3DDFA
1.0.0
Цзяньчжу Го.

[Обновления]
2022.5.14 : Рекомендовать реализацию профилирования лиц на Python: face_pose_augmentation.2020.8.30 : Предварительно обученная модель и код ECCV-20 опубликованы на 3DDFA_V2, авторские права объяснены Цзяньжу Го и группой CBSR.2020.8.2 : Обновите простой порт этого проекта на C++ .2020.7.3 : Расширенная работа «На пути к быстрому, точному и стабильному 3D-плотному выравниванию лица» принята ECCV 2020. Более подробную информацию можно найти на моей странице.2019.9.15 : Некоторые обновления, подробности см. в коммитах.2019.6.17 : Добавлено демо-видео, предоставленное zjjMaiMai.2019.5.2 : Оценка скорости вывода на ЦП с помощью PyTorch v1.1.0, см. здесь и Speed_cpu.py.2019.4.27 : простой конвейер рендеринга, работающий со скоростью ~25 мс/кадр (720p), более подробную информацию см. в rendering.py.2019.4.24 : Предоставление демо-версии obama. Дополнительную информацию см. на demo@obama/readme.md.2019.3.28 : Некоторые обновления.2018.12.23 : Добавлено несколько функций: оценка глубины изображения, PNCC, функция PAF и сериализация объектов. Дополнительные сведения см. в опциях dump_depth , dump_pncc , dump_paf , dump_obj .2018.12.2 : поддержка обрезки лица без