genai_robotics
1.0.0
Этот репозиторий содержит экспериментальную установку с учетом конфиденциальности для использования генеративных методов искусственного интеллекта в управлении робототехникой. Благодаря представленному здесь решению пользователь может свободно определять действия голосом, которые преобразуются в планы, которые робот-пылесос может выполнять в среде открытого мира, наблюдаемой камерой.
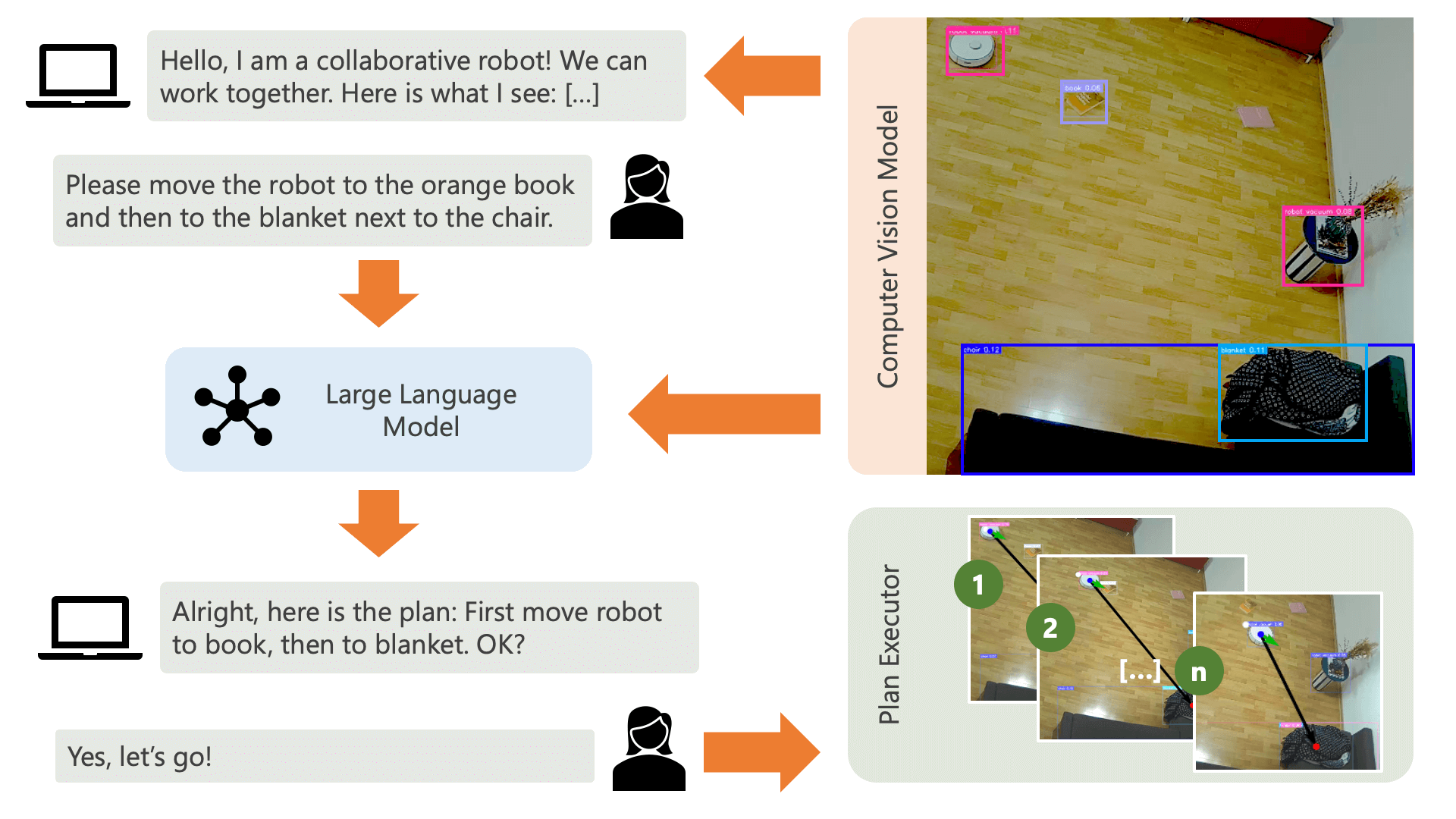
Принципиальными преимуществами представленных здесь методов являются:
Система была разработана в ходе трехдневного хакатона в качестве обучающего упражнения и доказательства концепции того, что современные инструменты искусственного интеллекта могут значительно сократить время разработки решений для управления робототехникой.
