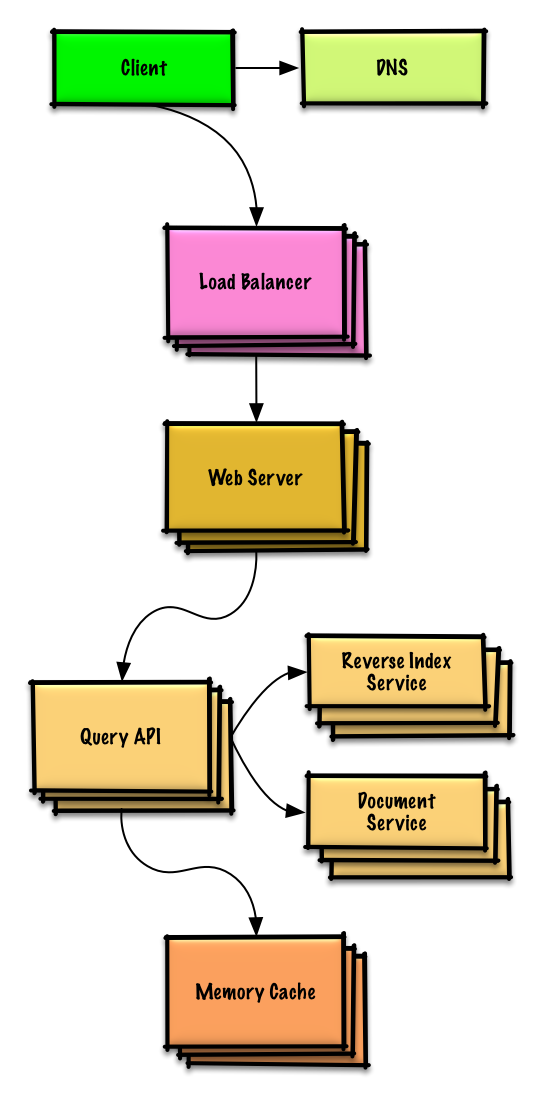
Посмотреть упражнение и решение
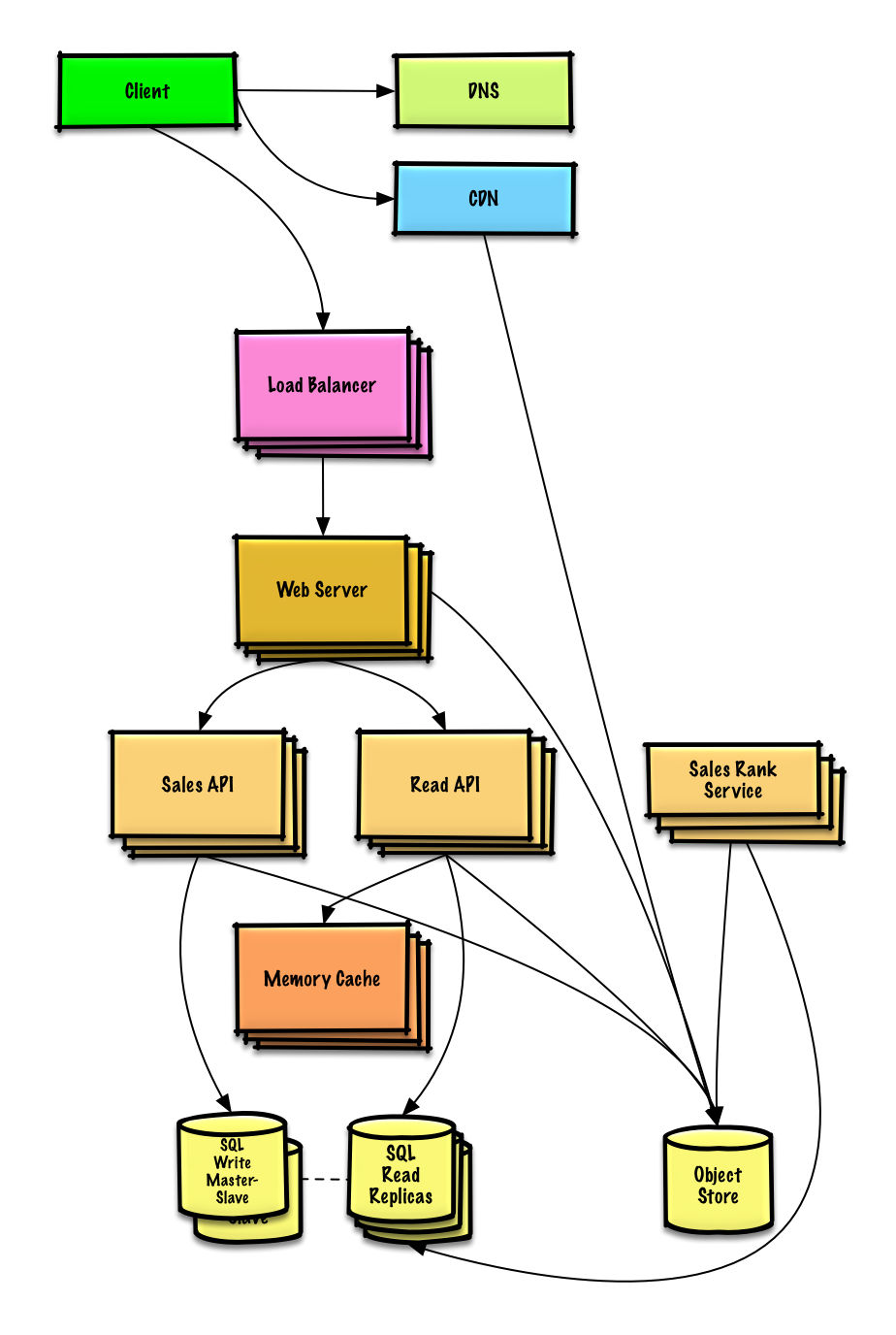
Посмотреть упражнение и решение
Общие вопросы для собеседований по объектно-ориентированному дизайну с примерами обсуждений, кодом и диаграммами.
Решения связаны с содержимым в папке
solutions/.
Примечание: данный раздел находится в разработке.
| Вопрос | |
|---|---|
| Создайте хеш-карту | Решение |
| Создайте кэш, который использовался реже всего | Решение |
| Спроектировать колл-центр | Решение |
| Создайте колоду карт | Решение |
| Спроектировать парковку | Решение |
| Спроектировать чат-сервер | Решение |
| Создайте круговой массив | Способствовать |
| Добавьте вопрос об объектно-ориентированном дизайне | Способствовать |
Новичок в проектировании систем?
Во-первых, вам понадобится базовое понимание общих принципов, изучение того, что они собой представляют, как они используются, а также их плюсы и минусы.
Лекция по масштабируемости в Гарварде
Масштабируемость
Далее мы рассмотрим компромиссы высокого уровня:
Имейте в виду, что все является компромиссом .
Затем мы углубимся в более конкретные темы, такие как DNS, CDN и балансировщики нагрузки.
Услуга является масштабируемой , если она приводит к повышению производительности пропорционально добавленным ресурсам. Как правило, повышение производительности означает обслуживание большего количества единиц работы, но это также может означать обработку более крупных единиц работы, например, при росте наборов данных. 1
Другой способ взглянуть на производительность и масштабируемость:
Задержка — это время для выполнения какого-либо действия или получения какого-либо результата.
Пропускная способность — это количество таких действий или результатов в единицу времени.
Как правило, вам следует стремиться к максимальной пропускной способности с приемлемой задержкой .
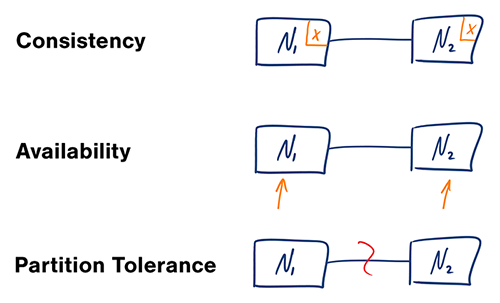
Источник: пересмотр теоремы CAP.
В распределенной компьютерной системе можно поддерживать только две из следующих гарантий:
Сети ненадежны, поэтому вам необходимо поддерживать толерантность к разделам. Вам придется найти программный компромисс между согласованностью и доступностью.
Ожидание ответа от секционированного узла может привести к ошибке тайм-аута. CP — хороший выбор, если потребности вашего бизнеса требуют атомарного чтения и записи.
Ответы возвращают наиболее доступную версию данных, доступную на любом узле, которая может быть не самой последней. Распространение записи может занять некоторое время после разрешения раздела.
AP — хороший выбор, если бизнесу необходимо обеспечить конечную согласованность или когда системе необходимо продолжать работу, несмотря на внешние ошибки.
Имея несколько копий одних и тех же данных, мы сталкиваемся с вариантами их синхронизации, чтобы клиенты имели единообразное представление данных. Вспомните определение согласованности из теоремы CAP: каждое чтение получает самую последнюю запись или ошибку.
После записи чтение может видеть или не видеть его. Применяется подход с максимальными усилиями.
Этот подход наблюдается в таких системах, как memcached. Слабая согласованность хорошо работает в случаях использования в реальном времени, таких как VoIP, видеочат и многопользовательские игры в реальном времени. Например, если вы разговариваете по телефону и теряете прием на несколько секунд, при восстановлении соединения вы не слышите то, что говорили во время потери соединения.
После записи операции чтения в конечном итоге увидят его (обычно в течение миллисекунд). Данные реплицируются асинхронно.
Такой подход наблюдается в таких системах, как DNS и электронная почта. Окончательная согласованность хорошо работает в системах с высокой доступностью.
После записи чтение увидит это. Данные реплицируются синхронно.
Этот подход наблюдается в файловых системах и СУБД. Строгая согласованность хорошо работает в системах, которым необходимы транзакции.