ориентиров, см. параметр dlib_landmark .2018.12.1 : Уточните код и добавьте функцию оценки позы, более подробную информацию см. в utils/estimate_pose.py.2018.11.17 : Уточните код и сопоставьте трехмерную вершину с исходным пространством изображения.2018.11.11 : Обновление сквозного конвейера вывода: выводит/сериализует 3D-форму лица и 68 ориентиров по одному произвольному изображению. Для получения более подробной информации см. readme.md ниже.2018.10.4 : Добавлена демонстрация рендеринга сетки лица Matlab в визуализацию.2018.9.9 : Добавлен предварительный процесс обрезки лица в тест.[Тодо]
В этом репозитории содержится улучшенная версия статьи pytorch: «Выравнивание лица в полном диапазоне поз: полное 3D-решение». Добавлено несколько работ, выходящих за рамки оригинальной статьи, в том числе обучение в реальном времени и стратегии обучения. Таким образом, этот репозиторий представляет собой улучшенную версию оригинальной работы. В этом репозитории публикуются предварительно обученные модели Pytorch первого этапа структуры MobileNet-V1, предварительно обработанный набор данных для обучения и тестирования, а также база кода. Обратите внимание, что время вывода составляет около 0,27 мс на изображение (входной пакет из 128 изображений) на GeForce GTX TITAN X.
