full stack on prem cv mlops
1.0.0
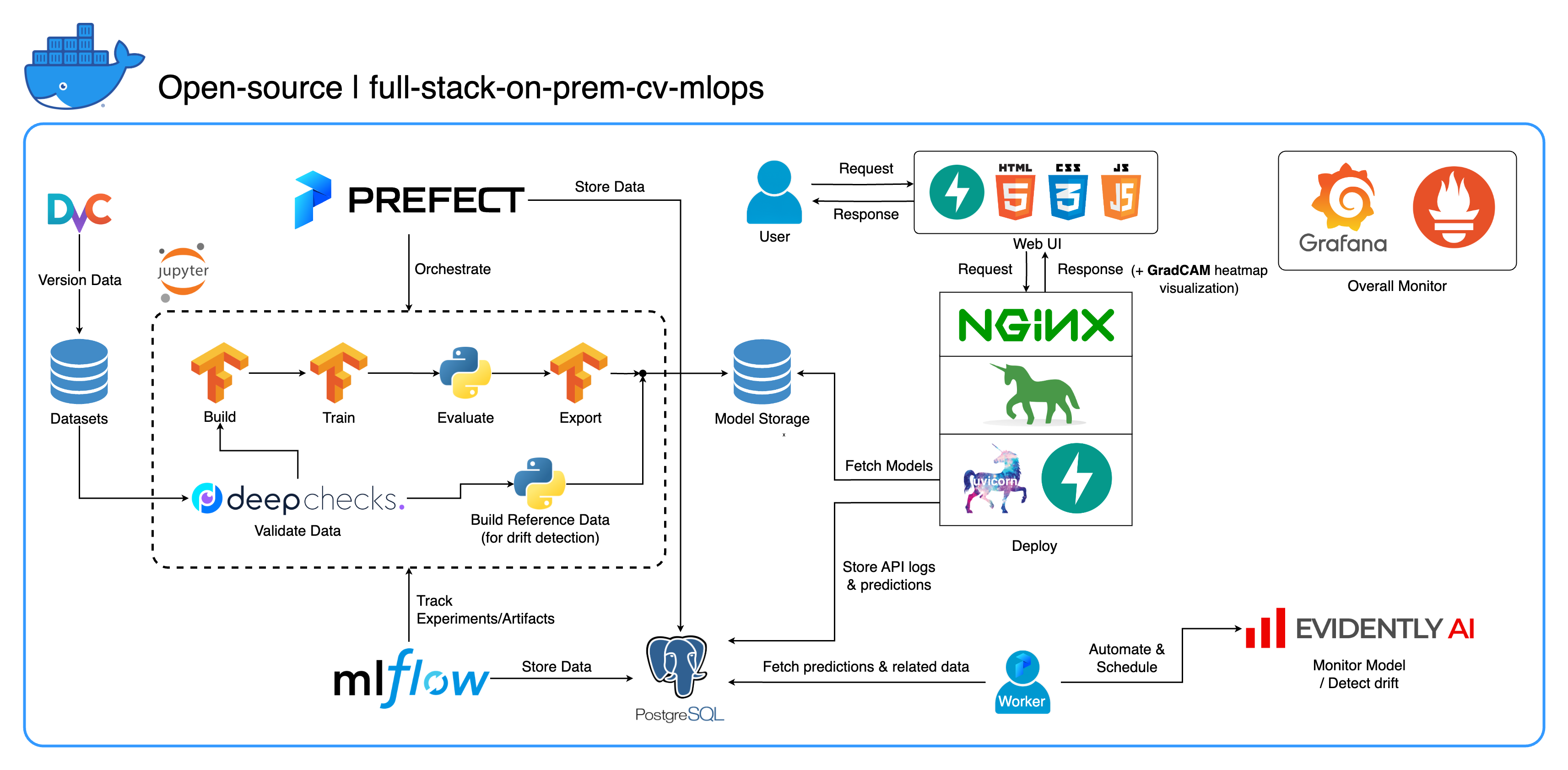
Добро пожаловать в нашу комплексную локальную экосистему MLOps, разработанную специально для задач компьютерного зрения с упором на классификацию изображений. Этот репозиторий предоставляет вам все необходимое: от рабочей области разработки в Jupyter Lab/Notebook до сервисов производственного уровня. Лучшая часть? Для запуска всей системы от построения модели до развертывания требуется всего лишь «1 конфигурация и 1 команда» ! Мы внедрили множество передовых методов, чтобы обеспечить масштабируемость и надежность, сохраняя при этом гибкость. Хотя наш основной вариант использования связан с классификацией изображений, структуру нашего проекта можно легко адаптировать к широкому спектру разработок ML/DL, даже при переходе от локальной среды к облаку!
