aiwhispr
version 0.941
AIWhispr — это инструмент без кода или с низким уровнем кода для автоматизации конвейеров векторного внедрения для семантического поиска. Простая конфигурация управляет конвейером для чтения файлов, извлечения текста, создания векторных векторных изображений и их хранения в векторной базе данных.
AIWhispr

AIWhispr имеет коннекторы для следующих векторных баз данных
1 Кдрант
2 Милвус
3 Плетение
4 Тайпсенс
5 МонгоБД
6 Postgres — PGVector
Убедитесь, что вы установили и запустили базу данных векторов.
Переменная среды AIWHISPR_HOME_DIR должна содержать полный путь к каталогу aiwhispr.
Переменной среды AIWHISPR_LOG_LEVEL можно установить значение DEBUG/INFO/WARNING/ERROR.
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
Не забудьте добавить переменные среды в сценарий входа в оболочку.
Запустите команду ниже
$AIWHISPR_HOME/shell/install_python_packages.sh
Если установка uwsgi не удалась, убедитесь, что у вас установлены gcc, python-dev, python3-dev.
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr поставляется с приложением с потоковой подсветкой, которое поможет вам начать работу.
Запустите приложениеstreamlit
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
Это должно запустить приложениеStreamlit на порту по умолчанию 8501 и начать сеанс в вашем веб-браузере.
Чтобы настроить конвейер индексации вашего контента для семантического поиска, необходимо выполнить три шага.
1. Настройте чтение файлов из хранилища.
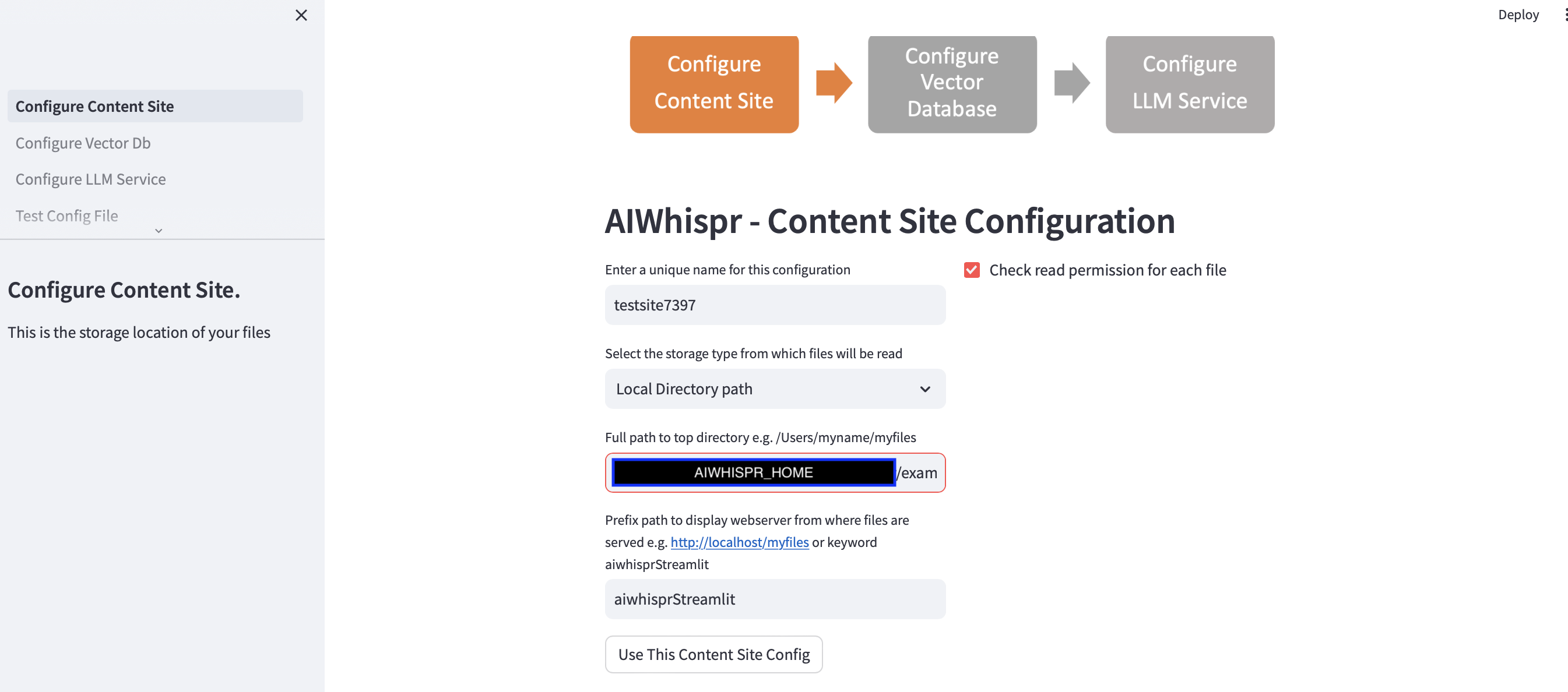
Вы можете продолжить настройку по умолчанию, нажав кнопку «Использовать эту конфигурацию сайта контента».