Существует два взаимодополняющих шаблона для поддержки высокой доступности: отработка отказа и репликация .
При переходе на резервный режим «активный-пассивный» контрольные сигналы передаются между активным и пассивным сервером в режиме ожидания. Если тактовый сигнал прерывается, пассивный сервер принимает IP-адрес активного и возобновляет обслуживание.
Продолжительность простоя определяется тем, работает ли пассивный сервер уже в режиме «горячего» резерва или ему необходимо запуститься из «холодного» резерва. Трафик обрабатывается только активным сервером.
Активно-пассивное переключение при отказе также можно назвать переключением «главный-подчиненный».
В режиме «активный-активный» оба сервера управляют трафиком, распределяя нагрузку между собой.
Если серверы являются общедоступными, DNS необходимо будет знать общедоступные IP-адреса обоих серверов. Если серверы являются внутренними, логика приложения должна знать об обоих серверах.
Переключение «активный-активный» также можно назвать переключением «главный-главный».
Подробнее эта тема обсуждается в разделе «База данных»:
Доступность часто измеряется временем безотказной работы (или временем простоя) в процентах от времени доступности услуги. Доступность обычно измеряется количеством девяток: услуга с доступностью 99,99% описывается как имеющая четыре девятки.
| Продолжительность | Приемлемое время простоя |
|---|---|
| Время простоя в год | 8 часов 45 минут 57 секунд |
| Время простоя в месяц | 43 минуты 49,7 секунды |
| Время простоя в неделю | 10 м 4,8 с |
| Время простоя в день | 1м 26,4с |
| Продолжительность | Приемлемое время простоя |
|---|---|
| Время простоя в год | 52 минуты 35,7 секунды |
| Время простоя в месяц | 4 минуты 23 секунды |
| Время простоя в неделю | 1м 5с |
| Время простоя в день | 8,6 с |
Если служба состоит из нескольких компонентов, подверженных сбоям, общая доступность службы зависит от того, расположены ли компоненты последовательно или параллельно.
Общая доступность снижается, если два компонента с доступностью < 100 % расположены последовательно:
Availability (Total) = Availability (Foo) * Availability (Bar)
Если бы и Foo , и Bar имели доступность по 99,9%, их общая доступность по порядку составила бы 99,8%.
Общая доступность увеличивается, когда два компонента с доступностью < 100 % работают параллельно:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
Если бы и Foo , и Bar имели доступность по 99,9%, их общая доступность при параллельном использовании составила бы 99,9999%.
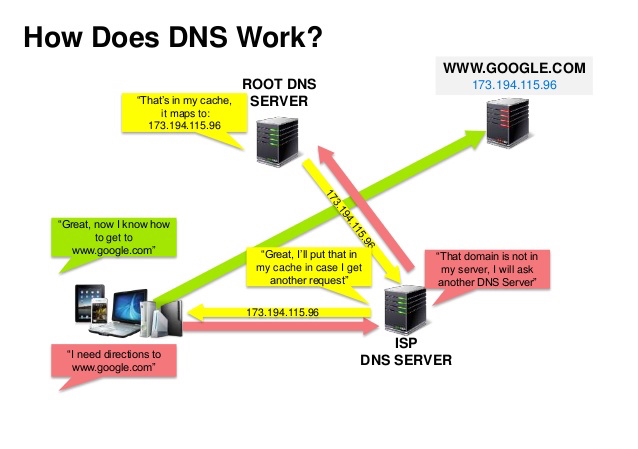
Источник: презентация безопасности DNS.
Система доменных имен (DNS) преобразует доменное имя, например www.example.com, в IP-адрес.
DNS имеет иерархическую структуру с несколькими авторитетными серверами на верхнем уровне. Ваш маршрутизатор или интернет-провайдер предоставляет информацию о том, к какому DNS-серверу(ам) обращаться при поиске. Сопоставления кэша DNS-серверов нижнего уровня, которые могут устареть из-за задержек распространения DNS. Результаты DNS также могут кэшироваться вашим браузером или ОС в течение определенного периода времени, определяемого временем жизни (TTL).
CNAME (от example.com до www.example.com) или на запись AТакие службы, как CloudFlare и Route 53, предоставляют управляемые службы DNS. Некоторые службы DNS могут маршрутизировать трафик различными способами:
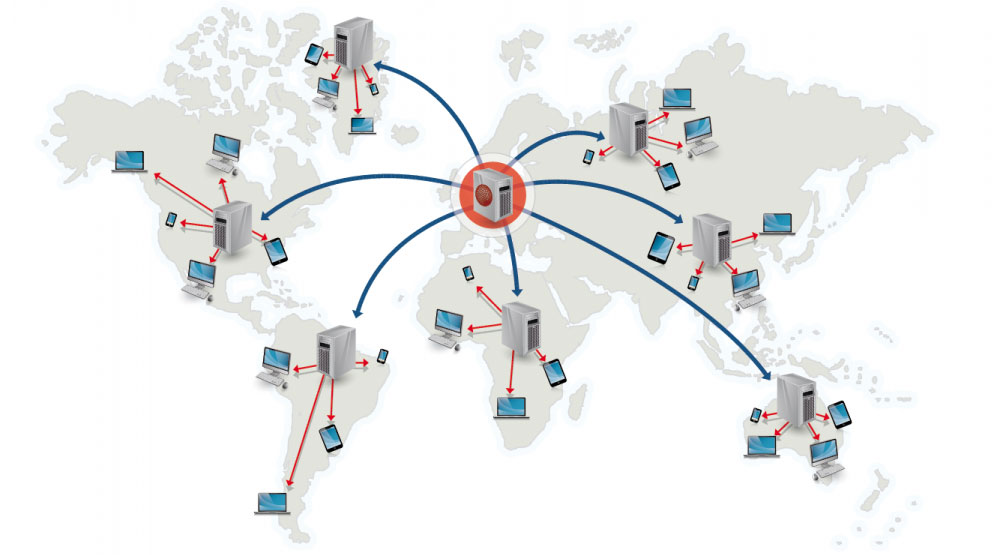
Источник: Зачем использовать CDN
Сеть доставки контента (CDN) — это глобально распределенная сеть прокси-серверов, обслуживающая контент из мест, более близких к пользователю. Обычно статические файлы, такие как HTML/CSS/JS, фотографии и видео, передаются из CDN, хотя некоторые CDN, такие как CloudFront от Amazon, поддерживают динамический контент. Разрешение DNS сайта сообщит клиентам, к какому серверу обращаться.
Обслуживание контента из CDN может значительно повысить производительность двумя способами:
Push CDN получают новый контент всякий раз, когда на вашем сервере происходят изменения. Вы берете на себя полную ответственность за предоставление контента, загрузку непосредственно в CDN и переписывание URL-адресов, чтобы они указывали на CDN. Вы можете настроить время истечения срока действия контента и время его обновления. Контент загружается только в том случае, если он новый или изменен, что позволяет минимизировать трафик, но максимально увеличить объем хранилища.
Сайты с небольшим объемом трафика или сайты с контентом, который не часто обновляется, хорошо работают с push-CDN. Контент размещается в CDN один раз, а не повторно извлекается через регулярные промежутки времени.
Pull CDN захватывают новый контент с вашего сервера, когда первый пользователь запрашивает контент. Вы оставляете контент на своем сервере и переписываете URL-адреса, чтобы они указывали на CDN. Это приводит к более медленному запросу, пока контент не будет кэширован в CDN.
Время жизни (TTL) определяет, как долго содержимое кэшируется. Pull CDN минимизируют пространство для хранения в CDN, но могут создать избыточный трафик, если срок действия файлов истекает и они извлекаются до того, как они фактически изменились.
Сайты с интенсивным трафиком хорошо работают с CDN по запросу, поскольку трафик распределяется более равномерно, и в CDN остается только недавно запрошенный контент.
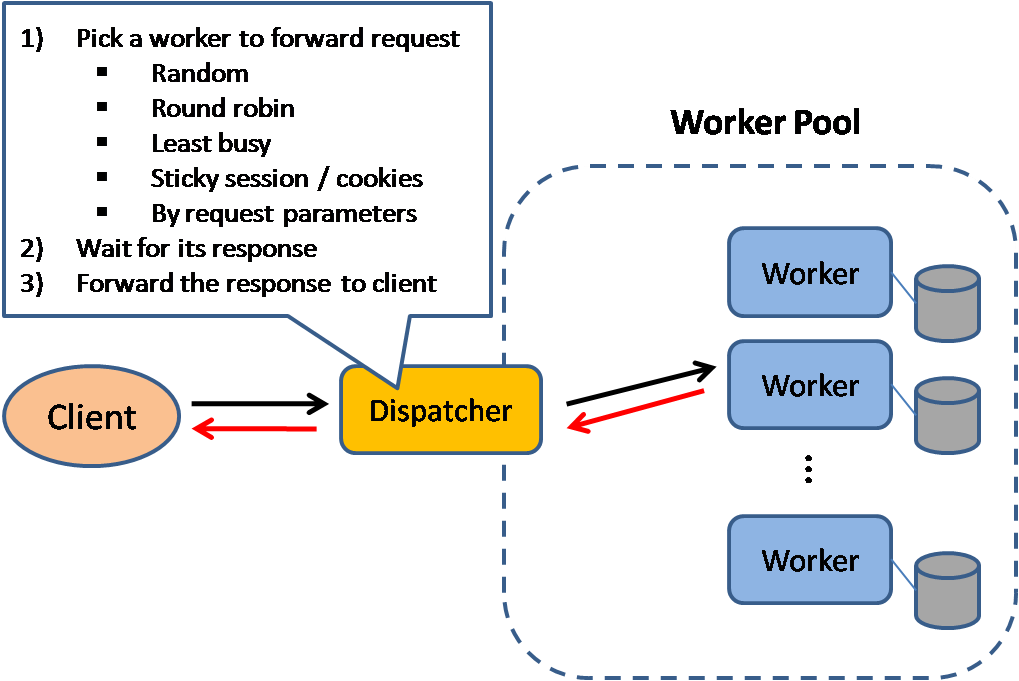
Источник: Шаблоны проектирования масштабируемых систем.