Другая цель — показать, как интегрировать все эти инструменты и заставить их работать вместе в одной полноценной системе. Если вас интересуют конкретные компоненты или инструменты, смело выбирайте то, что соответствует потребностям вашего проекта.
Вся система упакована в один файл Docker Compose. Чтобы настроить его, все, что вам нужно сделать, это запустить docker-compose up ! Это полностью локальная система, что означает отсутствие необходимости в облачной учетной записи, и использование всей системы не будет стоить вам ни копейки !
Мы настоятельно рекомендуем посмотреть демонстрационные видеоролики в разделе «Демо-видео», чтобы получить полное представление и понять, как применять эту систему в ваших проектах. Эти видеоролики содержат важные детали, которые могут быть слишком длинными и недостаточно ясными, чтобы их можно было осветить здесь.
Демо: https://youtu.be/NKil4uzmmQc
Подробное техническое описание: https://youtu.be/l1S5tHuGBA8.
Ресурсы в видео:
Чтобы использовать этот репозиторий, вам нужен только Docker. Для справки мы используем Docker версии 24.0.6, сборку ed223bc и Docker Compose версии v2.21.0-desktop.1 на Mac M1.
В этом проекте мы внедрили несколько лучших практик:
tf.data для TensorFlowimgaug lib для большей гибкости в параметрах увеличения, чем основные функции из TensorFlow.os.env для важных конфигураций или конфигураций уровня обслуживания.logging вместо print.env для переменных в docker-compose.ymldefault.conf.template для Nginx для элегантного применения переменных среды в конфигурации Nginx (новая функция в Nginx 1.19)Большинство портов можно настроить в файле .env в корне этого репозитория. Вот значения по умолчанию:
123456789 )[email protected] , пароль: SuperSecurePwdHere )admin , пароль: admin ) Вам необходимо прокомментировать эти строки platform: linux/arm64 в docker-compose.yml если вы не используете компьютер на базе ARM (мы используем Mac M1 для разработки). В противном случае эта система не будет работать.
--recurse-submodules в вашей команде: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdeploy в сервисе jupyter в docker-compose.yml и изменить базовый образ в services/jupyter/Dockerfile с ubuntu:18.04 на nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (текст есть в файле, нужно только закомментировать и раскомментировать) чтобы использовать ваши графические процессоры. Вам также может потребоваться установить nvidia-container-toolkit на хост-компьютер, чтобы он работал. Для пользователей Windows/WSL2 эта статья оказалась очень полезной.docker-compose up или docker-compose up -d чтобы отсоединить терминал.datasets/animals10-dvc и следуйте инструкциям в разделе «Как использовать» . http://localhost:8888/labcd ~/workspace/docker-compose.yml ) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamltasksflows .run_flow.py в корне репо.start(config) в вашем файле потока. Эта функция принимает конфигурацию как словарь Python, а затем вызывает конкретный поток в этом файле.datasets , и все они должны иметь ту же структуру каталогов, что и внутри этого репозитория.central_storage в ~/ariya/ должен содержать как минимум 2 подкаталога с именами models и ref_data . Это central_storage служит для хранения объектов, храня все промежуточные файлы, которые будут использоваться в средах разработки и развертывания. (Это одна из вещей, которую вы могли бы рассмотреть при переходе на службу облачного хранения, если вы хотите развернуть ее в облаке и сделать ее более масштабируемой.)ВАЖНО Соглашения должны быть ОЧЕНЬ ОСТОРОЖНЫ, если вы хотите изменить их (потому что эти вещи связаны и используются в разных частях системы):
