cherche
2.2.1
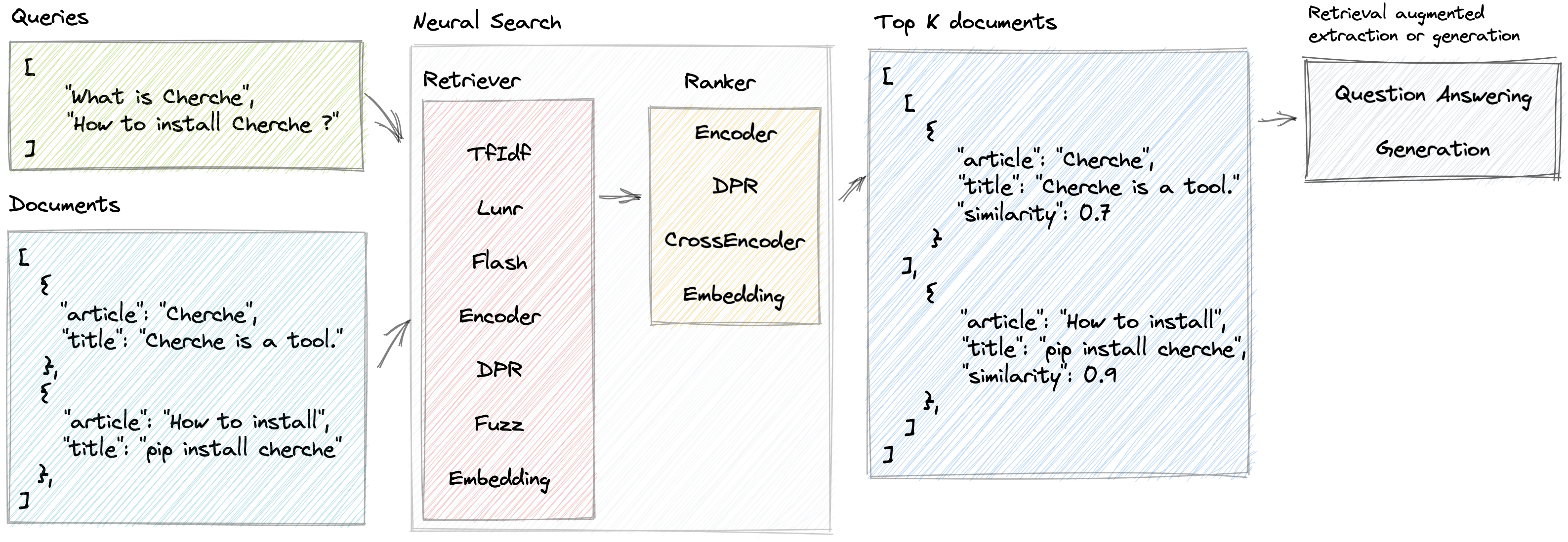
Нейронный поиск

Cherche позволяет разработать нейронный поисковый конвейер, в котором ретриверы и предварительно обученные языковые модели используются как в качестве ретриверов, так и в качестве ранжировщиков. Основное преимущество Cherche заключается в ее способности строить сквозные трубопроводы. Кроме того, Cherche хорошо подходит для автономного семантического поиска благодаря совместимости с пакетными вычислениями.
Вот некоторые возможности, которые предлагает Cherche:
Живая демонстрация поисковой системы НЛП на базе Cherche
Чтобы установить Cherche для использования с простым ретривером на ЦП, например TfIdf, Flash, Lunr, Fuzz, используйте следующую команду:
pip install chercheЧтобы установить Cherche для использования с любым семантическим ретривером или ранкером на ЦП, используйте следующую команду:
pip install " cherche[cpu] "Наконец, если вы планируете использовать какой-либо семантический ретривер или ранкер на графическом процессоре, используйте следующую команду:
pip install " cherche[gpu] "Следуя этим инструкциям по установке, вы сможете использовать Cherche с соответствующими требованиями для ваших нужд.
Документация доступна здесь. Он предоставляет подробную информацию о ретриверах, ранкерах, конвейерах и примерах.
Cherche позволяет находить нужный документ в списке объектов. Вот пример корпуса.
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]Вот пример нейронного поискового конвейера, состоящего из TF-IDF, который быстро извлекает документы, а затем модели ранжирования. Модель ранжирования сортирует документы, созданные программой извлечения, на основе семантического сходства между запросом и документами. Мы можем вызвать конвейер, используя список запросов, и получить соответствующие документы для каждого запроса.
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]Мы можем сопоставить индекс с документами для доступа к их содержимому с помощью конвейеров:
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]Cherche предоставляет средства извлечения, которые фильтруют входные документы на основе запроса.
Cherche предоставляет ранкеры, которые фильтруют документы в результатах поиска.
Ранкеры Cherche совместимы с моделями SentenceTransformers, которые доступны в центре Hugging Face.
Cherche предоставляет модули, посвященные ответам на вопросы. Эти модули совместимы с предварительно обученными моделями Hugging Face и полностью интегрированы в нейронные поисковые конвейеры.
Cherche был создан для Renault и теперь доступен всем. Мы приветствуем все вклады.

Lunr ретривер — это оболочка Lunr.py. Flash-ретривер — это оболочка FlashText. Ранкеры DPR, Encode и CrossEncoder — это оболочки, предназначенные для использования предварительно обученных моделей SentenceTransformers в конвейере нейронного поиска.
Если вы используете cherche для получения результатов для своей научной публикации, обратитесь к нашей статье SIGIR:
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}В команду разработчиков Cherche входят Рафаэль Сурти, Франсуа-Поль Серван, Николя Биццозеро, Хосе Дж. Морено. ?