Балансировщики нагрузки распределяют входящие клиентские запросы по вычислительным ресурсам, таким как серверы приложений и базы данных. В каждом случае балансировщик нагрузки возвращает ответ вычислительного ресурса соответствующему клиенту. Балансировщики нагрузки эффективны при:
Балансировщики нагрузки могут быть реализованы с помощью аппаратного обеспечения (дорогостоящего) или программного обеспечения, такого как HAProxy.
Дополнительные преимущества включают в себя:
Для защиты от сбоев обычно настраивают несколько балансировщиков нагрузки либо в активно-пассивном, либо в активно-активном режиме.
Балансировщики нагрузки могут маршрутизировать трафик на основе различных показателей, в том числе:
Балансировщики нагрузки уровня 4 анализируют информацию на транспортном уровне, чтобы решить, как распределять запросы. Обычно это касается IP-адресов источника, назначения и портов в заголовке, но не содержимого пакета. Балансировщики нагрузки уровня 4 перенаправляют сетевые пакеты на вышестоящий сервер и обратно, выполняя преобразование сетевых адресов (NAT).
Балансировщики нагрузки уровня 7 анализируют уровень приложений, чтобы решить, как распределять запросы. Это может включать содержимое заголовка, сообщения и файлов cookie. Балансировщики нагрузки уровня 7 завершают сетевой трафик, считывают сообщение, принимают решение о балансировке нагрузки, а затем открывают соединение с выбранным сервером. Например, балансировщик нагрузки уровня 7 может направлять видеотрафик на серверы, на которых размещается видео, одновременно направляя более конфиденциальный пользовательский трафик на серверы с усиленной безопасностью.
За счет гибкости балансировка нагрузки уровня 4 требует меньше времени и вычислительных ресурсов, чем уровень 7, хотя влияние на производительность может быть минимальным на современном стандартном оборудовании.
Балансировщики нагрузки также могут помочь в горизонтальном масштабировании, повышая производительность и доступность. Масштабирование с использованием обычных компьютеров более экономично и обеспечивает более высокую доступность, чем масштабирование одного сервера на более дорогом оборудовании, называемое вертикальным масштабированием . Кроме того, легче нанять специалистов, работающих с обычным оборудованием, чем со специализированными корпоративными системами.
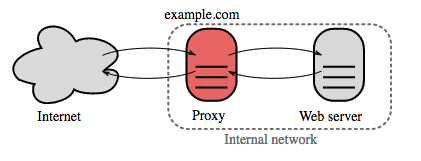
Источник: Википедия
Обратный прокси — это веб-сервер, который централизует внутренние службы и предоставляет общедоступные унифицированные интерфейсы. Запросы от клиентов пересылаются на сервер, который может их выполнить, прежде чем обратный прокси-сервер вернет ответ сервера клиенту.
Дополнительные преимущества включают в себя:
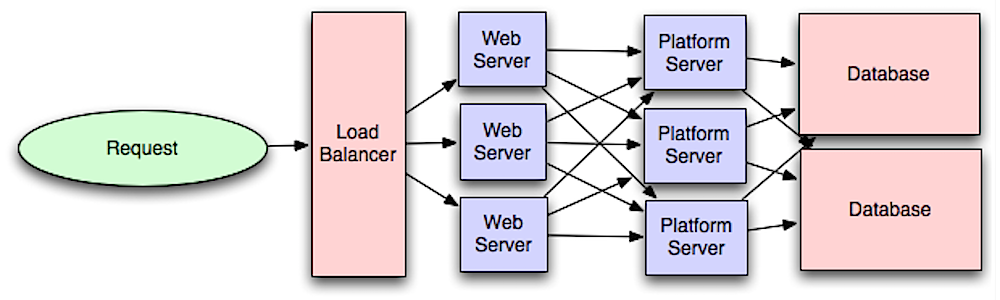
Источник: Введение в проектирование систем для масштабирования.
Отделение веб-уровня от уровня приложения (также известного как уровень платформы) позволяет масштабировать и настраивать оба уровня независимо. Добавление нового API приводит к добавлению серверов приложений без необходимости добавления дополнительных веб-серверов. Принцип единой ответственности выступает за небольшие и автономные службы, работающие вместе. Небольшие команды с небольшими службами могут более агрессивно планировать быстрый рост.
Работники уровня приложения также помогают обеспечить асинхронность.
К этому обсуждению относятся микросервисы, которые можно описать как набор независимо развертываемых небольших модульных сервисов. Каждая служба запускает уникальный процесс и взаимодействует через четко определенный и легкий механизм для достижения бизнес-цели. 1
Например, Pinterest может иметь следующие микросервисы: профиль пользователя, подписчик, лента, поиск, загрузка фотографий и т. д.
Такие системы, как Consul, Etcd и Zookeeper, могут помочь сервисам находить друг друга, отслеживая зарегистрированные имена, адреса и порты. Проверки работоспособности помогают проверить целостность службы и часто выполняются с использованием конечной точки HTTP. И Consul, и Etcd имеют встроенное хранилище значений ключей, которое может быть полезно для хранения значений конфигурации и других общих данных.
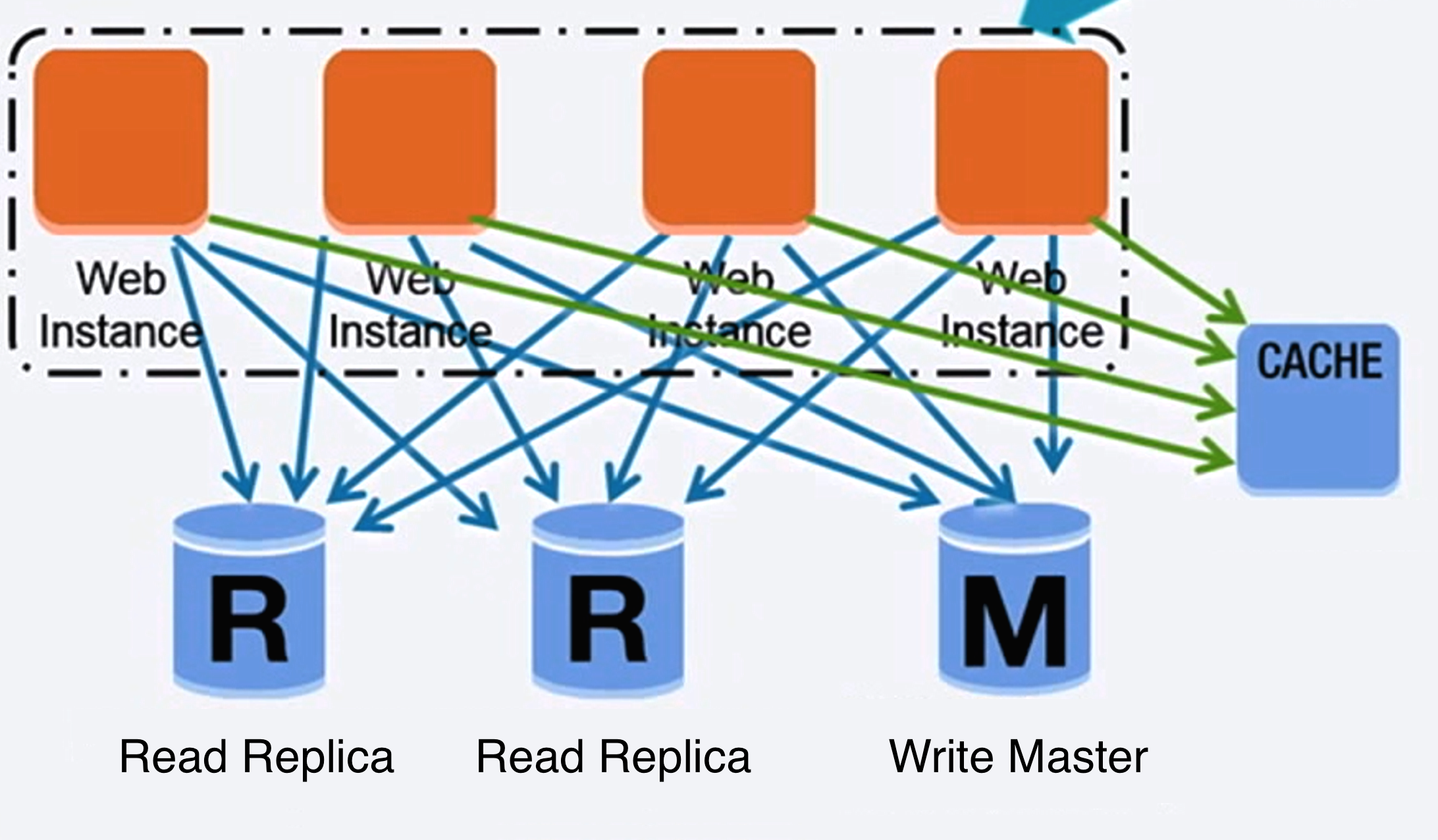
Источник: Увеличение числа первых 10 миллионов пользователей.
Реляционная база данных, такая как SQL, представляет собой набор элементов данных, организованных в таблицах.
ACID — это набор свойств транзакций реляционной базы данных.
Существует множество методов масштабирования реляционной базы данных: репликация master-slave , репликация master-master , федерация , сегментирование , денормализация и настройка SQL .
Главный обслуживает операции чтения и записи, дублируя записи одному или нескольким ведомым устройствам, которые обслуживают только чтение. Подчиненные устройства также могут реплицироваться к дополнительным подчиненным устройствам в древовидном порядке. Если ведущее устройство отключается от сети, система может продолжать работать в режиме только для чтения до тех пор, пока ведомое устройство не будет повышено до уровня ведущего или не будет предоставлен новый ведущий.
