cleanrl
v1.0.0 CleanRL Release ?
CleanRL — это библиотека глубокого обучения с подкреплением, которая обеспечивает высококачественную однофайловую реализацию с удобными для исследований функциями. Реализация понятна и проста, но мы можем масштабировать ее для проведения тысяч экспериментов с помощью AWS Batch. Основные особенности CleanRL:
ppo_atari.py содержит всего 340 строк кода, но содержит все подробности реализации того, как PPO работает с играми Atari, поэтому это отличная справочная реализация для людей, которые не хотят читать всю модульную библиотеку .Вы можете прочитать больше о CleanRL в нашем документе и документации JMLR.
Известные проекты, связанные с CleanRL:
Поддержка Gymnasium : Farama-Foundation/Gymnasium — это новое поколение
openai/gym, которое будет продолжать поддерживаться и вводить новые функции. Пожалуйста, смотрите их объявление для получения более подробной информации. Мы переходим наgymnasium, и прогресс можно отслеживать в vwxyzjn/cleanrl#277.
️ ПРИМЕЧАНИЕ . CleanRL не является модульной библиотекой и поэтому не предназначен для импорта. За счет дублирования кода мы упрощаем понимание всех деталей реализации варианта алгоритма DRL, поэтому CleanRL имеет свои плюсы и минусы. Вам следует рассмотреть возможность использования CleanRL, если вы хотите 1) понять все детали реализации варианта алгоритма или 2) создать прототип расширенных функций, которые не поддерживаются другими модульными библиотеками DRL (CleanRL имеет минимальное количество строк кода, поэтому он дает вам отличный опыт отладки, и вы не мне не нужно создавать много подклассов, как иногда в модульных библиотеках DRL).
Предпосылки:
Чтобы проводить эксперименты локально, попробуйте следующее:
git clone https://github.com/vwxyzjn/cleanrl.git && cd cleanrl
poetry install
# alternatively, you could use `poetry shell` and do
# `python run cleanrl/ppo.py`
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
# open another terminal and enter `cd cleanrl/cleanrl`
tensorboard --logdir runsЧтобы использовать отслеживание экспериментов с помощью wandb, запустите
wandb login # only required for the first time
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
--track
--wandb-project-name cleanrltest Если вы не используете poetry , вы можете установить CleanRL с помощью requirements.txt :
# core dependencies
pip install -r requirements/requirements.txt
