genkitx hnsw
1.0.0

Вы можете внести свой вклад в этот плагин в этом репозитории.
HNSW — это векторная база данных. Иерархические навигационные графы Small World (HNSW) входят в число наиболее эффективных индексов для поиска сходства векторов. HNSW — чрезвычайно популярная технология, которая снова и снова обеспечивает высочайшую производительность с супербыстрой скоростью поиска и фантастическим отзывом. узнать больше о HNSW.
Вы можете предпочесть эту векторную базу данных, если хотите.
Благодаря этому вы можете добиться высокопроизводительной генерации с поисковым расширением (RAG) в генеративном ИИ, поэтому вам не нужно создавать свою собственную модель ИИ или переобучать модель ИИ, чтобы получить больше контекста или знаний, вместо этого вы можете добавить дополнительный уровень контекста, чтобы ваша модель ИИ может понимать больше знаний, чем знает базовая модель ИИ. это полезно, если вы хотите получить больше контекста или больше знаний на основе конкретной информации или знаний, которые вы определяете.
У вас есть приложение или веб-сайт ресторана, вы можете добавить конкретную информацию о ваших ресторанах, адресе, списке меню блюд с ценой и другими конкретными вещами, чтобы, когда ваш клиент спросит что-то у ИИ о вашем ресторане, ваш ИИ мог точно ответить на него. . это может отбросить ваши усилия по созданию чат-бота, вместо этого вы можете использовать генеративный искусственный интеллект, обогащенный конкретными знаниями.
Пример разговора:
You : Каков прайс-лист моего ресторана в Сурабае?
AI : Прайс-лист:
Перед установкой плагина убедитесь, что у вас установлены следующие необходимые компоненты:
npm install -g typescript )Чтобы установить этот плагин, вы можете запустить эту команду или с помощью предпочитаемого вами менеджера пакетов.
npm install genkitx-hnswЭтот плагин имеет несколько функций, как показано ниже:
HNSW Indexer Используется для создания векторного индекса на основе всех предоставленных вами данных и информации. этот векторный указатель будет использоваться в качестве справочника по HNSW Retriever.HNSW Retriever Используется для получения генеративного ответа ИИ с моделью Близнецов в качестве основы, обогащенной дополнительными знаниями и контекстом на основе вашего векторного индекса. Это использование потока плагинов Genkit для сохранения данных в векторное хранилище с помощью HNSW Vector Store, Gemini Embedder и Gemini LLM.
Подготовьте свои данные или документы в папке 
Импортируйте плагин в свой проект Genkit.
