ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
Введение на YouTube • Чат Discord • Полная документация
Установить UStore очень просто, а использовать его примерно так же просто, как dict Python.
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi' Мы только что создали встроенную в память транзакционную базу данных и добавили одну запись в ее main коллекцию. Вы бы предпочли, чтобы эти данные были на диске? Измените одну строку.
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )Предпочитаете ли вы подключиться к удаленному серверу UStore? UStore поставляется с RPC-интерфейсом Apache Arrow Flight!
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' ) Вы храните MultiDiGraph в стиле NetworkX? Или DataFrame в стиле Pandas?
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1Вызовы функций могут выглядеть одинаково, но базовая реализация может адресовать сотни терабайт данных, размещенных где-то в постоянной памяти на удаленном компьютере.
Кто-то еще одновременно обновляет эти коллекции? Объедините свои операции, чтобы гарантировать согласованность!
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )До сих пор мы рассмотрели только верхушку UStore. Вы можете использовать его для...
Но UStore может больше. Вот карта:
## Базовое использование
UStore задуман не просто как база данных, но как набор инструментов для «создания вашей базы данных» и открытый стандарт для потенциально транзакционных баз данных NoSQL, определяющий двоичные интерфейсы с нулевым копированием для операций «Создание, чтение, обновление, удаление» или для краткости CRUD.
Несколько простых заголовков C99 могут связать практически любой базовый механизм хранения с многочисленными языковыми драйверами высокого уровня, расширяя поддержку двоичных строковых значений на графики, документы с гибкой схемой и другие модальности, стремясь заменить MongoDB, Neo4J, Pinecone и ElasticSearch. с единой ACID-транзакционной системой.
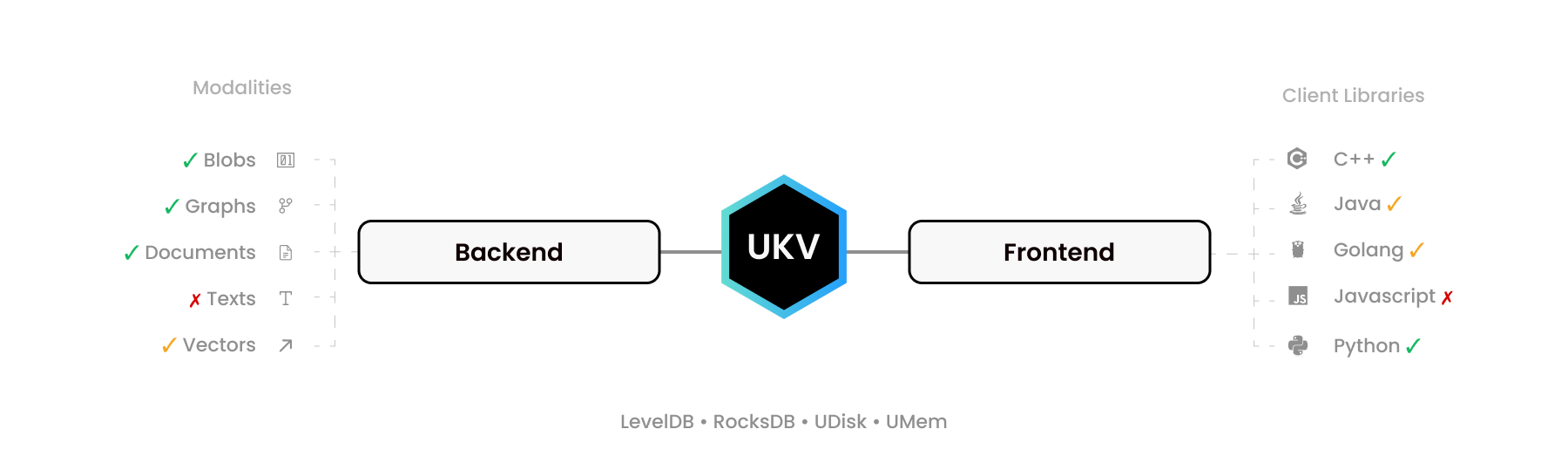
Redis, например, предоставляет RediSearch, RedisJSON и RedisGraph схожие цели. UStore делает это лучше, позволяя вам добавлять ваши любимые хранилища ключей-значений (KVS), встроенные, автономные или сегментированные, такие как FoundationDB, увеличивая их функциональность.
Большие двоичные объекты можно размещать внутри UStore. Производительность будет сильно различаться в зависимости от используемой базовой технологии. UCSet в памяти будет самым быстрым, но наименее подходящим для больших объектов. Постоянный UDisk при правильной настройке может полностью обойти ядро Linux, включая уровень файловой системы, напрямую обращаясь к блочным устройствам.