Этот репозиторий будет постоянно обновляться в мое свободное время, и любые значимые вопросы и пиар приветствуются.
Несколько результатов по набору данных ALFW-2000 (полученные на основе модели Phase1_wpdc_vdc.pth.tar ) показаны ниже.
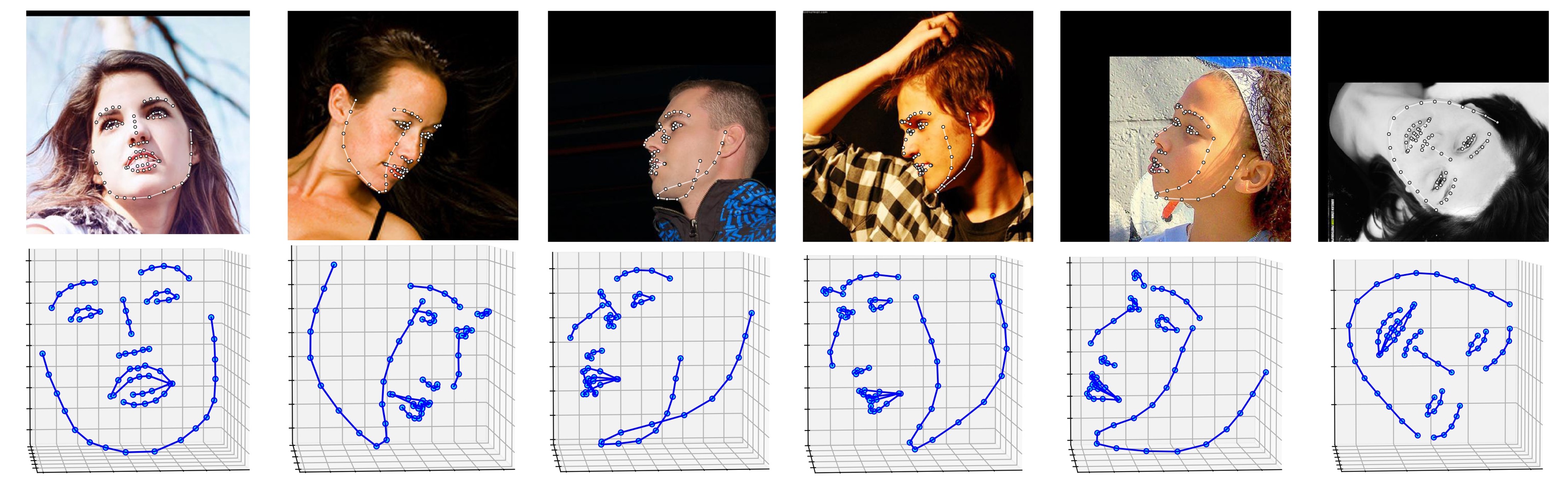





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
Кроме того, я настоятельно рекомендую использовать Python3.6+ вместо более старой версии из-за ее лучшего дизайна.
Клонируйте этот репозиторий (это может занять некоторое время, так как он немного большой)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
Затем загрузите предварительно обученную модель ориентира dlib на Google Диске или Baidu Yun и поместите ее в каталог models . (Чтобы уменьшить размер этого репозитория, я удалил несколько двоичных файлов большого размера, включая эту модель, поэтому вам следует скачать ее :))
Сборка модуля cython (всего одна строка для сборки)
cd utils/cython
python3 setup.py build_ext -i
Это сделано для ускорения оценки глубины и рендеринга PNCC, поскольку Python слишком медленный в цикле for.
Запустите main.py с произвольным изображением в качестве входных данных.