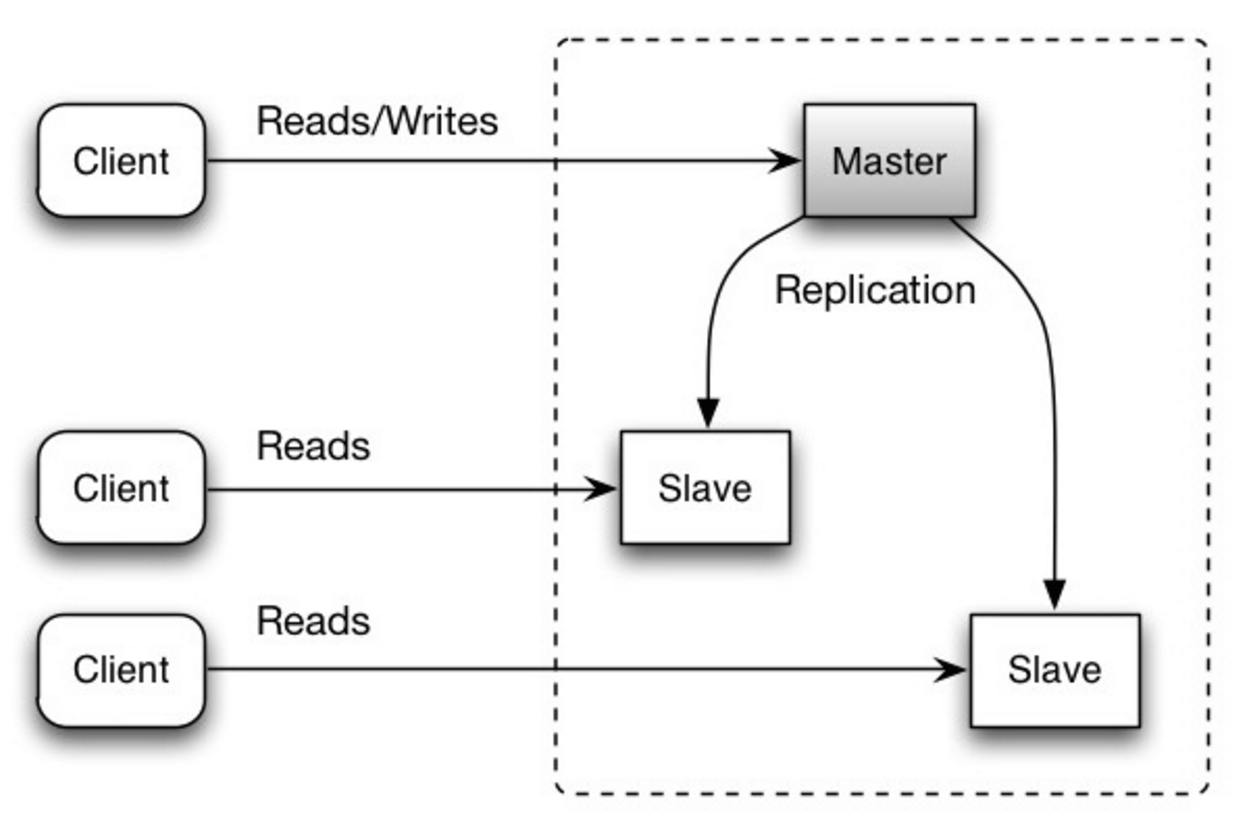
Источник: Масштабируемость, доступность, стабильность, шаблоны.
Оба мастера обслуживают операции чтения и записи и координируют операции записи друг с другом. Если один из главных устройств выходит из строя, система может продолжать работать как с чтением, так и с записью.
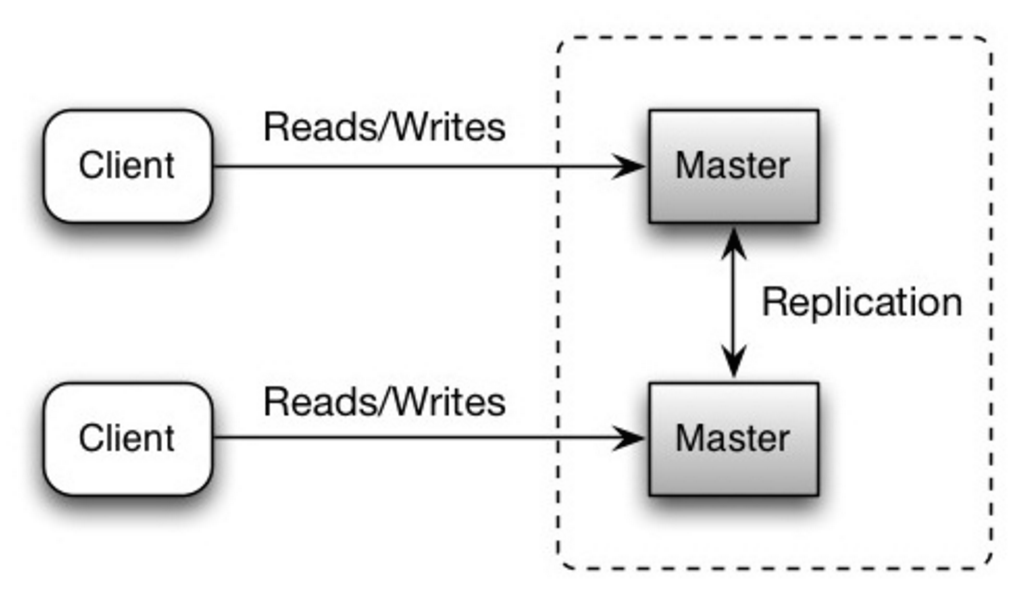
Источник: Масштабируемость, доступность, стабильность, шаблоны.
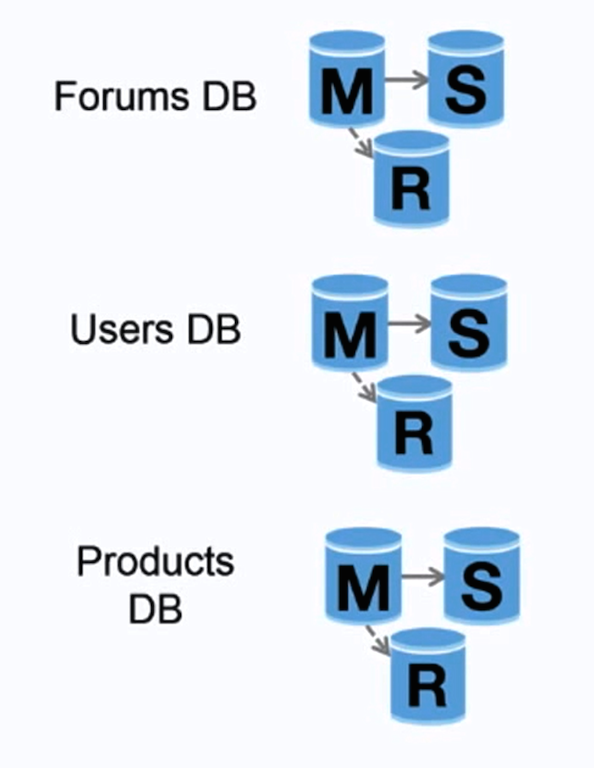
Источник: Увеличение числа первых 10 миллионов пользователей.
Федерация (или функциональное разделение) разделяет базы данных по функциям. Например, вместо одной монолитной базы данных вы можете иметь три базы данных: форумы , пользователи и продукты , что приведет к меньшему трафику чтения и записи в каждую базу данных и, следовательно, к меньшей задержке репликации. Меньшие базы данных приводят к большему количеству данных, которые могут поместиться в памяти, что, в свою очередь, приводит к большему количеству попаданий в кэш из-за улучшенной локальности кэша. Без единого центрального мастера сериализующих операций записи вы можете писать параллельно, увеличивая пропускную способность.
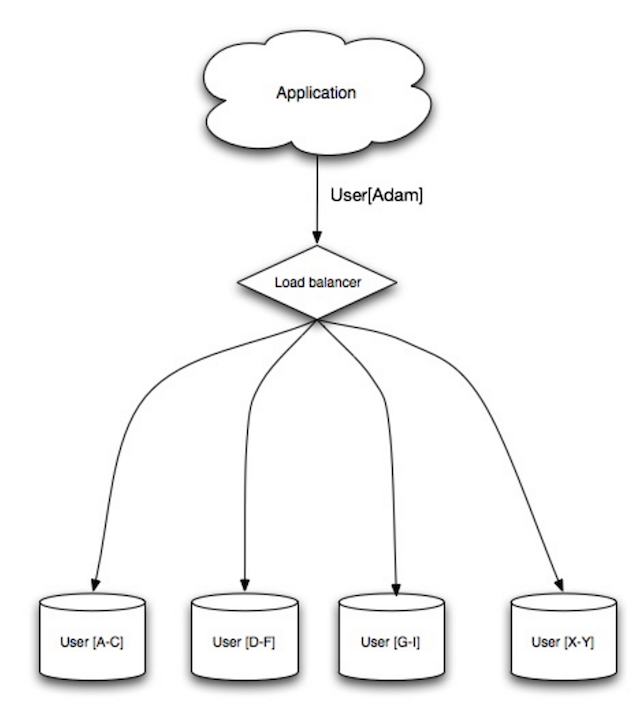
Источник: Масштабируемость, доступность, стабильность, шаблоны.
При сегментировании данные распределяются по разным базам данных, так что каждая база данных может управлять только подмножеством данных. Если взять в качестве примера базу данных пользователей, то по мере увеличения количества пользователей в кластер добавляется больше шардов.
