cassandra lucene index
2.1.20.0
Индекс Cassandra Lucene от Stratio, созданный на основе Stratio Cassandra, представляет собой плагин для Apache Cassandra, который расширяет функциональные возможности индекса, обеспечивая поиск практически в реальном времени, такой как ElasticSearch или Solr, включая возможности полнотекстового поиска и бесплатный многопараметрический, геопространственный и битемпоральный поиск. Это достигается за счет реализации вторичных индексов Cassandra на основе Apache Lucene, где каждый узел кластера индексирует свои собственные данные. Индексы Cassandra компании Stratio являются одним из основных модулей, на которых основана платформа BigData компании Stratio.
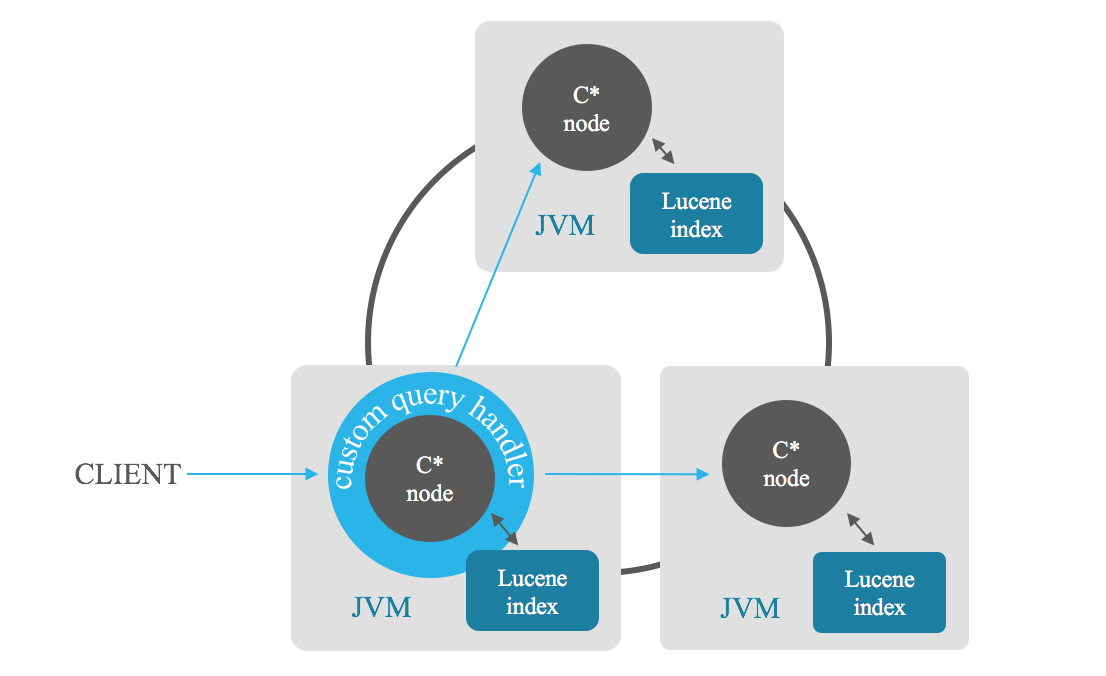
Поиск по релевантности индекса позволяет получить n более релевантных результатов, удовлетворяющих запросу. Узел-координатор отправляет поиск каждому узлу в кластере, каждый узел возвращает n лучших результатов, а затем координатор объединяет эти частичные результаты и выдает вам n лучших из них, избегая полного сканирования. Вы также можете основывать сортировку на комбинации полей.
Любая ячейка в таблицах может быть проиндексирована, в том числе в первичном ключе, а также в коллекциях. Также поддерживаются широкие строки. Вы можете сканировать диапазоны токенов/ключей, применять дополнительные предложения CQL3 и просматривать отфильтрованные результаты.
Поиск с фильтрацией по индексу является мощным подспорьем при анализе данных, хранящихся в Cassandra, с помощью инфраструктур MapReduce, таких как Apache Hadoop или, что еще лучше, Apache Spark. Добавление фильтров Lucene во входные данные заданий может значительно сократить объем обрабатываемых данных, избегая полного сканирования.