import { hnswIndexer } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: " GOOGLE_API_KEY " })
]
}) ; Откройте пользовательский интерфейс Genkit и выберите зарегистрированный плагин HNSW Indexer
Выполнить поток с обязательным параметром ввода и вывода.
dataPath : путь к вашим данным и другим документам, который будет изучен ИИ.indexOutputPath : ожидаемый выходной путь для индекса векторного хранилища, который обрабатывается на основе предоставленных вами данных и документов. 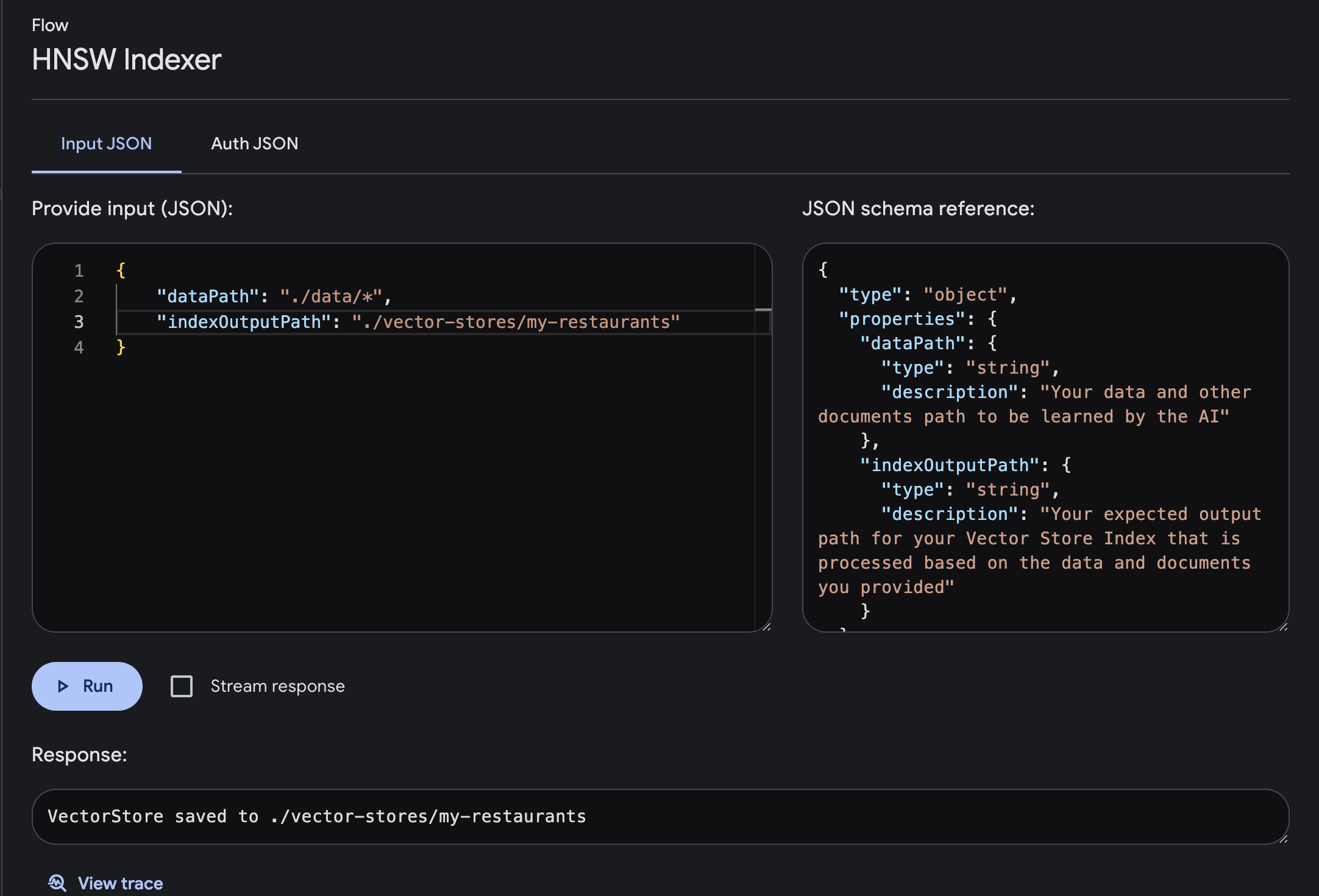
 Хранилище векторов будет сохранено в указанном пути вывода. этот индекс будет использоваться для процесса генерации подсказок с помощью плагина HNSW Retriever. вы можете продолжить реализацию, используя плагин HNSW Retriever
Хранилище векторов будет сохранено в указанном пути вывода. этот индекс будет использоваться для процесса генерации подсказок с помощью плагина HNSW Retriever. вы можете продолжить реализацию, используя плагин HNSW Retriever
chunkSize: number Сколько данных обрабатывается за раз. Это похоже на разбиение большой задачи на более мелкие части, чтобы сделать ее более управляемой. Устанавливая размер фрагмента, мы решаем, какой объем информации ИИ обрабатывает за один раз, что может повлиять как на скорость, так и на точность процесса обучения ИИ.
default value : 12720
separator: string При создании вектора индекс — это символ или символ, используемый для разделения различных фрагментов информации во входных данных. Это помогает ИИ понять, где заканчивается одна единица данных и начинается другая, что позволяет ему более эффективно обрабатывать данные и учиться на их основе.
default value : "n"
Это использование потока плагинов Genkit для обработки вашего приглашения с помощью модели Gemini LLM, обогащенной дополнительной и конкретной информацией или знаниями в предоставленной вами базе данных векторов HNSW. с помощью этого плагина вы получите ответ LLM с дополнительным конкретным контекстом.
Импортируйте плагин в свой проект Genkit.
import { googleAI } from " @genkit-ai/googleai " ;
import { hnswRetriever } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
googleAI (),
hnswRetriever({ apiKey: " GOOGLE_API_KEY " })
]
}) ;Обязательно импортируйте плагин GoogleAI для поставщика моделей Gemini LLM. В настоящее время этот плагин поддерживает только Gemini, скоро будет предоставлено больше моделей!
Откройте пользовательский интерфейс Genkit и выберите зарегистрированный плагин HNSW Retriever Выполните поток с необходимым параметром.