Подобно преимуществам федерации, сегментирование приводит к меньшему трафику чтения и записи, меньшему количеству репликации и большему количеству обращений к кешу. Размер индекса также уменьшается, что обычно повышает производительность при более быстрых запросах. Если один сегмент выйдет из строя, остальные продолжат работать, хотя вам потребуется добавить некоторую форму репликации, чтобы избежать потери данных. Как и в случае с федерацией, здесь не существует единого центрального мастера сериализации записей, что позволяет писать параллельно с повышенной пропускной способностью.
Распространенные способы сегментирования таблицы пользователей — либо по инициалу фамилии пользователя, либо по географическому местоположению пользователя.
Денормализация пытается улучшить производительность чтения за счет некоторых производительности записи. Избыточные копии данных записаны в нескольких таблицах, чтобы избежать дорогих соединений. Некоторые RDBMS, такие как PostgreSQL и Oracle Support, материализованные представления, которые обрабатывают работу по хранению избыточной информации и поддержания постоянных копий.
Как только данные распределяются с такими методами, как федерация и шарнинг, управление соединениями в центрах обработки данных еще больше увеличивает сложность. Денормализация может обойти необходимость в таких сложных соединениях.
В большинстве систем чтения могут сильно численнее писать 100: 1 или даже 1000: 1. Читает, что приведет к сложному соединению базы данных, может быть очень дорогим, что тратит значительное количество времени на дисковые операции.
SQL Tuning - это широкая тема, и многие книги были написаны в качестве ссылки.
Важно сравнить и профиль , чтобы имитировать и раскрыть узкие места.
Бенчмаркинг и профилирование могут указать вам на следующие оптимизации.
CHAR вместо VARCHAR для полей фиксированной длины.CHAR эффективно допускает быстрый, случайный доступ, тогда как с VARCHAR вы должны найти конец строки, прежде чем перейти к следующему.TEXT для больших блоков текста, таких как сообщения в блоге. TEXT также допускает логический поиск. Использование TEXT поля приводит к хранению указателя на диске, который используется для поиска текстового блока.INT для большего числа до 2^32 или 4 миллиарда.DECIMAL для валюты, чтобы избежать ошибок с плавающей запятой.BLOBS , храните место, где вместо этого есть объект.VARCHAR(255) является наибольшим количеством символов, которые можно подсчитать в 8 -битном числе, часто максимизируя использование байта в некоторых RDBMS.NOT NULL ограничение, где применимо для улучшения производительности поиска. SELECT , GROUP BY , ORDER BY , JOIN ) могут быть быстрее с индексами.NOSQL-это набор элементов данных, представленных в хранилище ключей , хранилище документов , широком магазине столбцов или базе данных графиков . Данные денормализованы, а соединения обычно выполняются в коде приложения. В большинстве запасов NOSQL не хватает истинных кислотных транзакций и предпочитают возможную консистенцию.
База часто используется для описания свойств баз данных NOSQL. По сравнению с теоремом CAP Base выбирает доступность по сравнению с последовательности.
В дополнение к выбору между SQL или NOSQL, полезно понять, какой тип базы данных NOSQL лучше всего соответствует вашим варианту использования. Мы рассмотрим хранилища ключевых значений , хранилища документов , широкие хранилища столбцов и графические базы данных в следующем разделе.
Абстракция: хэш -таблица
Магазин ключевых значений обычно позволяет o (1) чтения и записи и часто поддерживается памятью или SSD. Слайки данных могут поддерживать ключи в лексикографическом порядке, что позволяет эффективно извлекать ключевые диапазоны. Ключевые магазины могут позволить хранение метаданных со значением.
Ключевые запасы обеспечивают высокую производительность и часто используются для простых моделей данных или для быстро меняющихся данных, таких как кэш-слой в памяти. Поскольку они предлагают лишь ограниченный набор операций, сложность переходит на уровень приложения, если необходимы дополнительные операции.
Магазин ключевых значений является основой для более сложных систем, таких как хранилище документов, и в некоторых случаях, база данных графиков.
Абстракция: хранилище ключа с документами, хранящимися как значения
Хранение документов сосредоточено вокруг документов (XML, JSON, BINARY и т. Д.), Где документ хранит всю информацию для данного объекта. Магазины документов предоставляют API или язык запросов для запроса на основе внутренней структуры самого документа. Обратите внимание, что многие магазины ключевых значений включают функции для работы с метаданными значения, размывая линии между этими двумя типами хранения.
Основываясь на базовой реализации, документы организованы с помощью коллекций, тегов, метаданных или каталогов. Хотя документы могут быть организованы или сгруппированы вместе, документы могут иметь поля, которые полностью отличаются друг от друга.
Некоторые хранилища документов, такие как MongoDB и CouchDB, также предоставляют SQL-подобный язык для выполнения сложных запросов. DynamoDB поддерживает как ключевые значения, так и документы.
Хранилища документов обеспечивают высокую гибкость и часто используются для работы с иногда изменяющимися данными.
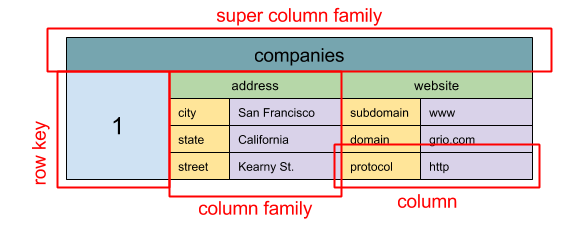
Источник: SQL & NOSQL, краткая история
Абстракция: вложенная карта
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>.
Основная единица данных широкого хранилища данных - это столбец (пара имен/значение). Столбец может быть сгруппирован в семейства столбцов (аналогично таблице SQL). Семьи супер столбцы дальнейшие группы колонн. Семьи. Вы можете получить доступ к каждому столбцу независимо с помощью клавиши строки, и столбцы с одной и той же клавиш строки образуют строку. Каждое значение содержит метку времени для управления версиями и для разрешения конфликтов.
Google представил BigTable как первый широкий магазин колонок, который повлиял на HBASE с открытым исходным кодом, часто используемый в экосистеме Hadoop, и Cassandra из Facebook. Такие магазины, как BigTable, HBASE и Cassandra, поддерживают ключи в лексикографическом порядке, что позволяет эффективно извлекать селективные ключевые диапазоны.
Широкие магазины колонны предлагают высокую доступность и высокую масштабируемость. Они часто используются для очень больших наборов данных.
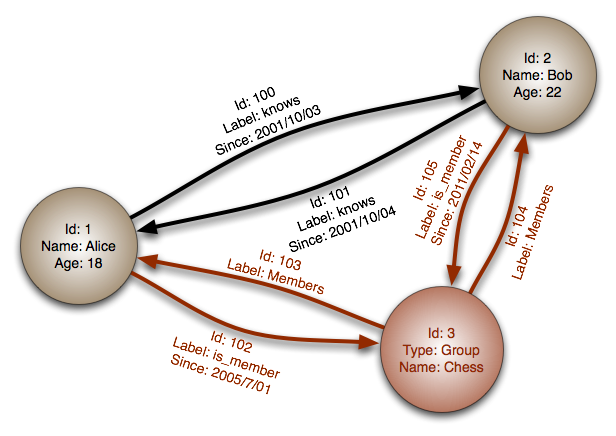
Источник: графическая база данных
Абстракция: график
В графической базе данных каждый узел является записью, и каждая дуга является отношением между двумя узлами. Графические базы данных оптимизированы для представления сложных отношений со многими иностранными ключами или многими ко многим отношениям.
Графики базы данных предлагают высокую производительность для моделей данных со сложными отношениями, такими как социальная сеть. Они относительно новые и еще не используются широко используемыми; Может быть сложнее найти инструменты и ресурсы разработки. Многие графики можно получить только с API REST.
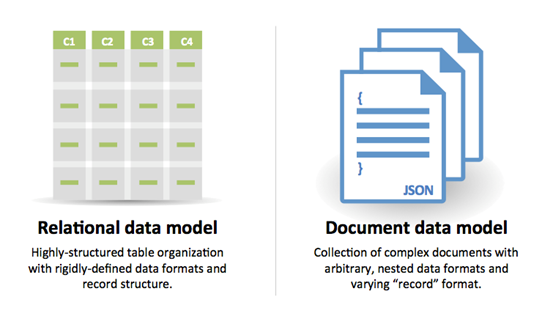
Источник: переход от RDBMS в NOSQL
Причины SQL :
Причины для nosql :
Пример данных хорошо подходит для NoSQL:
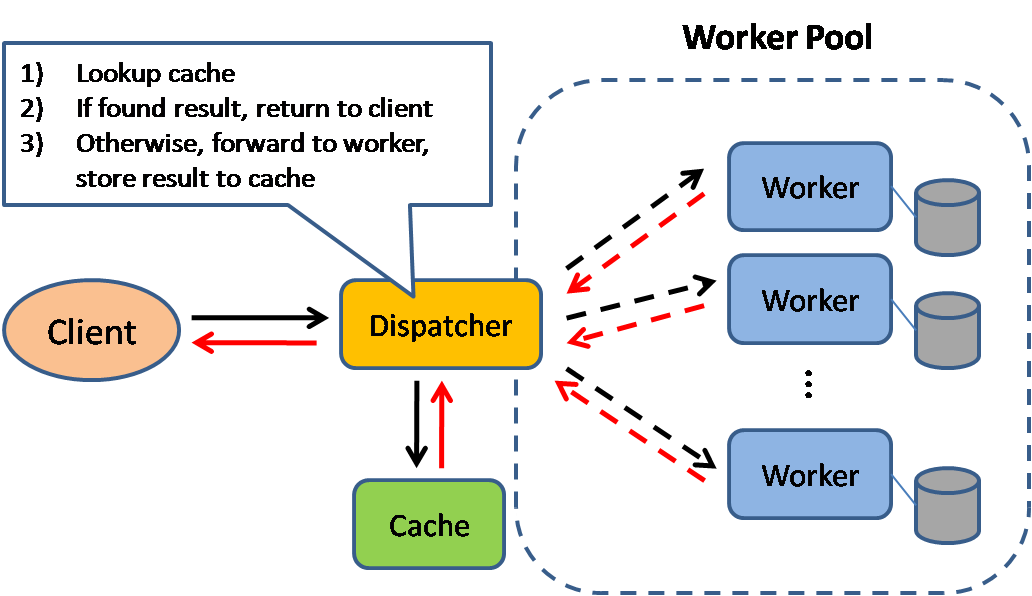
Источник: масштабируемые шаблоны проектирования системы
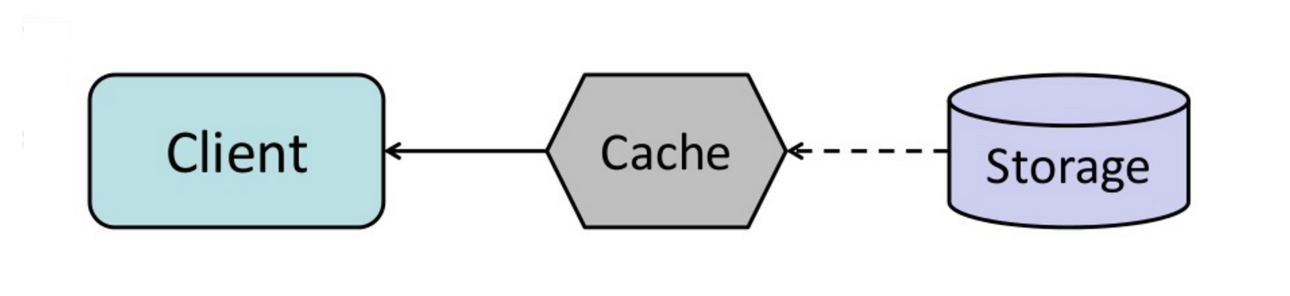
Кэширование улучшает время загрузки страницы и может уменьшить нагрузку на ваши серверы и базы данных. В этой модели диспетчер сначала будет поиск, если запрос был сделан ранее, и попытаться найти предыдущий результат для возврата, чтобы сохранить фактическое выполнение.