и перейдите к следующему шагу для настройки подключения к базе данных векторов.
В примере по умолчанию будут индексироваться новости BBC для семантического поиска.
Приложениеstreamlit предполагает, что вы запускаете новую конфигурацию, и назначает случайное имя конфигурации. Вы можете перезаписать это, чтобы дать ему более значимое имя. Имя конфигурации должно быть уникальным; он не может содержать пробелов или специальных символов.
Конфигурация по умолчанию будет считывать содержимое из локального каталога $AIWHISPR_HOME/examples/http/bbc.
Он содержит более 2000+ новостей BBC, которые индексируются для семантического поиска.
Вы можете читать контент, хранящийся в AWS S3, Azure Blob, Google Cloud Storage.
Конфигурация префиксного пути используется для создания веб-ссылок href для результатов поиска. Вы можете продолжить с ключевым словом по умолчанию «aiwhisprStreamlit».
Нажмите кнопку «Использовать эту конфигурацию сайта контента» и перейдите к следующему шагу, чтобы настроить подключение к базе данных векторов, нажав «Настроить базу данных векторов» на левой боковой панели.
2. Настройте векторную базу данных
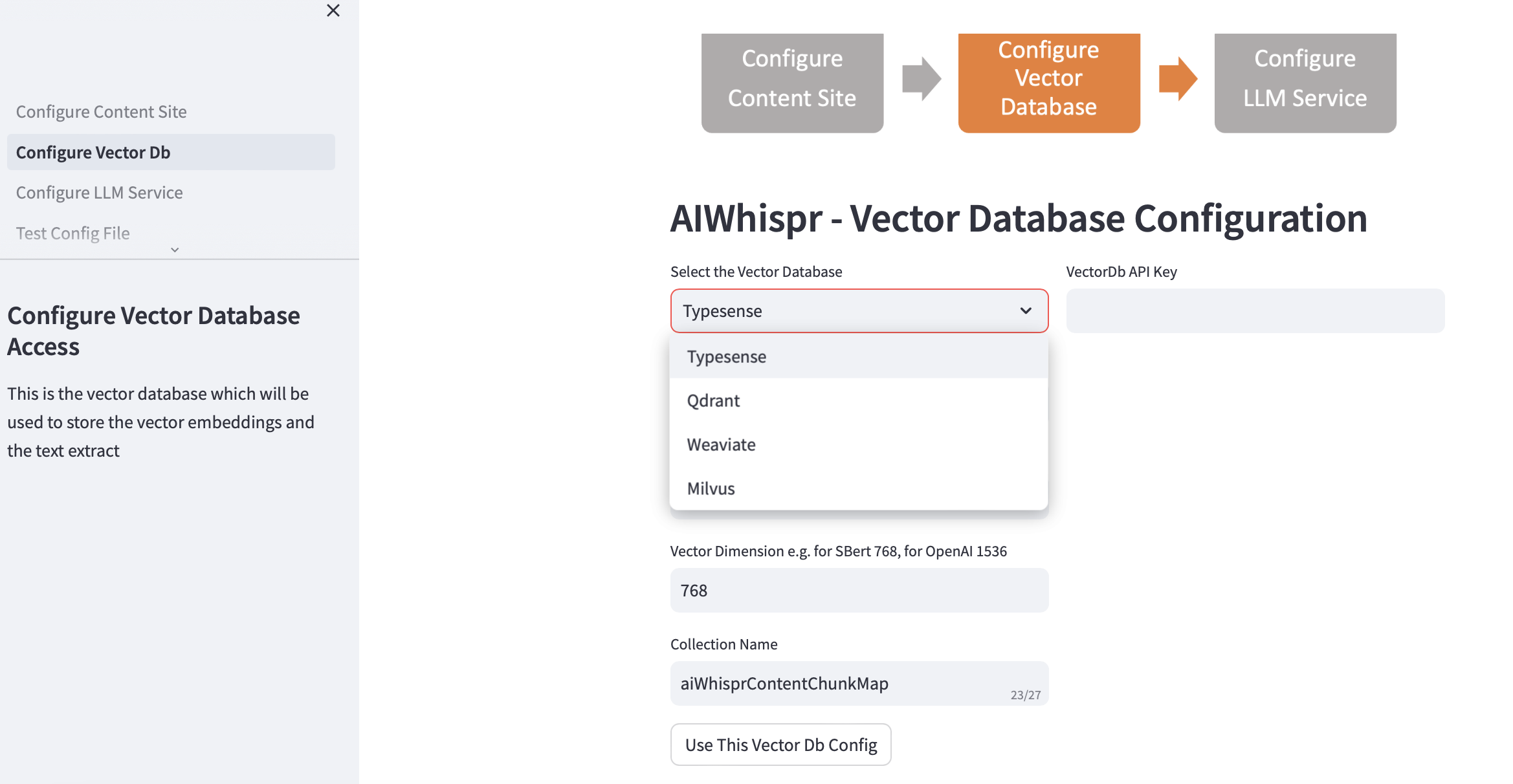
Выберите векторную базу данных и укажите сведения о соединении.