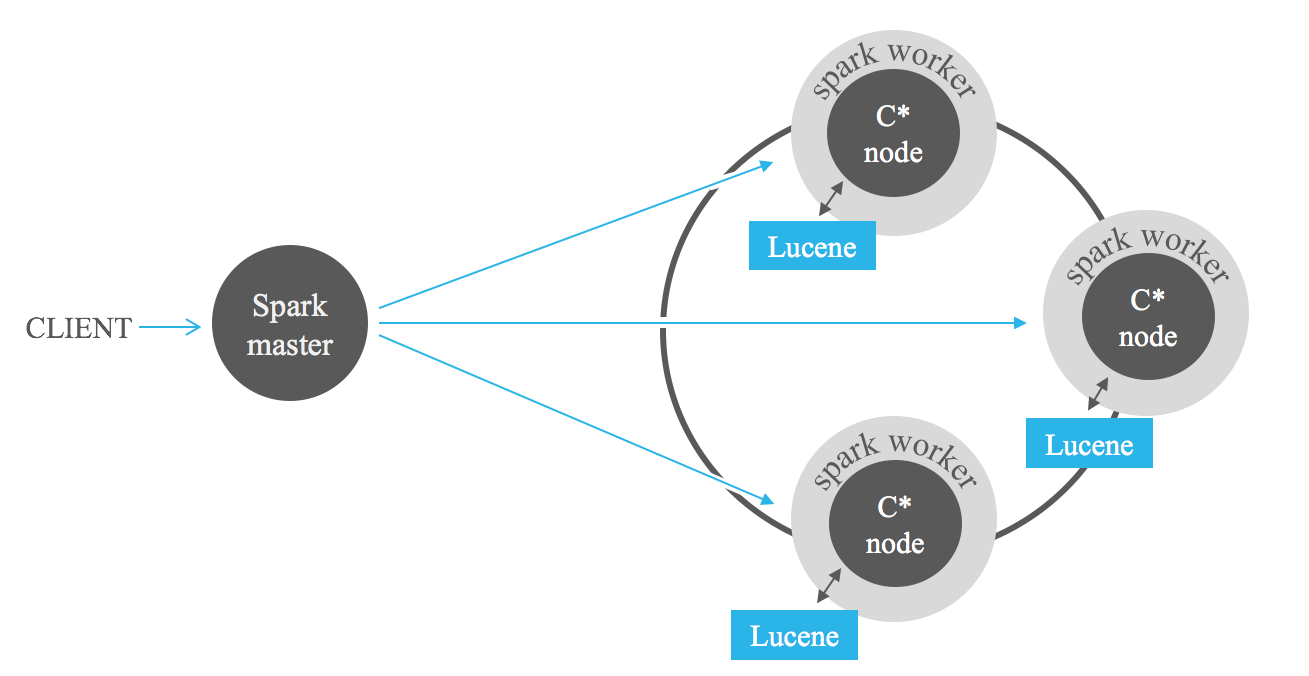
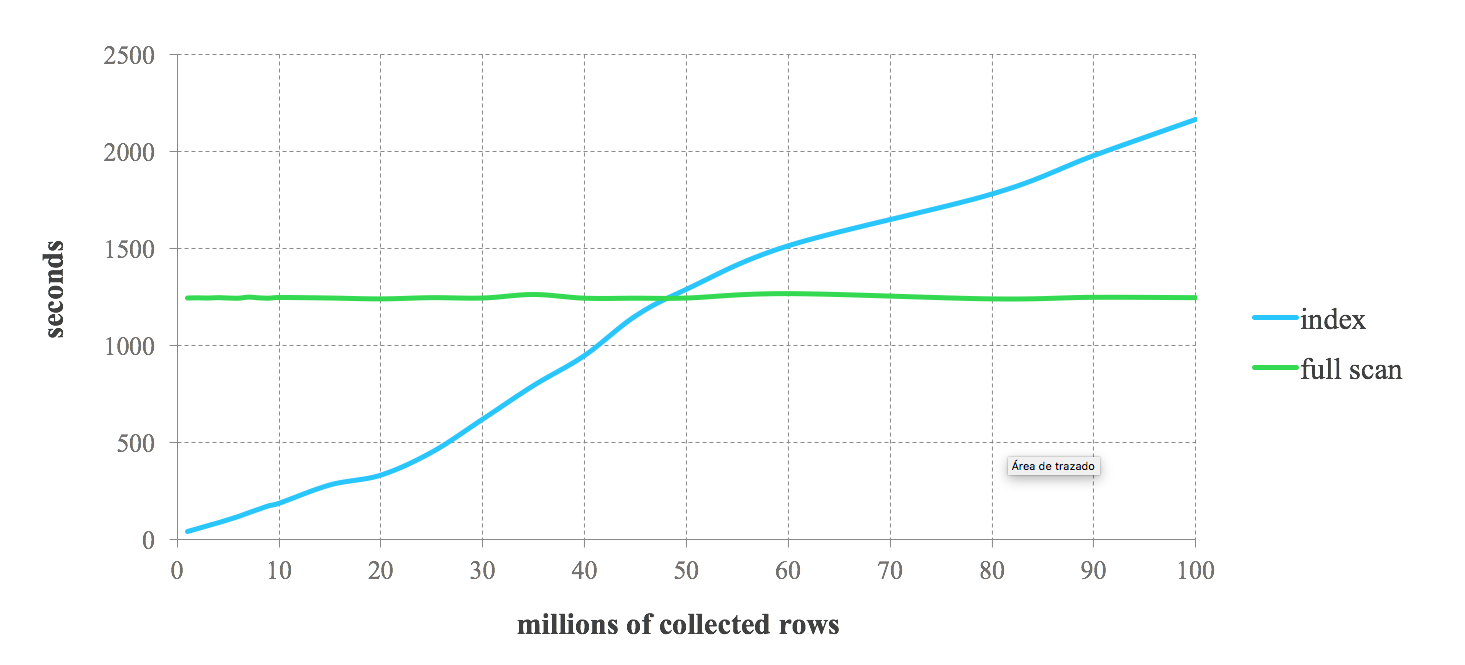
Следующий результат теста может дать вам представление об ожидаемой производительности при объединении индексов Lucene со Spark. Мы выполняем последовательные запросы, запрашивающие от 1% до 100% сохраненных данных. Мы видим высокую производительность индекса для запросов, запрашивающих строго отфильтрованные данные. Однако производительность снижается при менее строгих запросах. По мере увеличения количества записей, возвращаемых запросом, мы достигаем точки, когда индекс становится медленнее, чем полное сканирование. Таким образом, решение об использовании