# optional dependencies
pip install -r requirements/requirements-atari.txt
pip install -r requirements/requirements-mujoco.txt
pip install -r requirements/requirements-mujoco_py.txt
pip install -r requirements/requirements-procgen.txt
pip install -r requirements/requirements-envpool.txt
pip install -r requirements/requirements-pettingzoo.txt
pip install -r requirements/requirements-jax.txt
pip install -r requirements/requirements-docs.txt
pip install -r requirements/requirements-cloud.txt
pip install -r requirements/requirements-memory_gym.txtЧтобы запустить обучающие скрипты в других играх:
poetry shell
# classic control
python cleanrl/dqn.py --env-id CartPole-v1
python cleanrl/ppo.py --env-id CartPole-v1
python cleanrl/c51.py --env-id CartPole-v1
# atari
poetry install -E atari
python cleanrl/dqn_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/ppo_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/sac_atari.py --env-id BreakoutNoFrameskip-v4
# NEW: 3-4x side-effects free speed up with envpool's atari (only available to linux)
poetry install -E envpool
python cleanrl/ppo_atari_envpool.py --env-id BreakoutNoFrameskip-v4
# Learn Pong-v5 in ~5-10 mins
# Side effects such as lower sample efficiency might occur
poetry run python ppo_atari_envpool.py --clip-coef=0.2 --num-envs=16 --num-minibatches=8 --num-steps=128 --update-epochs=3
# procgen
poetry install -E procgen
python cleanrl/ppo_procgen.py --env-id starpilot
python cleanrl/ppg_procgen.py --env-id starpilot
# ppo + lstm
poetry install -E atari
python cleanrl/ppo_atari_lstm.py --env-id BreakoutNoFrameskip-v4
Вы также можете использовать готовую среду разработки, размещенную в Gitpod:
| Алгоритм | Варианты реализованы |
|---|---|
| ✅ Градиент проксимальной политики (PPO) | ppo.py , документы |
ppo_atari.py , документы | |
ppo_continuous_action.py , документы | |
ppo_atari_lstm.py , документация | |
ppo_atari_envpool.py , документы | |
ppo_atari_envpool_xla_jax.py , документы | |
ppo_atari_envpool_xla_jax_scan.py , документы) | |
ppo_procgen.py , документы | |
ppo_atari_multigpu.py , документация | |
ppo_pettingzoo_ma_atari.py , документы | |
ppo_continuous_action_isaacgym.py , документы | |
ppo_trxl.py , документы | |
| ✅ Глубокое Q-обучение (DQN) | dqn.py , документы |
dqn_atari.py , документация | |
dqn_jax.py , документы | |
dqn_atari_jax.py , документация | |
| ✅ Категориальный DQN (C51) | c51.py , документы |