Базы данных часто извлекают выгоду из равномерного распределения чтения и записи по его разделам. Популярные предметы могут исказить распределение, вызывая узкие места. Размещение кэша перед базой данных может помочь поглотить неровные нагрузки и шипы в трафике.
Кэши могут быть расположены на стороне клиента (ОС или браузер), на стороне сервера или в отдельном уровне кэша.
CDN считаются типом кеша.
Обратные прокси и кэши, такие как лак, могут непосредственно обслуживать статическое и динамическое содержание. Веб -серверы также могут кэшировать запросы, возвращая ответы без необходимости связываться с серверами приложений.
Ваша база данных обычно включает в себя некоторый уровень кэширования в конфигурации по умолчанию, оптимизированный для общего варианта использования. Настройка этих настроек для конкретных шаблонов использования может еще больше повысить производительность.
Кэши в памяти, такие как Memcached и Redis, представляют собой запасы ключей между вашим приложением и хранилищем данных. Поскольку данные хранятся в оперативной памяти, они намного быстрее, чем типичные базы данных, где данные хранятся на диске. ОЗУ более ограничен, чем диск, поэтому алгоритмы недействительной кэша, такие как наименее недавно используемые (LRU), могут помочь аннулировать «холодные» записи и сохранить «горячие» данные в оперативной памяти.
Redis имеет следующие дополнительные функции:
Существует несколько уровней, которые вы можете кэш, которые делятся на две общие категории: запросы и объекты базы данных:
Как правило, вы должны стараться избегать кэширования на основе файлов, так как это затрудняет клонирование и автоматическую масштаб.
Всякий раз, когда вы запрашиваете базу данных, хэш -запрос как ключ и сохраняет результат в кэше. Этот подход страдает от проблем с истечением срока действия:
Смотрите ваши данные как объект, похожий на то, что вы делаете с кодом приложения. Соберите ваше приложение собрать набор данных из базы данных в экземпляр класса или структуру данных:
Предложения о том, что кешю:
Поскольку вы можете сохранить только ограниченное количество данных в кэше, вам необходимо определить, какая стратегия обновления кэша работает лучше всего для вашего варианта использования.
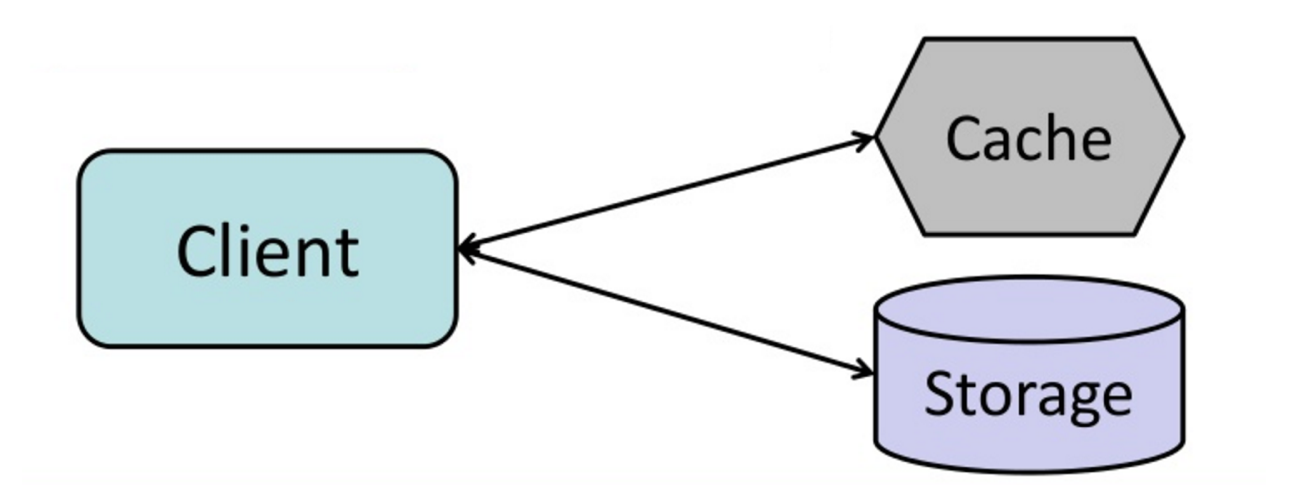
Источник: от кеша до сетки данных в памяти
Приложение отвечает за чтение и написание с хранения. Кэш не взаимодействует с хранением напрямую. Приложение делает следующее:
def get_user ( self , user_id ):
user = cache . get ( "user.{0}" , user_id )
if user is None :
user = db . query ( "SELECT * FROM users WHERE user_id = {0}" , user_id )
if user is not None :
key = "user.{0}" . format ( user_id )
cache . set ( key , json . dumps ( user ))
return userMemcached обычно используется таким образом.
Последующие считывания данных, добавленных в кэш, быстрые. Кэш-айд также называется ленивой загрузкой. Только запрашиваемые данные кэшируются, что позволяет избежать заполнения кэша данными, которые не запрошены.
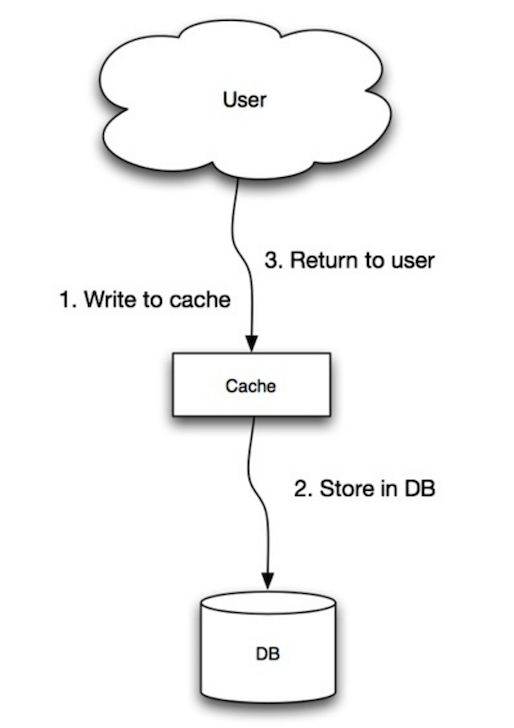
Источник: масштабируемость, доступность, стабильность, шаблоны
Приложение использует кэш в качестве основного хранилища данных, чтение и написание данных в него, в то время как кэш отвечает за чтение и запись в базу данных:
Код приложения:
set_user ( 12345 , { "foo" : "bar" })Кэш -код:
def set_user ( user_id , values ):
user = db . query ( "UPDATE Users WHERE id = {0}" , user_id , values )
cache . set ( user_id , user )Программа записи-это медленная общая операция из-за операции записи, но последующие чтения только что написанных данных быстро. Пользователи, как правило, более терпимы к задержке при обновлении данных, чем чтение данных. Данные в кэше не являются устаревшими.