central_storage -> Внутри должны быть подкаталоги models/ ref_data/<model_name>.yaml , <model_name>_uae , <model_name>_bbsd , <model_name>_ref_data.parquetcurrent_model_metadata_file и monitor_pool_namecomputer-viz-dl (значение по умолчанию) со всеми необходимыми пакетами для этого репозитория. Предполагается, что все команды/коды Python должны выполняться в этом Jupyter.central_storage действует как центральное хранилище файлов, используемое на протяжении всей разработки и развертывания. В основном он содержит файлы моделей (включая детекторы дрифта) и справочные данные в формате Parquet. В конце этапа обучения модели здесь сохраняются новые модели, и служба развертывания извлекает модели из этого места. ( Примечание : это идеальное место для замены облачными службами хранения для обеспечения масштабируемости.)model в конфигурации, чтобы построить модель классификатора. Модель построена с помощью TensorFlow , а ее архитектура жестко запрограммирована в tasks/model.py:build_model .dataset в конфигурации, чтобы подготовить набор данных для обучения. DvC используется на этом этапе для проверки согласованности данных на диске по сравнению с версией, указанной в конфиге. Если есть изменения, он программно преобразует их обратно в указанную версию. Если вы хотите сохранить изменения, в случае, если вы экспериментируете с набором данных, вы можете установить для поля dvc_checkout в конфигурации значение false , чтобы DvC не выполнял свои функции.train в конфигурации, чтобы создать загрузчик данных и начать процесс обучения. Информация об экспериментах и артефакты отслеживаются и регистрируются с помощью MLflow . Примечание. Отчет о результатах (в файле .html ) из DeepChecks также загружается в обучающий эксперимент на MLflow для соглашения.model в конфигурации.central_storage (в данном случае это просто копирование в папку central_storage . Это шаг, который вы можете изменить для загрузки файлов в облачное хранилище).model/drift_detection в конфигурации.central_storage .central_storage .central_storage . (это одна из проблем, обсуждаемых в демонстрационном видеоролике, посмотрите его для более подробной информации)current_model_metadata_file , в которых хранится имя файла метаданных модели, заканчивающееся на .yaml , monitor_pool_name в которых хранится имя рабочего пула для развертывания рабочего процесса и потоков Prefect.cd к deployments/prefect-deployments и запустите prefect --no-prompt deploy --name {deploy_name} используя входные данные из раздела deploy/prefect в конфигурации. Поскольку в этом репозитории все уже доккеризовано и контейнеризировано, преобразовать сервис из локального в облачный довольно просто. Когда вы закончите разработку и тестирование API вашего сервиса, вы можете просто выделить сервисы/dl_service , создав контейнер из его Dockerfile, и отправить его в службу реестра облачных контейнеров (например, AWS ECR). Вот и все!
Примечание. В коде службы есть одна потенциальная проблема, если вы хотите использовать его в реальной производственной среде. Я рассмотрел это в подробном видео и рекомендую вам потратить некоторое время на просмотр всего видео. 
У нас есть три базы данных внутри PostgreSQL: одна для MLflow, одна для Prefect и одна, которую мы создали для нашего сервиса моделей ML. Мы не будем углубляться в первые два, поскольку они управляются этими инструментами самостоятельно. База данных для нашего сервиса моделей машинного обучения — это база данных, которую мы разработали сами.
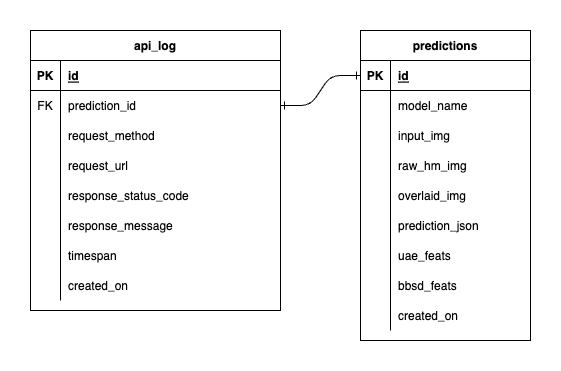
Чтобы избежать чрезмерной сложности, мы упростили задачу, ограничив ее двумя таблицами. Отношения и атрибуты показаны в ERD ниже. По сути, мы стремимся хранить важную информацию о входящих запросах и ответах нашей службы. Все эти таблицы создаются и обрабатываются автоматически, поэтому вам не нужно беспокоиться о ручной настройке.
Примечательно: input_img , raw_hm_img и overlaid_img — это изображения в кодировке Base64, хранящиеся в виде строк. uae_feats и bbsd_feats — это массивы встроенных функций для наших алгоритмов обнаружения дрейфа.
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block , попробуйте export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0 а затем перезапустите файл сценарий.