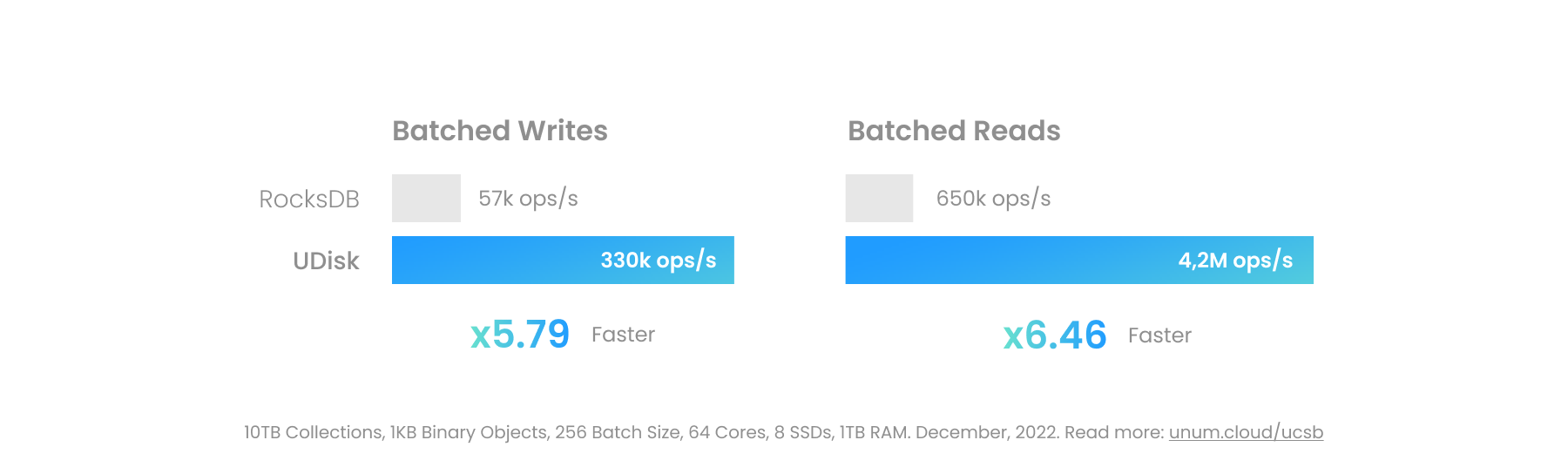
Современные постоянные операции ввода-вывода на высокопроизводительных серверах могут превышать 100 ГБ/с на сокет, если они созданы на основе драйверов пользовательского пространства, таких как SPDK. Это близко к реальной пропускной способности высокопроизводительной оперативной памяти и открывает новые, необычные для баз данных варианты использования. Теперь можно поместить видеофайл размером в гигабайт в транзакционную базу данных ACID, рядом с его метаданными, вместо использования отдельного хранилища объектов, такого как MinIO.
JSON в настоящее время является наиболее часто используемым форматом документов. Коллекции документов UStore поддерживают JSON, а также MessagePack и BSON, используемые MongoDB.

UStore пока не масштабируется горизонтально, но обеспечивает гораздо более высокую производительность на одном узле и имеет почти линейную вертикальную масштабируемость на многоядерных системах благодаря библиотекам simdjson и yyjson с открытым исходным кодом. Более того, для взаимодействия с данными вам не нужен специальный язык запросов, такой как MQL. Вместо этого мы отдаем приоритет открытым стандартам RFC, чтобы действительно избежать блокировок со стороны поставщиков:
Современные базы данных Graph, такие как Neo4J, справляются с большими рабочими нагрузками. Им требуется слишком много оперативной памяти, и их алгоритмы отслеживают данные по одной записи за раз. Мы оптимизируем по обоим направлениям:
Хранилища объектов и базы данных векторов, такие как Pinecone, Milvus и USearch, предоставляют автономные индексы для векторного поиска. UStore реализует его как отдельную модальность, наравне с документами и графиками. Функции:
UStore для Python и C++ выглядят совершенно по-разному. Наш Python SDK имитирует другие библиотеки Python — Pandas и NetworkX. Аналогично, библиотека C++ предоставляет интерфейс, который ожидают разработчики C++.