python3 main.py -f samples/test1.jpg
Если вы видите эти выходные данные журнала в терминале, вы успешно запустили его.
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
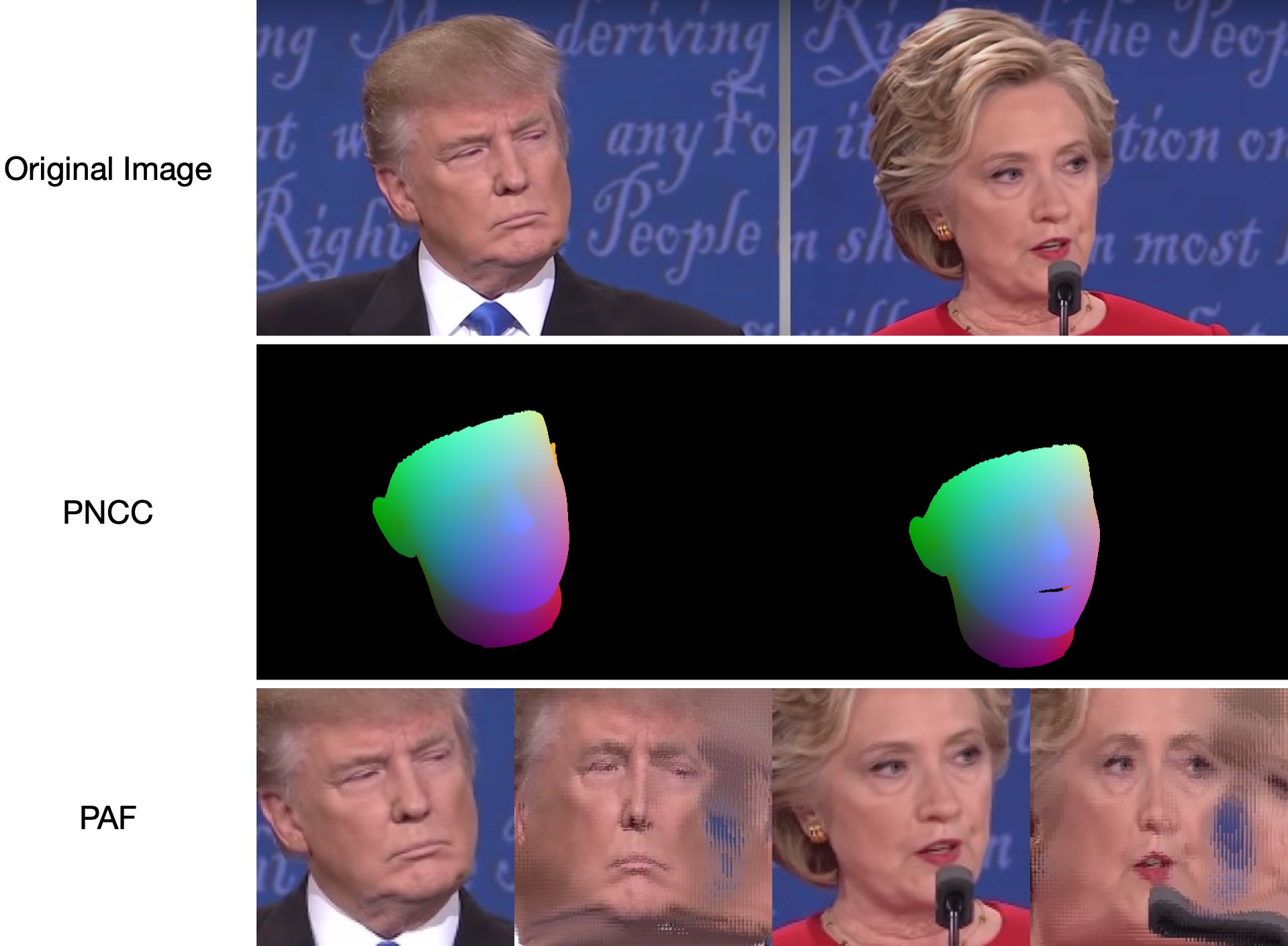
Поскольку test1.jpg имеет две грани, прогнозируются два файла .ply и .obj (которые могут быть визуализированы с помощью Meshlab или Microsoft 3D Builder). Глубина, PNCC, PAF и оценка позы по умолчанию установлены как true. Запустите python3 main.py -h или просмотрите код для получения более подробной информации.
samples/test1_3DDFA.jpg и samples/test1_pose.jpg показаны ниже:

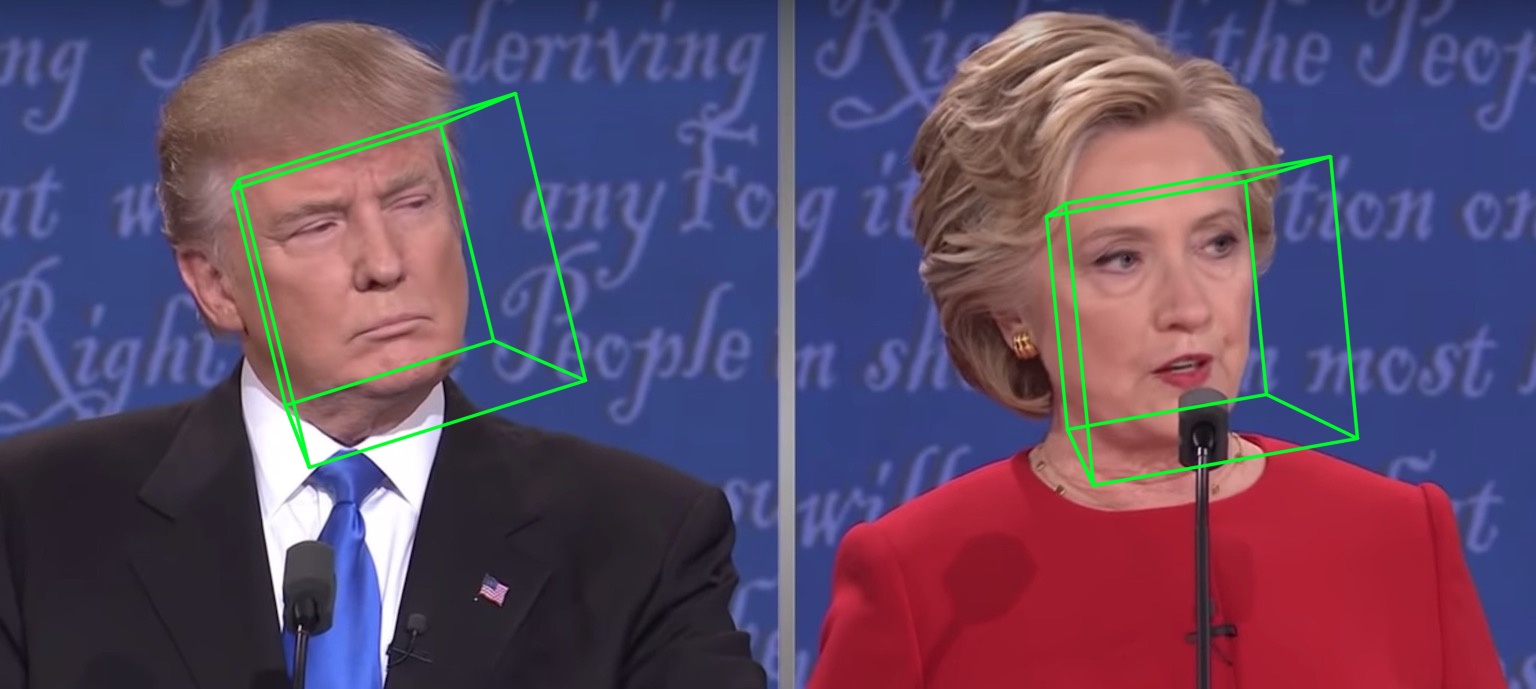
Дополнительный пример
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
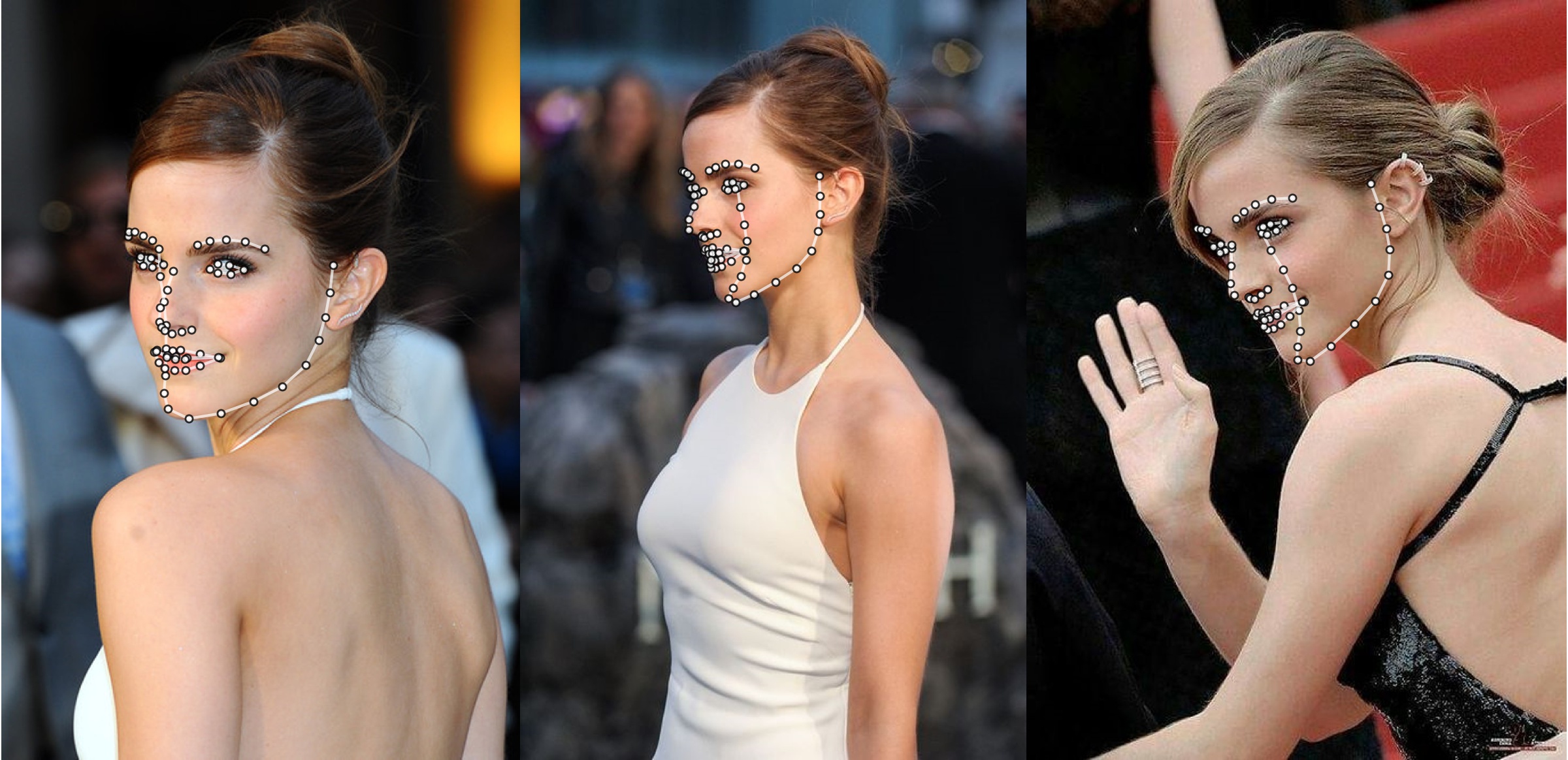
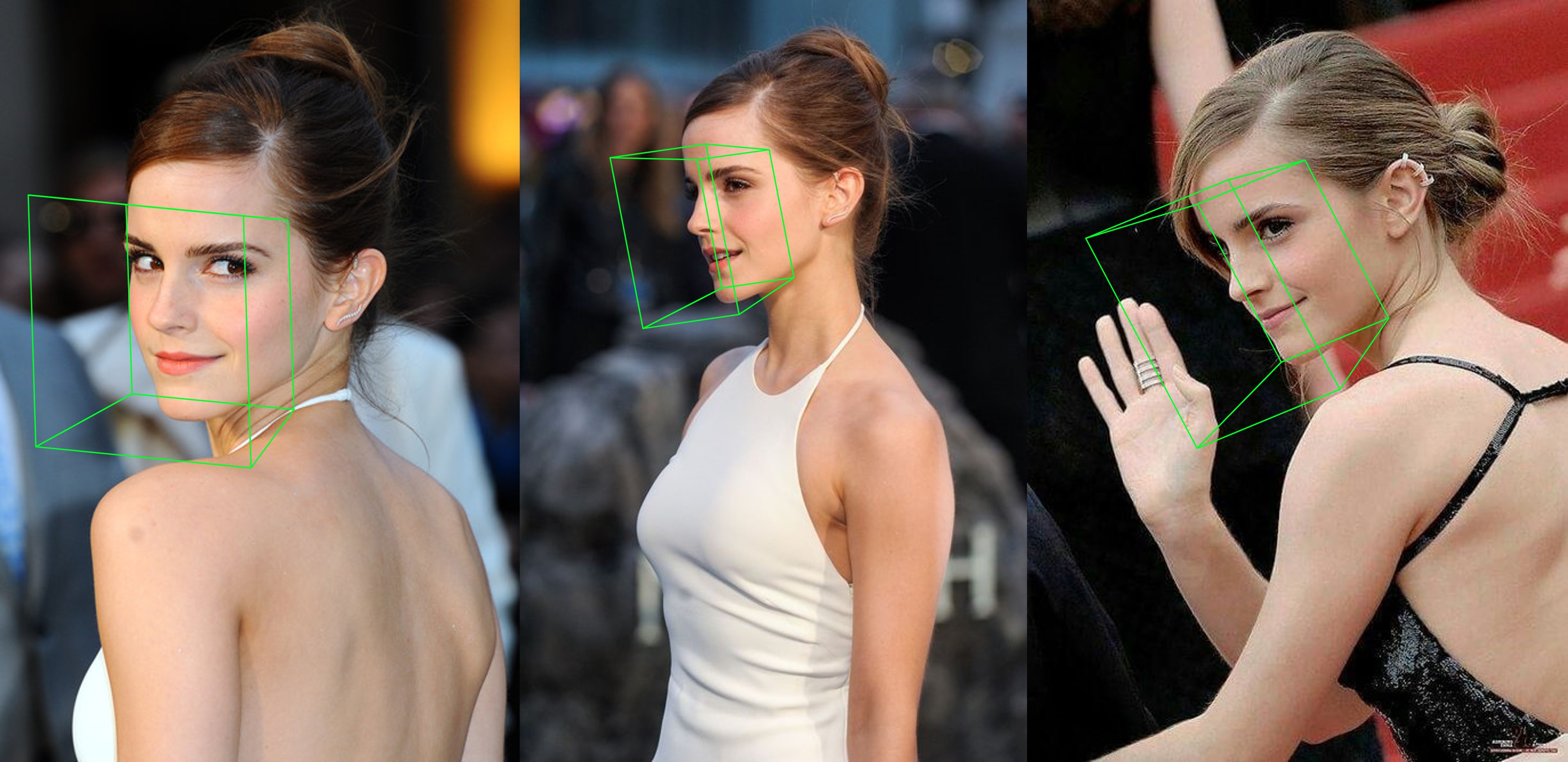
Просто беги
python3 speed_cpu.py
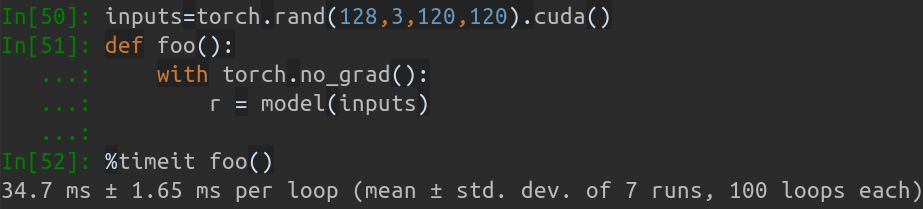
На моем MBP (процессор i5-8259U с частотой 2,30 ГГц на 13-дюймовом MacBook Pro) на базе PyTorch v1.1.0 с одним входом рабочий вывод:
Inference speed: 14.50±0.11 ms
Когда размер входного пакета равен 128, общее время вывода MobileNet-V1 занимает около 34,7 мс. Средняя скорость составляет около 0,27 мс/рис .