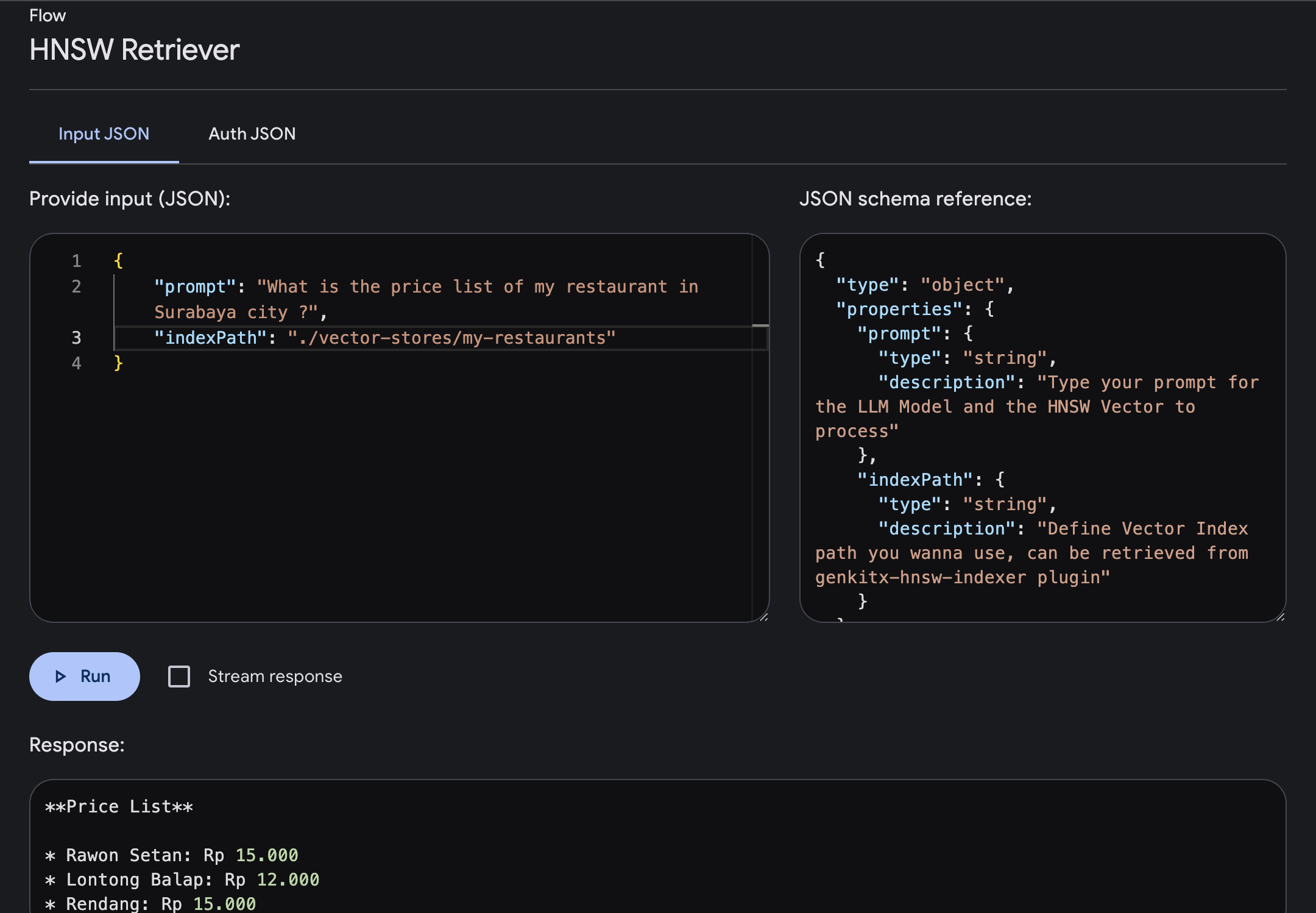
prompt : введите подсказку, в которой вы получите ответы с более расширенным контекстом на основе предоставленного вами вектора.indexPath : определите путь векторного индекса папки, который вы хотите использовать в качестве справочника знаний, где вы получите этот путь к файлам из плагина индексатора HNSW.В этом примере давайте попробуем запросить информацию о прайс-листе ресторана в городе Сурабая, где она была предоставлена в векторном индексе.
Мы можем ввести подсказку и запустить ее. После завершения потока вы получите ответ, обогащенный конкретными знаниями на основе вашего векторного индекса.
temperature: number температура контролирует случайность генерируемого вывода. Более низкие температуры приводят к более детерминированному результату: модель выбирает наиболее вероятный токен на каждом этапе. Более высокие температуры увеличивают случайность, позволяя модели исследовать менее вероятные токены, потенциально создавая более творческий, но менее связный текст.
default value : 0.1
maxOutputTokens: number Этот параметр указывает максимальное количество токенов (слов или подслов), которые модель должна генерировать за один шаг вывода. Это помогает контролировать длину сгенерированного текста.
default value : 500
topK: number выборок Top-K ограничивает выбор модели K наиболее вероятными токенами на каждом этапе. Это помогает предотвратить рассмотрение моделью слишком редких или маловероятных токенов, улучшая согласованность сгенерированного текста.
default value : 1
topP: number выборок Top-P, также известное как выборка ядра, учитывает совокупное распределение вероятностей токенов и выбирает наименьший набор токенов, чья совокупная вероятность превышает заранее определенный порог (часто обозначаемый как P). Это позволяет динамически выбирать количество токенов, рассматриваемых на каждом этапе, в зависимости от вероятности появления токенов.
default value : 0
stopSequences: string[] Это последовательности токенов, которые при создании сигнализируют модели о прекращении генерации текста. Это может быть полезно для управления длиной или содержимым сгенерированных выходных данных, например, для обеспечения прекращения генерации модели после достижения конца предложения или абзаца.
default value : []
Лицензия: Апач 2.0.