c51_atari.py , документы | |
c51_jax.py , документы | |
c51_atari_jax.py , документы | |
| ✅ Мягкий актер-критик (SAC) | sac_continuous_action.py , документы |
sac_atari.py , документы | |
| ✅ Глубокий детерминированный политический градиент (DDPG) | ddpg_continuous_action.py , документы |
ddpg_continuous_action_jax.py , документы | |
| ✅ Глубокий детерминированный политический градиент с двойной задержкой (TD3) | td3_continuous_action.py , документы |
td3_continuous_action_jax.py , документы | |
| ✅ Градиент фазовой политики (PPG) | ppg_procgen.py , документы |
| ✅ Случайная сетевая дистилляция (RND) | ppo_rnd_envpool.py , документация |
| ✅ Кдаггер | qdagger_dqn_atari_impalacnn.py , документация |
qdagger_dqn_atari_jax_impalacnn.py , документы |
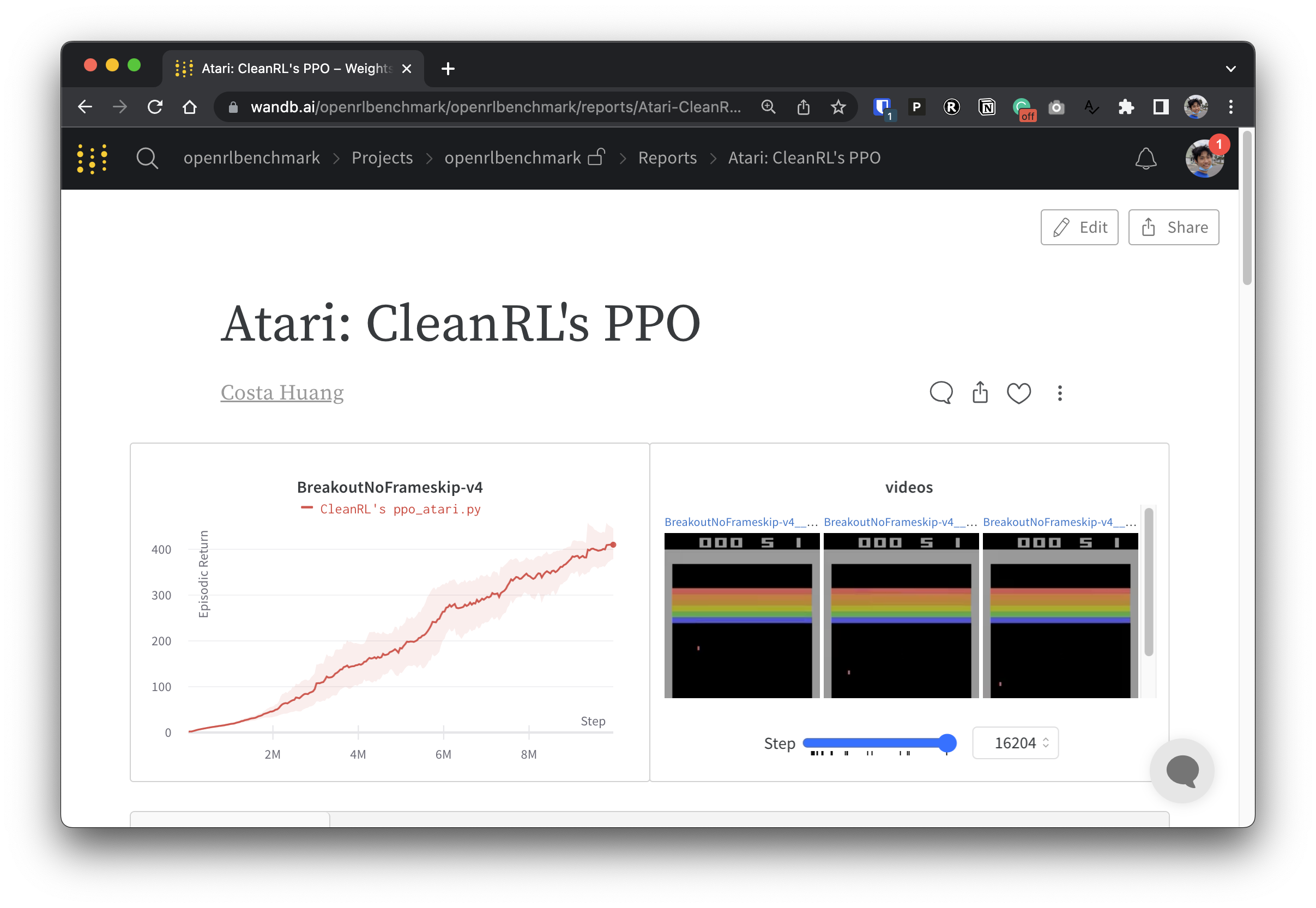
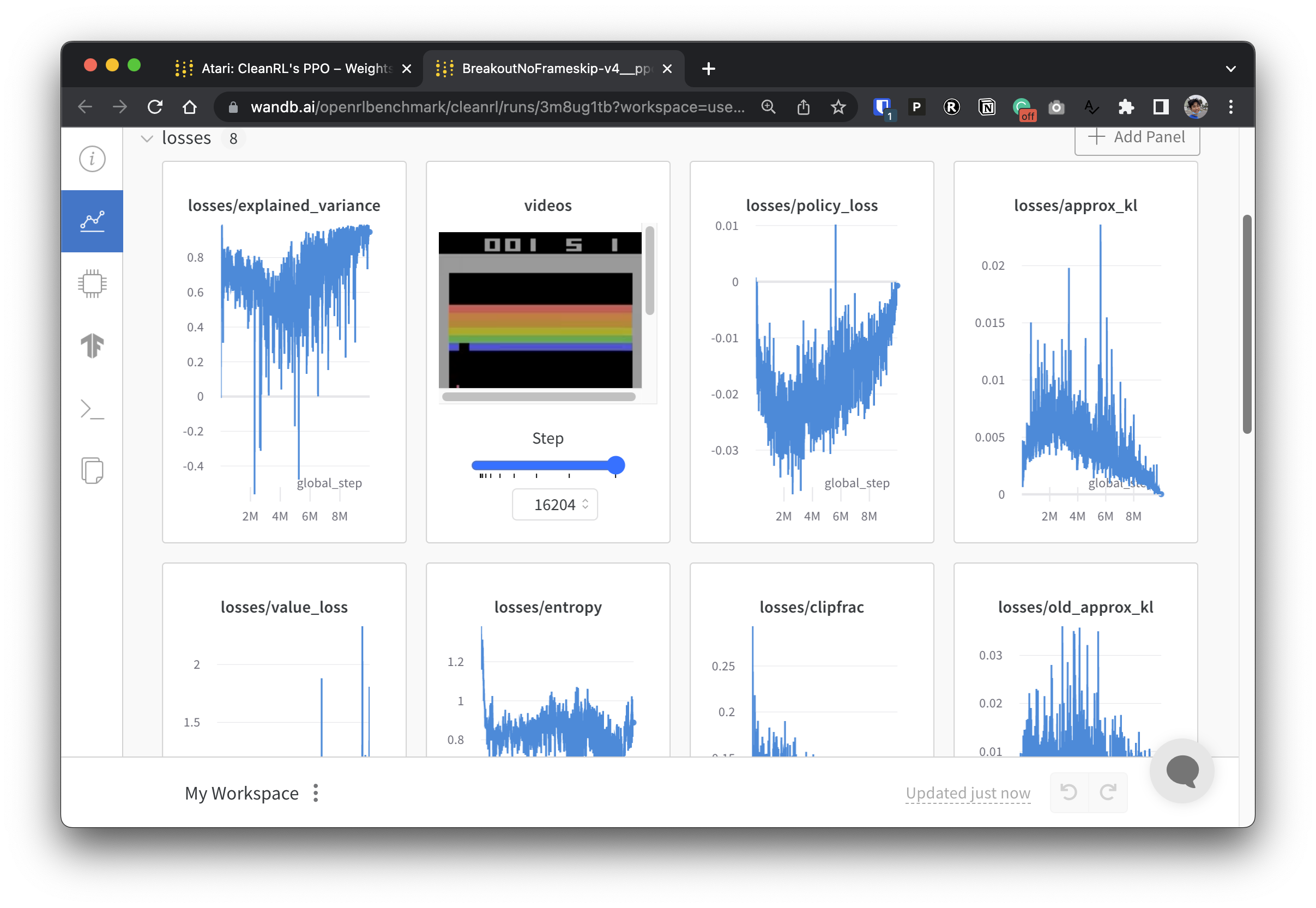
Чтобы сделать наши экспериментальные данные прозрачными, CleanRL участвует в связанном проекте под названием Open RL Benchmark, который содержит отслеживаемые эксперименты из популярных библиотек DRL, таких как наша, Stable-baselines3, openai/baselines, jaxrl и других.
Посетите https://benchmark.cleanrl.dev/, чтобы найти коллекцию отчетов о весах и отклонениях, демонстрирующих отслеживаемые эксперименты DRL. Отчеты являются интерактивными, и исследователи могут легко запрашивать такую информацию, как использование графического процессора и видео игрового процесса агента, которые обычно трудно получить в других тестах RL. В будущем Open RL Benchmark, скорее всего, предоставит исследователям API набора данных, чтобы они могли легко получить доступ к данным (см. репозиторий).
У нас есть сообщество Discord для поддержки. Не стесняйтесь задавать вопросы. Публикация вопросов и PR на Github также приветствуются. Также наши прошлые видеозаписи доступны на YouTube.
Если вы используете CleanRL в своей работе, пожалуйста, ссылайтесь на нашу техническую документацию:
@article { huang2022cleanrl ,
author = { Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo } ,
title = { CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms } ,
journal = { Journal of Machine Learning Research } ,
year = { 2022 } ,
volume = { 23 } ,
number = { 274 } ,
pages = { 1--18 } ,
url = { http://jmlr.org/papers/v23/21-1342.html }
}CleanRL — это проект, поддерживаемый сообществом, и наши участники проводят эксперименты на различном оборудовании.