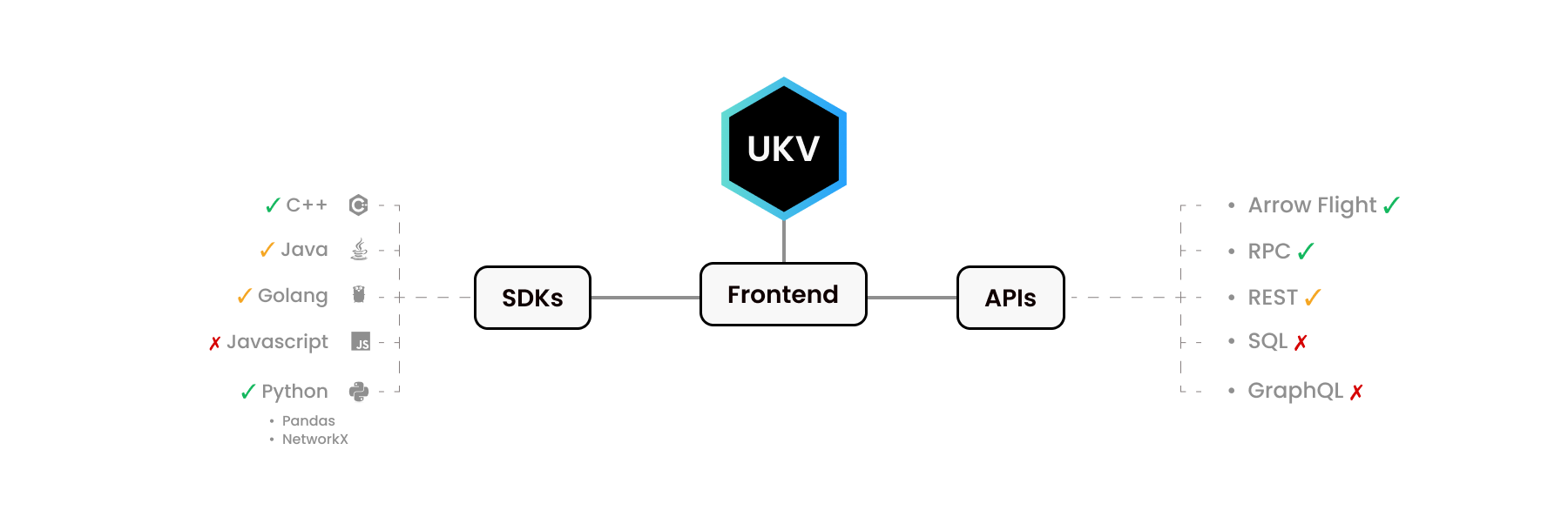
Как мы знаем, люди используют разные языки для разных целей. Некоторые функции уровня C не реализованы для некоторых языков. Либо потому, что на это не было спроса, либо мы до этого еще не дошли.
| Имя | Транзакция | Коллекции | Пакеты | Документы | Графики | Копии |
|---|---|---|---|---|---|---|
| C99 Стандарт | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| С++ SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| Python SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| GoLang SDK | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| Java SDK | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| API полета стрелы | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
Некоторые интерфейсы окружены целыми экосистемами! Например, Apache Arrow Flight API имеет собственные драйверы для C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby и Rust.
Следующие двигатели могут использоваться практически взаимозаменяемо. Исторически LevelDB был первым. RocksDB затем улучшил функциональность и производительность. Сейчас она служит основой для половины стартапов СУБД.
| УровеньБД | РоксДБ | UDisk | UCSet | |
|---|---|---|---|---|
| Скорость | 1x | 2x | 10x | 30x |
| Настойчивый | ✓ | ✓ | ✓ | ✗ |
| Транзакционный | ✗ | ✓ | ✓ | ✓ |
| Блокировать поддержку устройств | ✗ | ✗ | ✓ | ✗ |
| Шифрование | ✗ | ✗ | ✓ | ✗ |
| Часы | ✗ | ✓ | ✓ | ✓ |
| Снимки | ✓ | ✓ | ✓ | ✗ |
| Случайная выборка | ✗ | ✗ | ✓ | ✓ |
| Массовое перечисление | ✗ | ✗ | ✓ | ✓ |
| Именованные коллекции | ✗ | ✓ | ✓ | ✓ |
| Открытый исходный код | ✓ | ✓ | ✗ | ✓ |
| Совместимость | Любой | Любой | Линукс | Любой |
| Сопровождающий | Фейсбук | Унум | Унум |
UCSet и UDisk разработаны и поддерживаются компанией Unum. Оба являются полнофункциональными, но наиболее важной особенностью наших альтернатив является производительность. Быстро запоминать легко. Базовую логику UCSet можно найти в шаблонной библиотеке ucset , содержащей только заголовки.