При выборе базы данных Vector IP-адрес базы данных Vector и номера портов заполняются на основе установок по умолчанию. Вы можете изменить это в зависимости от ваших настроек.
База данных векторов должна быть настроена для аутентификации. В случае Qdrant, Weaviate, Typesense требуется ключ API. Для Milvus необходимо настроить комбинацию идентификатора пользователя и пароля.
Размер векторного измерения следует указывать на основе LLM, который вы планируете использовать для кодирования текста в виде векторных вложений. Пример: для Open AI «text-embedding-ada-002» это значение должно быть настроено как 1536, что соответствует размеру вектора, возвращаемого службой внедрения OpenAI.
Имя коллекции по умолчанию, созданной в базе данных векторов, — aiwhisprContentChunkMap. Вы можете указать собственное название коллекции.
Нажмите кнопку «Использовать эту конфигурацию базы данных Vector», а затем перейдите к следующему шагу, нажав «Настроить службу LLM» на левой боковой панели.
3. Настройте службу LLM
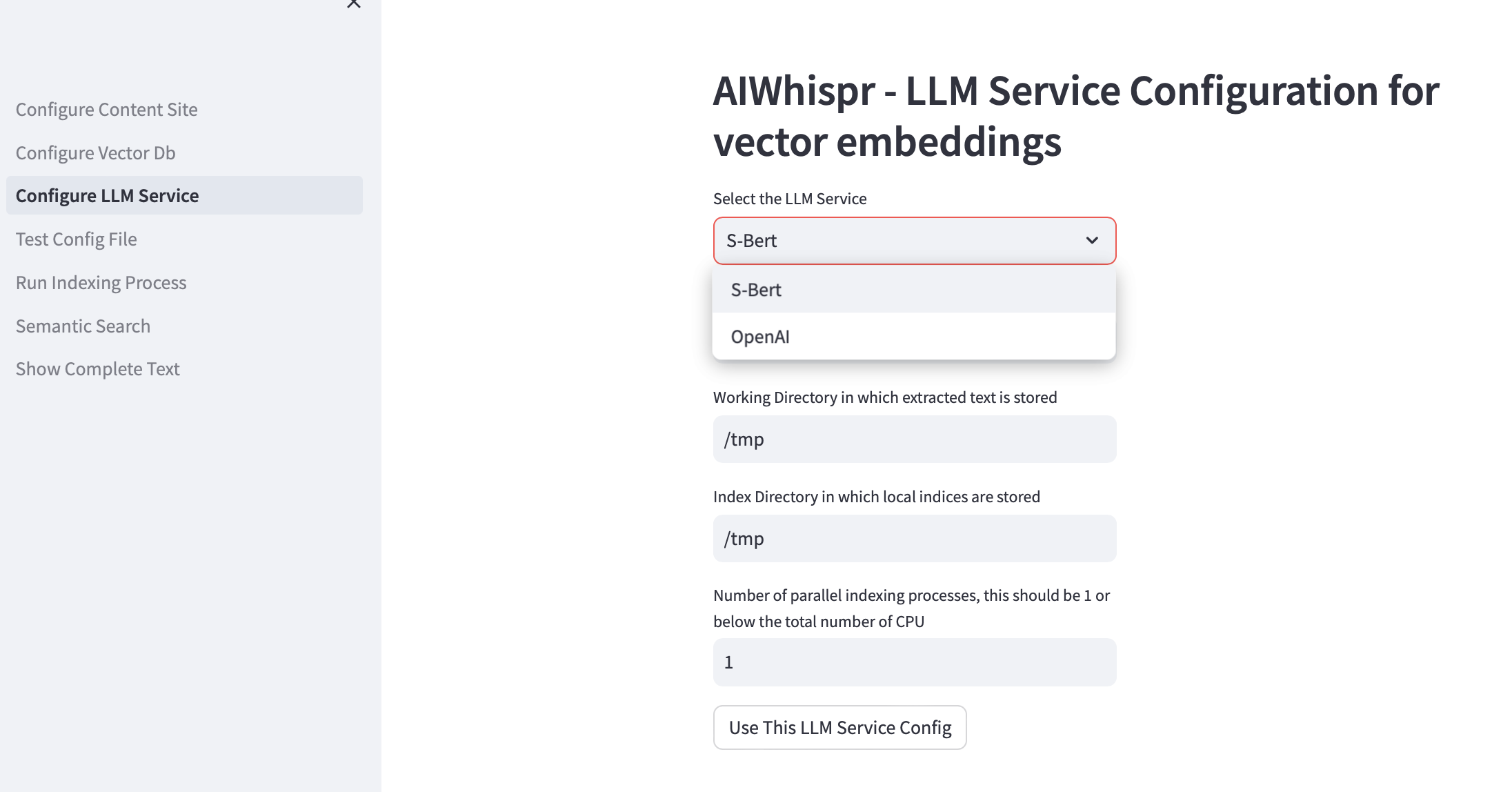
Вы можете создать векторные внедрения, используя предварительно обученные модели Sbert, которые запускаются локально, или использовать API OpenAI.
Для семейства моделей SBert по умолчанию используется модель all-mpnet-base-v2. Вы можете указать другую модель SBert.
Для OpenAI модель внедрения по умолчанию — text-embedding-ada-002.
Рабочий каталог по умолчанию — /tmp.
Рабочий каталог — это место на локальном компьютере, которое будет использоваться в качестве рабочего каталога для обработки файлов, считываемых/загружаемых из вашего хранилища. Извлеченный текст из ваших документов затем разбивается на фрагменты меньшего размера, обычно 700 слов, которые затем кодируются как векторные вложения. Рабочий каталог используется для хранения фрагментов текста.
Локальный каталог индексирования по умолчанию — /tmp.