Чтобы использовать все возможности этого репозитория, вам необходимо иметь следующее:
Чтобы начать, выполните следующие действия:
requirements.txt в среду Python (тестируется с Python 3.11).src/config.template.toml в config.toml . Для всех шагов, описанных ниже, вставьте полученные учетные данные в config.tomlpython-roborock .src/run.py чтобы запустить рабочий процесс. Лучший способ понять, что делает этот репозиторий в деталях и как взаимодействуют элементы, — это диаграмма архитектуры:
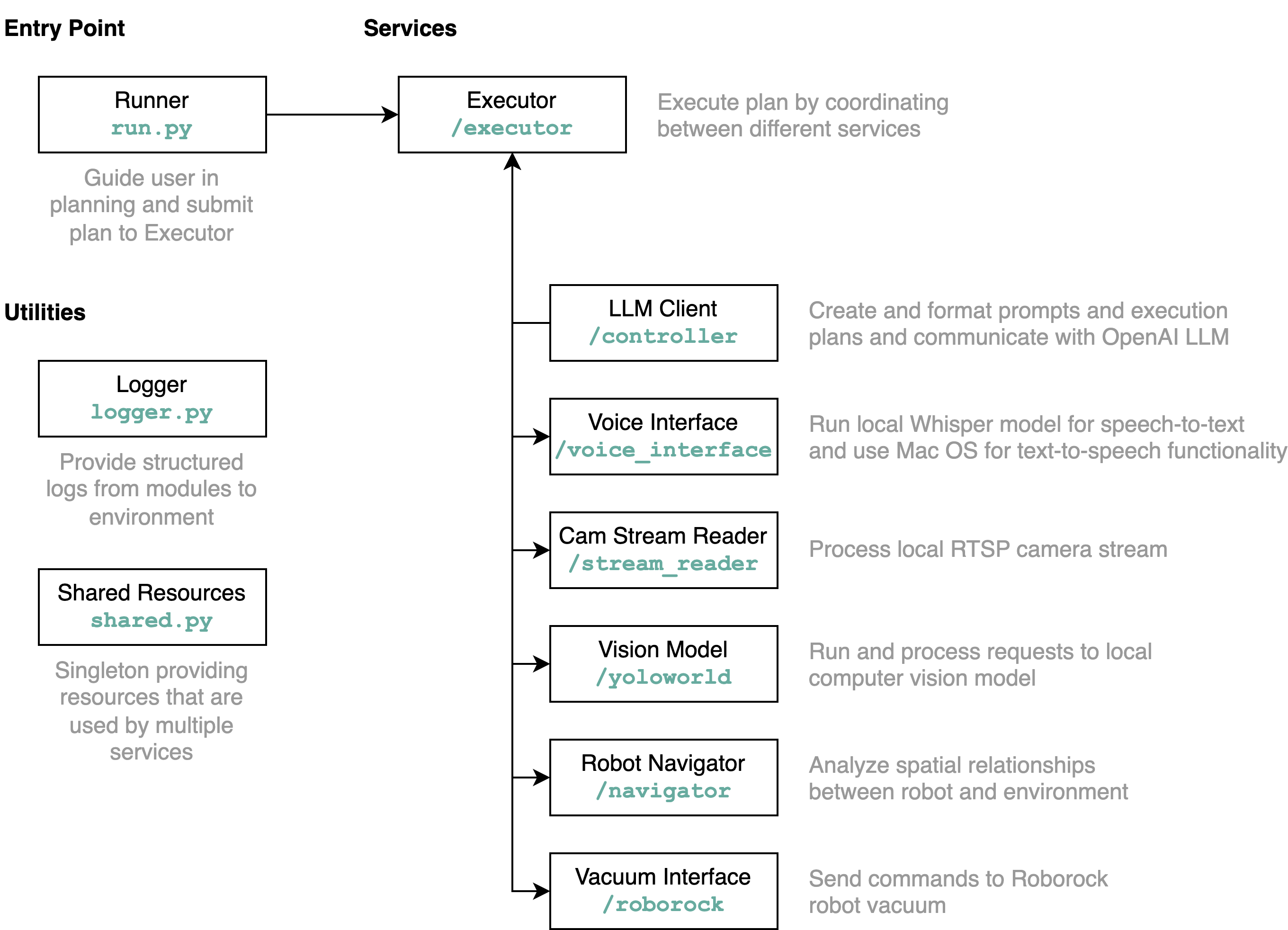
Когда вы запускаете файл run.py , как описано выше, вот что происходит и как это работает:
Система приветствует пользователя звуковым сообщением и ожидает, что он сообщит системе, что хочет сделать. Например, пользователь может захотеть, чтобы робот забрал кофе у человека, сидящего на желтом стуле, и перенес его другому человеку, сидящему на черном диване. Затем система создаст план выполнения этих действий.