Сценарии обучения лежат в каталоге training . Соответствующие ресурсы приведены в таблице ниже.
| Данные | Ссылка для скачивания | Описание |
|---|---|---|
| поезд.конфигурации | BaiduYun или Google Drive, 217M | Каталог, содержащий параметры 3DMM и списки файлов набора обучающих данных. |
| train_aug_120x120.zip | BaiduYun или Google Диск, 2,15G | Обрезанные изображения набора данных для обучения дополнению |
| test.data.zip | BaiduYun или Google Drive, 151M | Обрезанные изображения тестового набора AFLW и ALFW-2000-3D. |
После подготовки набора обучающих данных и файлов конфигурации перейдите в каталог training и запустите сценарии bash для обучения. train_wpdc.sh , train_vdc.sh и train_pdc.sh — примеры обучающих сценариев. После настройки наборов обучения и тестирования просто запустите их для обучения. Возьмем, к примеру, train_wpdc.sh , как показано ниже:
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
Конкретные параметры обучения представлены в сценариях bash, включая скорость обучения, размер мини-пакета, эпохи и т. д.
Сначала вам следует загрузить обрезанный набор тестов ALFW и ALFW-2000-3D в test.data.zip, затем разархивировать его и поместить в корневой каталог. Затем запустите тестовый код, указав путь к