индексов в заданиях Spark зависит от избирательности запроса. Компромисс между обоими подходами зависит от конкретного варианта использования. Как правило, объединение индексов Lucene со Spark рекомендуется для заданий, извлекающих не более 25 % хранимых данных.
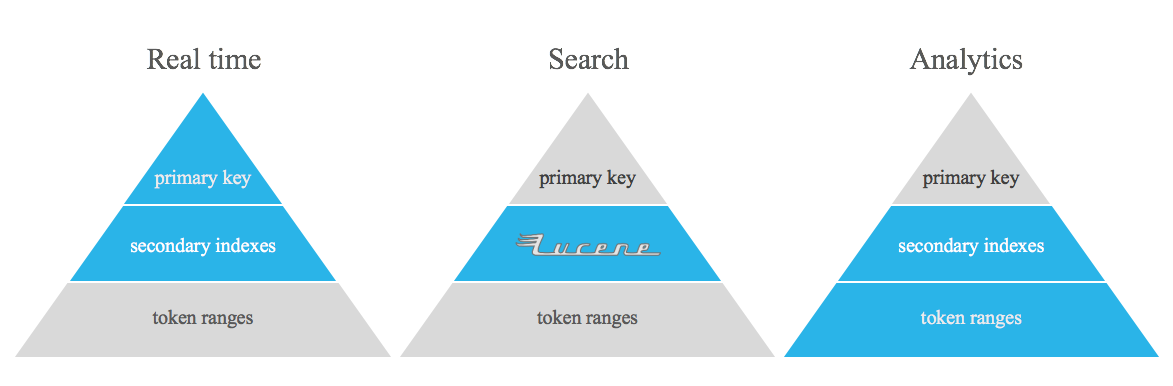
Этот проект не предназначен для замены денормализованных таблиц Apache Cassandra, инвертированных индексов и/или вторичных индексов. Это просто инструмент для выполнения каких-то запросов, которые действительно сложно решить с помощью готовых функций Apache Cassandra, заполняя разрыв между режимом реального времени и аналитикой.