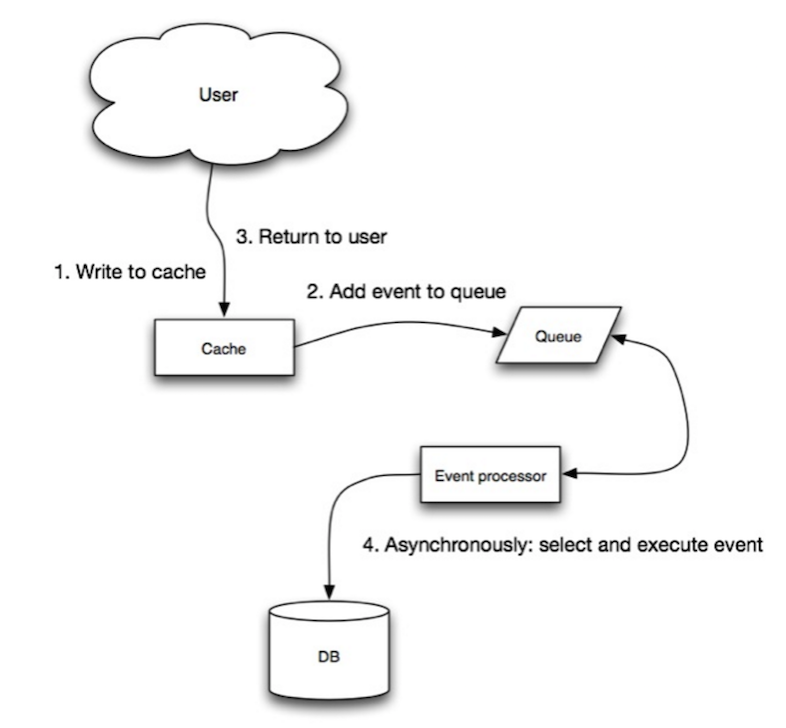
Источник: масштабируемость, доступность, стабильность, шаблоны
В записи и приложении приложение выполняет следующее:
Источник: от кеша до сетки данных в памяти
Вы можете настроить кэш для автоматического обновления любого недавно доступного входа в кэш до его истечения.
Обновление может привести к снижению задержки по сравнению с проведением чтения, если кэш может точно предсказать, какие элементы могут потребоваться в будущем.
Источник: вступление в архитекцию систем для масштаба
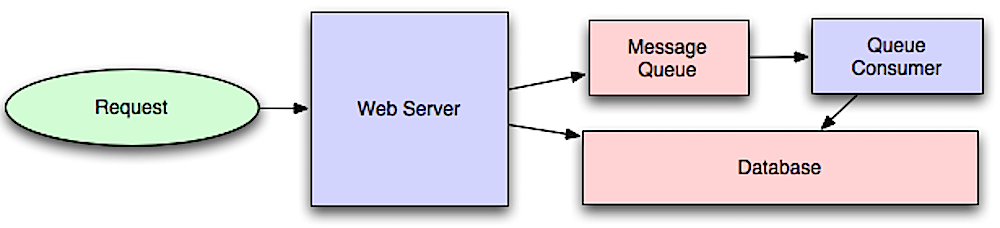
Асинхронные рабочие процессы помогают сократить время запроса на дорогостоящие операции, которые в противном случае будут выполнены встроенными. Они также могут помочь, выполняя трудоемкую работу заранее, например, периодическая агрегация данных.
Очереди сообщений получают, удерживают и доставляют сообщения. Если операция слишком медленная, чтобы выполнять встроенные, вы можете использовать очередь сообщений со следующим рабочим процессом:
Пользователь не заблокирован, и задание обрабатывается в фоновом режиме. В течение этого времени клиент мог при желании выполнить небольшое количество обработки, чтобы показаться, что задача завершилась. Например, в случае публикации твита, твит может быть мгновенно опубликован на ваш график, но это может занять некоторое время, прежде чем ваш твит фактически будет доставлен всем вашим подписчикам.
Redis полезен в качестве простого брокера сообщения, но сообщения могут быть потеряны.
RabbitMQ популярен, но требует, чтобы вы адаптировались к протоколу AMQP и управляете своими собственными узлами.
Amazon SQS размещен, но может иметь высокую задержку и имеет возможность доставлять сообщения дважды.
Очерки задач получают задачи и связанные с ними данные, запускают их, а затем обеспечивают свои результаты. Они могут поддерживать планирование и могут быть использованы для запуска вычислительных заданий в фоновом режиме.
Сельдерея имеет поддержку для планирования и в первую очередь имеет поддержку Python.
Если очереди начинают значительно расти, размер очереди может стать больше памяти, что приводит к промахам кэша, чтению дисков и даже более медленной производительности. Обратное давление может помочь, ограничивая размер очереди, тем самым сохраняя высокую пропускную способность и хорошее время отклика для заданий, уже в очереди. Как только очередь заполнится, клиенты заняты сервером или код состояния HTTP 503, чтобы попробовать еще раз. Клиенты могут повторить запрос позже, возможно, с экспоненциальным отбором.
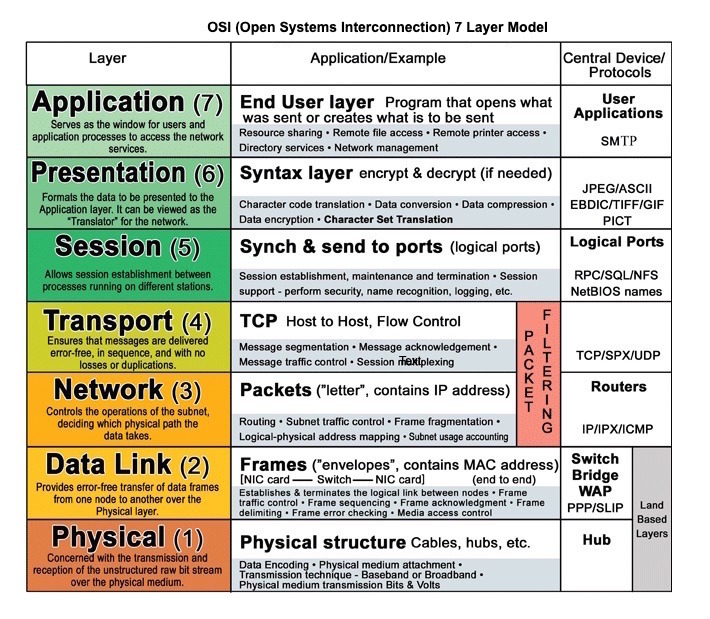
Источник: модель слоя OSI 7
HTTP - это метод кодирования и транспортировки данных между клиентом и сервером. Это протокол запроса/ответа: запросы на выпуск клиентов и ответы на серверы с соответствующим контентом и информацией о статусе завершения о запросе. HTTP является автономным, позволяющим проходить запросы и ответы через многие промежуточные маршрутизаторы и серверы, которые выполняют балансировку нагрузки, кэширование, шифрование и сжатие.
Основной HTTP -запрос состоит из глагола (метод) и ресурса (конечная точка). Ниже приведены общие глаголы HTTP:
| Глагол | Описание | Idempotent* | Безопасный | Кэшируемый |
|---|---|---|---|---|
| ПОЛУЧАТЬ | Читает ресурс | Да | Да | Да |
| ПОЧТА | Создает ресурс или запускает процесс, который обрабатывает данные | Нет | Нет | Да, если ответ содержит информацию о свежесть |
| ПОМЕЩАТЬ | Создает или заменяет ресурс | Да | Нет | Нет |
| ПЛАСТЫРЬ | Частично обновляет ресурс | Нет | Нет | Да, если ответ содержит информацию о свежесть |
| УДАЛИТЬ | Удаляет ресурс | Да | Нет | Нет |
*Можно вызывать много раз без разных результатов.
HTTP является протоколом прикладного уровня, полагающимся на протоколы нижнего уровня, такие как TCP и UDP .
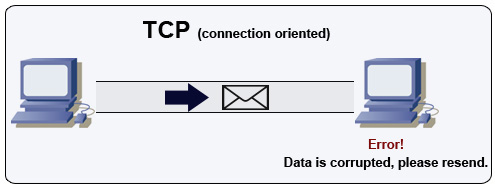
Источник: как сделать многопользовательскую игру
TCP-это протокол, ориентированный на соединение, по IP-сети. Соединение устанавливается и прекращается с использованием рукопожатия. Все отправленные пакеты гарантированно достигнут пункта назначения в исходном порядке и без коррупции до:
Если отправитель не получит правильный ответ, он отправит пакеты. Если есть несколько тайм -аутов, соединение сброшено. TCP также реализует контроль потока и контроль заторов. Эти гарантии вызывают задержки и, как правило, приводят к менее эффективной передаче, чем UDP.
Чтобы обеспечить высокую пропускную способность, веб -серверы могут оставлять большое количество подключений TCP, что приводит к высокому использованию памяти. Может быть дорого иметь большое количество открытых соединений между потоками веб -сервера и, скажем, сервером Memcached. Объединение соединений может помочь в дополнение к переходу на UDP, где это применимо.
TCP полезен для приложений, которые требуют высокой надежности, но имеют меньше времени. Некоторые примеры включают веб -серверы, информацию о базе данных, SMTP, FTP и SSH.
Используйте TCP через UDP, когда:
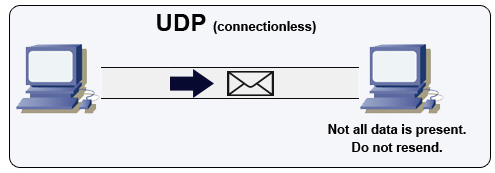
Источник: как сделать многопользовательскую игру
UDP не соединяется. Патограммы (аналогичные пакетам) гарантируются только на уровне данных. ДАТАграммы могут достичь своего пункта назначения вне порядка или вообще вообще. UDP не поддерживает контроль заторов. Без гарантий, что поддержка TCP, UDP, как правило, более эффективен.
UDP может транслировать, отправляя DataGrams на все устройства на подсети. Это полезно для DHCP, поскольку клиент еще не получил IP -адрес, что предотвращает трансляцию TCP без IP -адреса.
UDP менее надежен, но хорошо работает в случае использования в реальном времени, таких как VoIP, видеочат, потоковая передача и многопользовательские игры в реальном времени.