обученной модели. Я уже предоставил пять предварительно обученных моделей в каталоге models (см. таблицу ниже). Эти модели обучаются с использованием различных потерь на первом этапе. Размер модели составляет около 13 МБ из-за высокой эффективности структуры MobileNet-V1.
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
Ниже показаны характеристики предварительно обученных моделей. На первом этапе эффективность различных потерь находится в порядке: WPDC > VDC > PDC. В то время как стратегия с использованием VDC для точной настройки WPDC дает наилучший результат.
| Модель | ВФЛВ (21 очко) | AFLW 2000-3D (68 баллов) | Ссылка для скачивания |
|---|---|---|---|
| Phase1_pdc.pth.tar | 6,956±0,981 | 5,644±1,323 | Baidu Yun или Google Диск |
| Phase1_vdc.pth.tar | 6,717±0,924 | 5,030±1,044 | Baidu Yun или Google Диск |
| Phase1_wpdc.pth.tar | 6,348±0,929 | 4,759±0,996 | Baidu Yun или Google Диск |
| Phase1_wpdc_vdc.pth.tar | 5,401±0,754 | 4,252±0,976 | В этом репо. |
Поверьте мне, что структура этого репозитория может обеспечить более высокую производительность, чем PRNet, без увеличения вычислительного бюджета. Сопутствующая работа находится на рассмотрении, и код будет выпущен после принятия.