Вы можете указать постоянный путь к локальному каталогу для рабочего и индексного каталога.
Индексный каталог используется для хранения списка индексирования файлов содержимого, которые необходимо прочитать. AIWhispr поддерживает несколько процессов индексирования, каждый процесс будет использовать свой собственный список индексирования, что позволяет вам использовать несколько процессоров на вашем компьютере.
Если вы хотите использовать несколько процессоров для индексации (чтение контента, создание векторного внедрения, сохранение в базе данных векторов), укажите это в поле тестирования для количества параллельных процессов. Мы рекомендуем, чтобы это значение было равно 1 или максимум (Количество ЦП/2). Например, на компьютере с 8 процессорами это значение должно быть установлено на 4. AIWhispr использует многопроцессорность для обхода ограничений Python GIL.
Нажмите «Использовать эту конфигурацию службы LLM», чтобы создать окончательную версию файла конфигурации конвейера векторного внедрения.
Будет отображено содержимое файла конфигурации и его расположение на вашем компьютере.
Вы можете протестировать эту конфигурацию, нажав «Проверить файл конфигурации» на левой боковой панели.
4. Тестовая конфигурация
Теперь вы должны увидеть сообщение, показывающее расположение файла конфигурации конвейера векторного внедрения, и кнопку «Проверить файл конфигурации».
Нажатие на кнопку запустит процесс, который проверит конфигурацию конвейера на предмет
В конце журналов вы должны увидеть сообщение «НЕТ ОШИБОК», которое информирует вас о том, что эту конфигурацию конвейера можно использовать.
Нажмите «Запустить процесс индексирования» на левой боковой панели, чтобы запустить конвейер.
5. Запустите процесс индексирования
Вы должны увидеть кнопку «Начать индексирование».
Нажмите на эту кнопку, чтобы запустить конвейер. Журналы обновляются каждые 15 секунд.