Используйте UDP через TCP, когда:
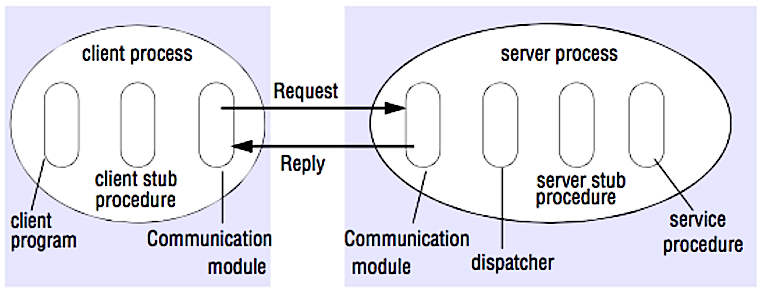
Источник: взломать интервью для проектирования системы
В RPC клиент вызывает процедуру выполнения в другом адресном пространстве, обычно на удаленном сервере. Процедура кодирована так, как если бы это был локальный вызов процедуры, абстрагируя детали того, как общаться с сервером из клиентской программы. Удаленные звонки, как правило, медленнее и менее надежны, чем местные вызовы, поэтому полезно отличить звонки RPC от местных вызовов. Популярные рамки RPC включают Protobuf, Thrift и Avro.
RPC является протоколом запроса ответа:
Образец вызовов RPC:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC сосредоточен на разоблачении поведения. RPC часто используются по соображениям производительности с внутренней связью, так как вы можете получить нативные вызовы ручной работы, чтобы лучше соответствовать вашим вариантам использования.
Выберите местную библиотеку (так же SDK), когда:
HTTP API после отдыха, как правило, используются чаще для публичных API.
REST - это архитектурный стиль, обеспечивающий соблюдение модели клиента/сервера, где клиент действует на наборе ресурсов, управляемых сервером. Сервер предоставляет представление ресурсов и действий, которые могут либо манипулировать, либо получить новое представление ресурсов. Вся связь должна быть без сохранения состояния и кэшированного.
Есть четыре качества спокойного интерфейса:
Образец вызовов отдыха:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
Отдых сосредоточен на разоблачении данных. Он минимизирует связь между клиентом/сервером и часто используется для публичных HTTP API. REST использует более общий и равномерный метод выявления ресурсов через URI, представление через заголовки и действия с помощью глаголов, таких как Get, Post, Pult, Delete и Patch. Будучи без гражданства, отдых отлично подходит для горизонтального масштабирования и разделения.
| Операция | ПКП | ОТДЫХ |
|---|---|---|
| Зарегистрироваться | Пост /регистрация | Пост /люди |
| Подать в отставку | Пост /уйти в отставку { "Персид": "1234" } | Удалить /люди /1234 |
| Прочтите человека | Получить /readperson? Personid = 1234 | Получить /люди /1234 |
| Прочтите список предметов человека | Get /readUserSitemslist? Personid = 1234 | Получить /люди/1234/предметы |
| Добавьте товар в предметы человека | Post /additemteStersitemslist { "Personid": "1234"; "itemid": "456" } | Post /persons/1234/пункты { "itemid": "456" } |
| Обновите элемент | Post /modifyitem { "itemid": "456"; "Ключ": "Значение" } | Поместите /пункты /456 { "Ключ": "Значение" } |
| Удалить элемент | Post /RemoveItem { "itemid": "456" } | Удалить /пункты /456 |
Источник: Вы действительно знаете, почему вы предпочитаете отдых по сравнению с RPC
Этот раздел может использовать некоторые обновления. Подумайте о том, чтобы внести свой вклад!
Безопасность - это широкая тема. Если у вас нет значительного опыта, фон безопасности или вы подаете заявку на должность, которая требует знаний о безопасности, вам, вероятно, не нужно будет знать больше, чем основы:
Иногда вас просят сделать оценки «обратной стороны». Например, вам может потребоваться определить, сколько времени потребуется, чтобы создать 100 миниатюр изображений с диска или сколько памяти займет структура данных. Силы двух номеров таблицы и задержки, которые должен знать каждый программист, являются удобными ссылками.
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Удобные метрики на основе чисел выше:
Общие вопросы интервью с общим системой, со ссылкой на ресурсы о том, как решить каждый.
| Вопрос | Ссылка (ы) |
|---|---|
| Разработать службу синхронизации файлов, как Dropbox | youtube.com |
| Разработать поисковую систему, как Google | queue.acm.org stackexchange.com ardendertat.com Стэнфорд.edu |
| Создайте масштабируемый веб -гусениц, такой как Google | Quora.com |
| Проектируйте Google Docs | code.google.com neil.fraser.name |
| Проектируйте магазин ключевой стоимости, такой как Redis | SlideShare.net |
| Разработать кеш -систему, такую как Memcached | SlideShare.net |
| Разработать систему рекомендаций, такую как Amazon | Hulu.com ijcai13.org |
| Проектируйте систему Tinyurl, такую как Bitly | n00tc0d3r.blogspot.com |
| Создайте приложение для чата, как WhatsApp | highscalability.com |
| Создайте систему обмена изображениями, такую как Instagram | highscalability.com highscalability.com |
| Создать функцию подачи новостей в Facebook | Quora.com Quora.com SlideShare.net |
| Создать функцию временной шкалы Facebook | Facebook.com highscalability.com |
| Создать функцию чата в Facebook | Erlang-factory.com Facebook.com |
| Создайте функцию поиска графа, такую как Facebook | Facebook.com Facebook.com Facebook.com |
| Создайте сеть доставки контента, такую как CloudFlare | figshare.com |
| Создайте трендовую систему темы, такую как Twitter | Michael-noll.com snikolov .wordpress.com |
| Разработать систему генерации случайных идентификаторов | blog.twitter.com github.com |
| Вернуть верхние k -запросы в течение временного интервала | cs.ucsb.edu wpi.edu |
| Разработать систему, которая обслуживает данные из нескольких центров обработки данных | highscalability.com |
| Создайте онлайн -многопользовательскую карточную игру | indieflashblog.com BuildNewgames.com |
| Проектируйте систему сбора мусора | вещи withStuff.com Вашингтон.edu |
| Разработать ограничитель API | https://stripe.com/blog/ |
| Проектируйте фондовую биржу (например, NASDAQ или Binance) | Джейн -стрит Реализация Голанга GO реализация |
| Добавить вопрос о разработке системы | Способствовать |
Статьи о том, как разработаны системы реального мира.
Источник: временные рамки Twitter в масштабе
Не сосредотачивайтесь на придурких деталях для следующих статей, вместо этого:
| Тип | Система | Ссылка (ы) |
|---|---|---|
| Обработка данных | MapReduce - Распределенная обработка данных из Google | Research.google.com |
| Обработка данных | Spark - Распределенная обработка данных из DataBricks | SlideShare.net |
| Обработка данных | Storm - Распределенная обработка данных из Twitter | SlideShare.net |
| Хранилище данных | BigTable - распределенная база данных, ориентированная на столбцы, из Google | Harvard.edu |
| Хранилище данных | HBASE - реализация BigTable с открытым исходным кодом | SlideShare.net |
| Хранилище данных | Cassandra - Распределенная база данных, ориентированная на столбцы, из Facebook | SlideShare.net |
| Хранилище данных | DynamoDB - Ориентированная на документ база данных от Amazon | Harvard.edu |
| Хранилище данных | MongoDB - база данных, ориентированная на документ | SlideShare.net |
| Хранилище данных | Саньенер - база данных по всему миру из Google | Research.google.com |
| Хранилище данных | Memcached - Система кэширования распределенной памяти | SlideShare.net |
| Хранилище данных | Redis - Система кэширования распределенной памяти с постоянностью и типами значений | SlideShare.net |
| Файловая система | Google File System (GFS) - Distributed file system | research.google.com |
| Файловая система | Hadoop File System (HDFS) - Open source implementation of GFS | apache.org |
| Разное | Chubby - Lock service for loosely-coupled distributed systems from Google | research.google.com |
| Разное | Dapper - Distributed systems tracing infrastructure | research.google.com |
| Разное | Kafka - Pub/sub message queue from LinkedIn | SlideShare.net |
| Разное | Zookeeper - Centralized infrastructure and services enabling synchronization | SlideShare.net |
| Add an architecture | Способствовать |
| Компания | Reference(s) |
|---|---|
| Амазонка | Amazon architecture |
| Cinchcast | Producing 1,500 hours of audio every day |
| DataSift | Realtime datamining At 120,000 tweets per second |
| Дропбокс | How we've scaled Dropbox |
| ЭСПН | Operating At 100,000 duh nuh nuhs per second |
| Google architecture | |
| Инстаграм | 14 million users, terabytes of photos What powers Instagram |
| Justin.tv | Justin.Tv's live video broadcasting architecture |
| Фейсбук | Scaling memcached at Facebook TAO: Facebook's distributed data store for the social graph Facebook's photo storage How Facebook Live Streams To 800,000 Simultaneous Viewers |
| Фликр | Flickr architecture |
| Почтовый ящик | From 0 to one million users in 6 weeks |
| Нетфликс | A 360 Degree View Of The Entire Netflix Stack Netflix: What Happens When You Press Play? |
| Пинтерест | From 0 To 10s of billions of page views a month 18 million visitors, 10x growth, 12 employees |
| Playfish | 50 million monthly users and growing |
| PlentyOfFish | PlentyOfFish architecture |
| Salesforce | How they handle 1.3 billion transactions a day |
| Переполнение стека | Stack Overflow architecture |
| TripAdvisor | 40M visitors, 200M dynamic page views, 30TB data |
| Тамблер | 15 billion page views a month |
| Твиттер | Making Twitter 10000 percent faster Storing 250 million tweets a day using MySQL 150M active users, 300K QPS, a 22 MB/S firehose Timelines at scale Big and small data at Twitter Operations at Twitter: scaling beyond 100 million users How Twitter Handles 3,000 Images Per Second |
| Убер | How Uber scales their real-time market platform Lessons Learned From Scaling Uber To 2000 Engineers, 1000 Services, And 8000 Git Repositories |
| The WhatsApp architecture Facebook bought for $19 billion | |
| Ютуб | YouTube scalability YouTube architecture |
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Interested in adding a section or helping complete one in-progress? Способствовать!
Credits and sources are provided throughout this repo.
Особая благодарность:
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/