Что нужно системе, чтобы понять, как она может достичь того, чего хочет пользователь? Система должна знать о своей среде и действиях, которые могут быть выполнены в этой среде. Здесь мы используем модель компьютерного зрения с обнаружением объектов, чтобы предоставить системе информацию об окружающей среде. Сам пылесос может выполнять 3 простых действия: двигаться вперед, поворачиваться и ничего не делать. Другое действие в среде ожидает выполнения пользователем определенного действия.
Чтобы избежать путаницы со стороны пользователя, важно, чтобы пользователь знал, как ИИ воспринимает окружающую среду. Например, если объект не распознается моделью компьютерного зрения, ИИ не сможет включить его в план. Также важно, чтобы пользователь осознавал, что существует неопределенность в отношении распознавания моделей. Используя большую языковую модель OpenAI GPT-4o с подсказкой описания, система предлагает объяснение своей среды и читает его пользователю непосредственно перед тем, как спросить пользователя, что он хочет от системы.
Учитывая информацию об окружающей среде и вводимые пользователем данные о том, что они хотят делать, система может затем разработать план. Здесь мы просим LLM разработать план, учитывая данные пользователя и описание окружающей среды. Вы можете найти шаблон приглашения в каталоге controller . Интересный трюк здесь заключается в том, что LLM знает о своей среде только через две таблицы, которые генерируются на основе результатов модели компьютерного зрения. Вот пример:
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
После того как LLM обработал запрос на планирование, он выводит две вещи: обоснование и план. Прежде чем система приступит к выполнению плана, она будет использовать подсказку с объяснением для создания краткого описания плана с целью получения подтверждения от пользователя о том, что план соответствует тому, что он просил сделать. Это соответствует духу подхода «человек в цикле», когда мы действуем с точки зрения того, что в реальной, открытой, физической среде люди потенциально могут пострадать от действий ИИ, поэтому разумно требовать человеческого вмешательства. обратная связь, прежде чем ИИ приступит к выполнению любого плана, который он придумал сам.