Более подробную информацию можно найти в документации по индексу Cassandra Lucene компании Stratio.
Интеграция технологии поиска Lucene в Cassandra обеспечивает:
Индекс Cassandra Lucene от Stratio и его интеграция с поисковой технологией Lucene обеспечивают:
Еще не поддерживается:
counterИндекс Cassandra Lucene от Stratio распространяется как плагин для Apache Cassandra. Таким образом, вам просто нужно создать JAR-файл, содержащий плагин, и добавить его в путь к классам Cassandra:
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/Конкретные версии индекса Cassandra Lucene предназначены для конкретных версий Apache Cassandra. Итак, cassandra-lucene-index ABCX предназначен для использования с Apache Cassandra ABC, например cassandra-lucene-index:3.0.7.1 для cassandra:3.0.7. Обратите внимание, что готовые к выпуску выпуски имеют теги версий (например, 3.0.6.3), поэтому в производстве не используйте ни ветку X, ни главные ветки.
В качестве альтернативы исправление также можно выполнить с помощью этого профиля Maven, указав путь к вашей установке Cassandra. Эта задача также удаляет предыдущие версии JAR плагина в каталоге CASSANDRA_HOME/lib/:
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >Если у вас нет установленной версии Cassandra, существует также альтернативный профиль, позволяющий Maven загрузить и исправить подходящую версию Apache Cassandra:
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >Теперь вы можете запустить Cassandra и выполнить несколько тестов, используя язык запросов Cassandra:
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh Индексные файлы Lucene будут храниться в тех же каталогах, что и файлы Cassandra. Каталогом данных по умолчанию является /var/lib/cassandra/data , и каждый индекс размещается рядом с SSTables своего семейства индексированных столбцов.
Помните, что если вы используете поиск по географическим формам, вам необходимо включить JTS jar.
Более подробную информацию об Apache Cassandra можно найти в документации.
Мы создадим следующую таблицу для хранения твитов:
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);Теперь вы можете создать на нем собственный индекс Lucene с помощью следующего оператора:
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
}; При этом будут проиндексированы все столбцы таблицы с указанными типами, и она будет обновляться один раз в секунду. Альтернативно, вы можете явно обновить все сегменты индекса с помощью пустого поиска с согласованностью ALL :
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUMТеперь, чтобы найти твиты в определенном диапазоне дат:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );Тот же поиск можно выполнить, принудительно обновив задействованные фрагменты индекса:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;Теперь, чтобы выполнить поиск в 100 наиболее релевантных твитах, в которых поле тела содержит фразу «большие данные дают организациям» в вышеупомянутом диапазоне дат:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Чтобы уточнить поиск и получать только твиты, написанные пользователями, имена которых начинаются с буквы «а»:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Чтобы получить более 100 последних отфильтрованных результатов, вы можете использовать опцию сортировки :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;Предыдущий поиск можно ограничить твитами, созданными вблизи географического положения:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;Также есть возможность сортировать результаты по расстоянию до географического положения:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;И последнее, но не менее важное: вы можете направить любой поиск к определенному диапазону токенов или разделу таким образом, что будет затронута только подгруппа узлов кластера, что сэкономит драгоценные ресурсы:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;Последнее является основой для поддержки Hadoop, Spark и других платформ MapReduce.
Пожалуйста, обратитесь к подробной документации по индексу Cassandra Lucene от Stratio.