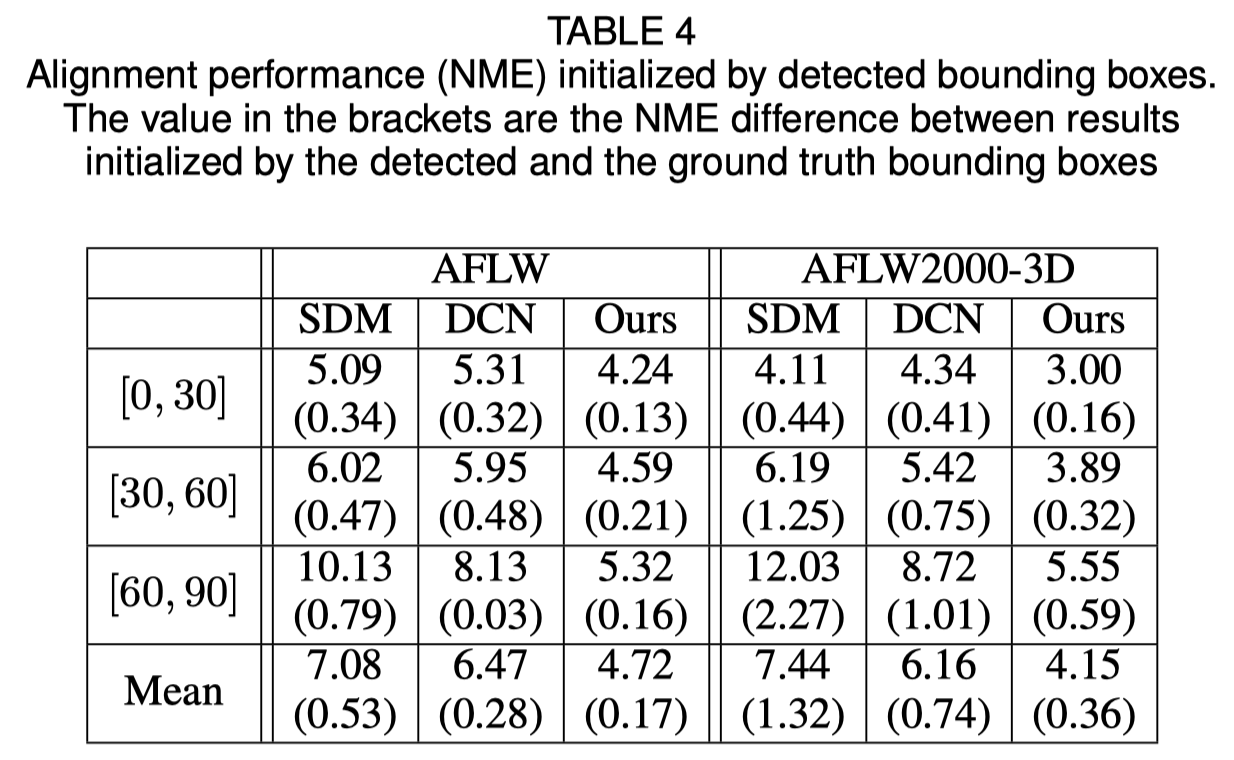
Инициализация ограничивающей рамки грани
В оригинальной статье показано, что использование обнаруженной ограничивающей рамки вместо основной истинной рамки приведет к небольшому падению производительности. Таким образом, текущий метод обрезки лица является самым надежным. Количественные результаты показаны в таблице ниже.
Реконструкция лица
Текстура невидимой области искажается из-за самозатенения, поэтому невидимая область лица может выглядеть странно (немного ужасно).
Об обрезке параметров формы и выражения
Обрезание параметров ускоряет обучение и реконструкцию, но снижает точность, особенно таких деталей, как закрытие глаз. Ниже приведено изображение с размерами параметров 40+10, 60+29 и 199+29 (исходное). По сравнению с формой, обрезка выражений оказывает большее влияние на точность реконструкции, когда задействованы эмоции. Таким образом, вы можете выбрать компромисс между скоростью/размером параметра и точностью. Рекомендуемый компромиссный вариант отсечения — 60+29.

Спасибо за интерес к этому репо. Если это репозиторий принесет пользу вашей работе или исследованию, отметьте его?
Добро пожаловать, чтобы сосредоточиться на моих работах, связанных с 3D-лицами: MeGlass и Face Anti-Spoofing.
Если ваша работа получит пользу от этого репозитория, пожалуйста, укажите три нагрудника ниже.
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Цзяньчжу Го (郭建珠) [Домашняя страница, Google Scholar]: [email protected] или [email protected] .