После подтверждения пользователем система приступает к выполнению плана. Такой план, созданный LLM, может выглядеть следующим образом:
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
] С помощью executor система выполняет план шаг за шагом. Чтобы сократить время, необходимое для настройки, управление роботом осуществляется по простому, неточному, но эффективному алгоритму:
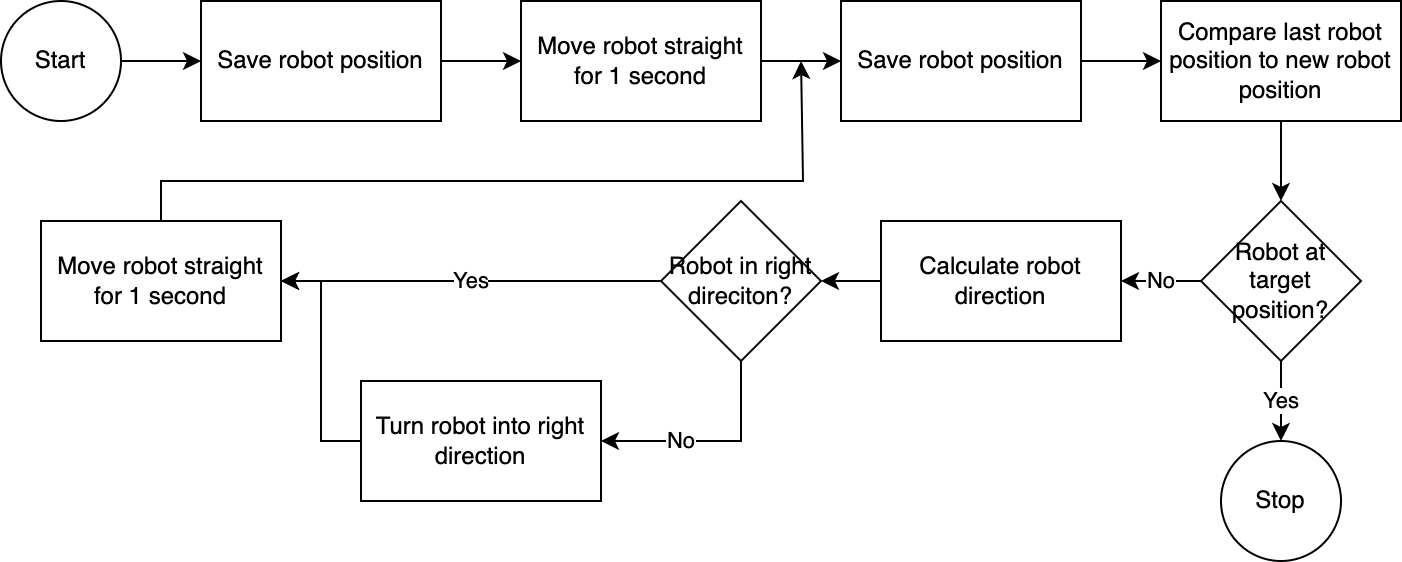
Система компьютерного зрения оценивает положение робота. С помощью кода в модуле navigator анализируется и сравнивается положение робота относительно его целевого положения и относительно его последнего известного положения. Этот подход несовершенен, поскольку не учитываются положение и искажения объектива камеры. Углы, измеренные с помощью этого подхода, являются неточными. Однако, поскольку система итеративна, ошибки часто компенсируются. Однако стоит отметить, что за это приходится платить скоростью. Система работает медленно, так как требуется время для анализа изображения, расчета пути и информирования робота о следующих шагах.
Как только робот достигает целевой позиции, исполнитель переходит к следующему этапу плана. Для действий, в которых задействован пользовательский ввод, исполнитель будет использовать функции преобразования текста в речь и преобразования речи в текст для взаимодействия с пользователем.
В этой системе мы в основном используем сервисы, работающие на локальном компьютере или в сети. Исключением является GPT-4o. Мы отправляем текстовые данные в модель OpenAI через Интернет. Текстовые данные включают в себя расшифрованные вводимые пользователем данные и таблицу распознанных объектов. Единственная причина, по которой мы здесь используем GPT-4o, заключается в том, что это одна из лучших моделей, доступных на момент хакатона — мы также можем запустить локальный LLM, а затем полноценно работать без подключения к Интернету, сохраняя конфиденциальность среди всего потока операции.
Модель компьютерного зрения, включенная в этот репозиторий, была создана моделью YOLO-World в пространстве HuggingFace со следующей подсказкой: chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human . Если вы хотите распознавать дополнительные объекты, измените подсказку и загрузите модель ONNX через это место. Затем вы можете заменить модель в каталоге src/yoloworld/models/rev0 .
Обратите внимание: для правильного извлечения модели необходимо вручную изменить параметры Максимальное количество полей и пороговое значение оценки в пространстве HuggingFace перед экспортом модели.
Вы можете узнать больше о захватывающей модели YOLO-World, основанной на последних достижениях в области моделирования языка видения, на веб-сайте YOLO-World.
Этот проект опубликован под лицензией MIT.
Этот репозиторий активно не контролируется, и нет намерения его расширять — это, прежде всего, учебное упражнение. Однако, если вы чувствуете вдохновение, не стесняйтесь внести свой вклад в проект, открыв выпуск GitHub или запрос на включение.