Разработка UDisk была гораздо более сложной задачей, длившейся 7 лет. Оно включало в себя изобретение новых древовидных структур, реализацию частичного обхода ядра с помощью io_uring , полного обхода с помощью SPDK , ускорения графического процессора CUDA и даже собственной внутренней файловой системы. UDisk — первый движок, разработанный с нуля с учетом параллельных архитектур и обхода ядра .
Атомность всегда гарантирована. Даже при нетранзакционной записи — либо все обновления проходят, либо все завершаются сбоем.
Согласованность реализуется в самой строгой возможной форме — «Строгая сериализуемость», что означает, что:
Однако поведение по умолчанию можно настроить на уровне конкретных операций. Для этого ::ustore_option_transaction_dont_watch_k можно передать в ustore_transaction_init() или любую транзакционную операцию чтения/записи, чтобы контролировать проверки согласованности во время подготовки.
| Читает | Пишет | |
|---|---|---|
| Голова | Строгий сериал | Строгий сериал |
| Транзакции через снимки | Серийный | Строгий сериал |
| Транзакции без снимков | Строгий сериал | Строгий сериал |
| Транзакции без часов | Строгий сериал | Последовательный |
Если эта тема для вас нова, пожалуйста, посетите блог Jepsen.io, чтобы узнать о последовательности.
| Читает | Пишет | |
|---|---|---|
| Транзакции через снимки | ✓ | ✓ |
| Транзакции без снимков | ✗ | ✓ |
Надежность не применима к системам в памяти по определению. В гибридных или постоянных системах мы предпочитаем отключать его по умолчанию. Почти каждая СУБД, построенная на основе KVS, предпочитает реализовать собственный механизм устойчивости. Тем более в распределенных базах данных, где могут существовать три отдельных журнала упреждающей записи:
Если вам все еще нужна надежность, очистите записи при фиксации с помощью необязательного флага. В драйвере C вы должны вызвать ustore_transaction_commit() с флагом ::ustore_option_write_flush_k .
Вся СУБД помещается в образ Docker размером менее 100 МБ. Запустите следующий сценарий, чтобы получить и запустить контейнер, открыв сервер Apache Arrow Flight через порт 38709 . Клиентские SDK по умолчанию также будут обмениваться данными через тот же порт.
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustoreФайл конфигурации по умолчанию можно получить с помощью:
cat /var/lib/ustore/config.jsonСамый простой способ подключения и тестирования — это следующая команда:
python ...Предварительно упакованные изображения UStore доступны на нескольких платформах:
Не стесняйтесь коммерциализировать и распространять UStore.
Настройка баз данных – это не только наука, но и искусство. Такие проекты, как RocksDB, предоставляют десятки регуляторов для оптимизации поведения. Мы разрешаем пересылать специализированные файлы конфигурации в базовый движок.
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}У нас также есть более простая процедура, которой будет достаточно для 80% пользователей. Это можно расширить для использования нескольких устройств или каталогов или для пересылки специализированной конфигурации механизма.
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}Коллекции баз данных также можно настроить с помощью файлов JSON.
В текущей версии используются 64-битные целые числа со знаком. Он допускает уникальные ключи в диапазоне от [0, 2^63) . Скоро появятся 128-битные сборки с UUID, но использование ключей переменной длины крайне не рекомендуется. Почему так?
Использование ключей переменной длины налагает многочисленные ограничения на проектирование хранилища ключей-значений. Во-первых, это подразумевает медленные посимвольные сравнения — убийца производительности современных гиперскалярных процессоров. Во-вторых, он заставляет ключи и значения объединяться на диске, чтобы минимизировать количество метаданных, необходимых для навигации. Наконец, это нарушает наше простое логическое представление о KVS как о «постоянном распределителе памяти», возлагая на него гораздо больше ответственности.
Рекомендуемый подход к работе со строковыми ключами:
Это приведет к единой точке преобразования строковых представлений в целочисленные и сохранит большую часть скорости работы системы, а интерфейсы уровня C будут проще, чем они могли бы быть.
На данный момент мы можем адресовать только значения размером 4 ГБ или меньше. Почему? Хранилища ключей и значений обычно предназначены для высокочастотных операций. Часто (тысячи раз в секунду) доступ и изменение файлов размером 4 ГБ и более на современном оборудовании невозможны. Поэтому мы придерживаемся типов меньшей длины, что немного упрощает использование представления Apache Arrow и позволяет KVS лучше сжимать индексы.
Наша дорожная карта развития является общедоступной и размещена в репозитории GitHub. В число предстоящих задач входит:
Полный план действий можно прочитать в нашей документации здесь.