Пример по умолчанию индексирует более 2000 новостей BBC, что занимает около 20 минут.
Не уходите с этой страницы, пока идет процесс индексирования, т. е. пока в правом верхнем углу отображается статус Streamlit «Выполняется».
Вы также можете проверить, запущен ли процесс индексирования с помощью grep на вашем компьютере.
ps -ef | grep python3 | grep index_content_site.py
6. Семантический поиск
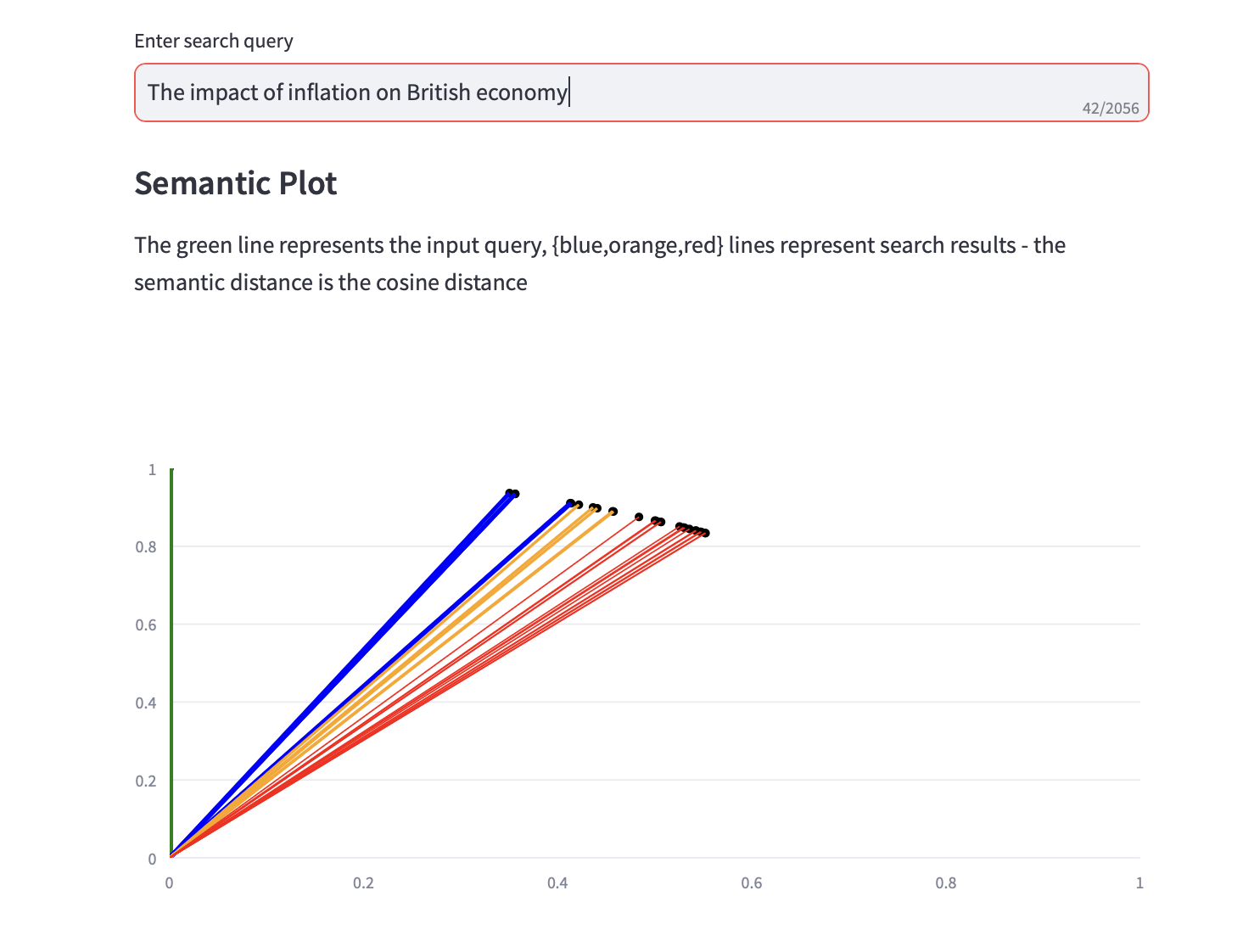
Теперь вы можете запускать семантические поисковые запросы.
Вместе с результатами текстового поиска также отображается семантический график, отображающий косинусное расстояние и топ-3 анализа PCA для результатов поиска.