similarity
1.1.6
сходство, вычисление показателя сходства между текстовыми строками, написанное на Java.
Сходство, набор инструментов для расчета сходства, может использоваться для расчета сходства текста, анализа настроений и т. д., написанного на Java.
Сходство — это Java-версия набора инструментов для расчета сходства, состоящая из ряда алгоритмов. Целью является распространение метода расчета сходства при обработке естественного языка. Сходство характеризуется практичными инструментами, эффективной работой, четкой структурой, современным корпусом и возможностью настройки.
Сходство обеспечивает следующие функциональные возможности:
Расчет сходства слов
Расчет сходства фраз
Расчет сходства предложений
Расчет сходства абзацев
ЦНКИ Июань
анализ настроений
Приблизительные слова
Предоставляя богатые функции, внутренние модули Likeity настаивают на низкой связанности, модели настаивают на отложенной загрузке, а словари настаивают на публикации в виде простого текста. Они просты в использовании и помогают пользователям обучать свои собственные корпуса.
Представляем пакет Jar
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >Введение градиента:
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}Длина текста: детализация слов
Рекомендуется использовать сходство Cilin: org.xm.Similarity.cilinSimilarity , который представляет собой метод расчета сходства, основанный на синонимах Cilin.
пример: src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
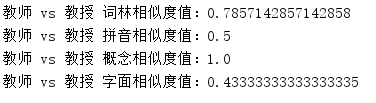
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
Длина текста: Детализация фразы
Рекомендуется использовать сходство фраз: org.xm.Similarity.phraseSimilarity , которое по сути является методом вычисления сходства двух фраз по одинаковым символам и позициям одинаковых символов.
пример: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
Длина текста: детализация предложения
Рекомендуется использовать сходство предложений по форме слов и порядку слов: org.xm.similarity.morphoSimilarity , метод сходства, который не только рассматривает один и тот же текстовый литерал двух предложений, но также учитывает порядок, в котором появляется один и тот же текст.
пример: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
Длина текста: степень детализации абзаца (абзац, 25 символов < длина (текст) < 500 символов)
Рекомендуется использовать сходство предложений в форме слов, порядке слов: org.xm.similarity.text.CosineSimilarity , метод, который рассматривает один и тот же текст в двух абзацах, взвешивает его с помощью сегментации слов, частоты слов и веса части речи, а также использует косинус для вычисления сходства.
пример: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875пример: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}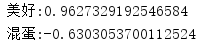
Этот пример представляет собой детальный анализ полярности настроений на основе деревьев семем. Что касается анализа тональности текста, существует pytextclassifier, который использует модели глубоких нейронных сетей и алгоритмы классификации SVM для достижения лучших результатов.
пример: src/test/java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

Обучение векторам слов Word2vec — это Java-версия инструмента обучения word2vec Word2VEC_java. Обучающий корпус представляет собой новый текст Tian Long Ba Bu, а синонимы получаются с помощью векторов слов. Пользователи могут обучать собственный корпус или использовать китайскую Википедию для обучения универсальных векторов слов.
Мера сходства текста

Лицензионное соглашение — это лицензия Apache 2.0, которая бесплатна для коммерческого использования. Пожалуйста, прикрепите ссылку на аналог и лицензионное соглашение к описанию продукта.
Код проекта все еще очень сырой. Если у вас есть какие-либо улучшения кода, вы можете отправить его обратно в этот проект. Перед отправкой обратите внимание на следующие два момента:
testЗатем вы можете отправить PR.


