lnx
v0.9.0 Master

Богатый функционал | ⚡ Безумно быстро
Сверхбыстрое и адаптируемое развертывание поисковой системы tantivy через REST.
lnx создан для того, чтобы не изобретать велосипед заново, он стоит на вершине среды выполнения tokio-rs , гипервеб -фреймворка в сочетании с грубой вычислительной мощью поисковой системы tantivy .
Вместе это позволяет lnx предлагать миллисекундную индексацию десятков тысяч вставок документов одновременно (больше не нужно ждать, пока что-то проиндексируется!), транзакции по индексу и возможность обрабатывать поиск, как будто это просто еще один поиск в хеш-таблице?
lnx, хотя и совсем новый, предлагает широкий спектр функций благодаря экосистеме, на которой он основан.
Здесь вы можете видеть, как lnx выполняет поиск по мере того, как вы вводите набор данных из 27 миллионов документов, объем которого после индексации составляет разумные 18 ГБ, работал на моем i7-8700k с использованием ~ 3 ГБ ОЗУ с нашей быстро-нечеткой системой . У нас есть больший набор данных, чтобы мы могли попробовать? Откройте проблему!
lnx может предоставить возможность точной настройки системы в соответствии с вашим конкретным вариантом использования. Вы можете настроить потоки асинхронной среды выполнения. Пул потоков параллелизма, потоки на потоки чтения и записи, все на индекс.
Это дает вам возможность детально контролировать использование ваших вычислительных ресурсов. У вас большой набор данных, но меньшее количество одновременных операций чтения? Увеличьте потоки чтения в обмен на более низкий максимальный параллелизм.
Приведенные ниже цифры были получены с помощью нашего lnx-cli для небольшого набора данных movies.json , мы не пытались увеличить их, поскольку Meilisearch требует невероятно много времени для индексации миллионов документов, хотя новый движок Meilisearch несколько улучшил эту ситуацию.
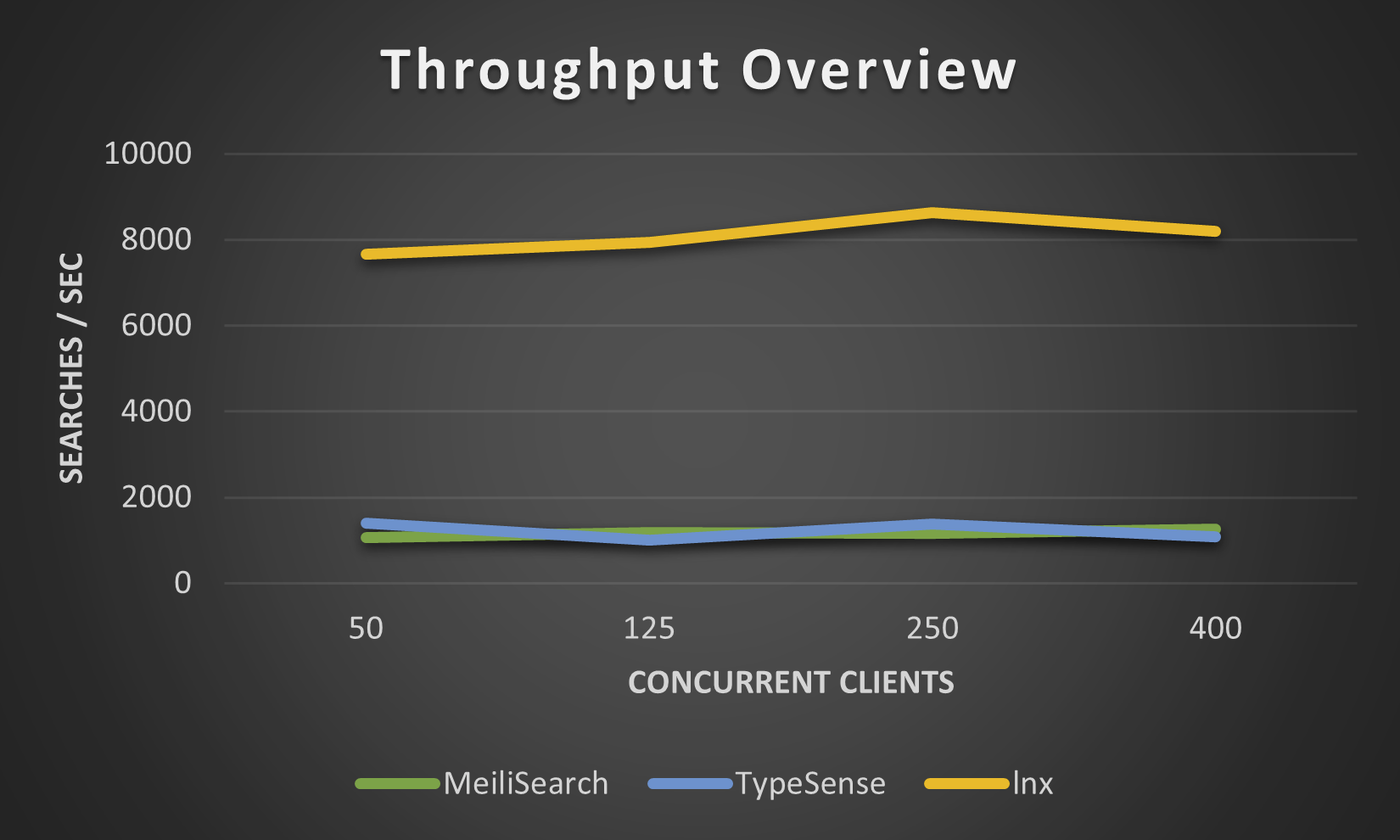
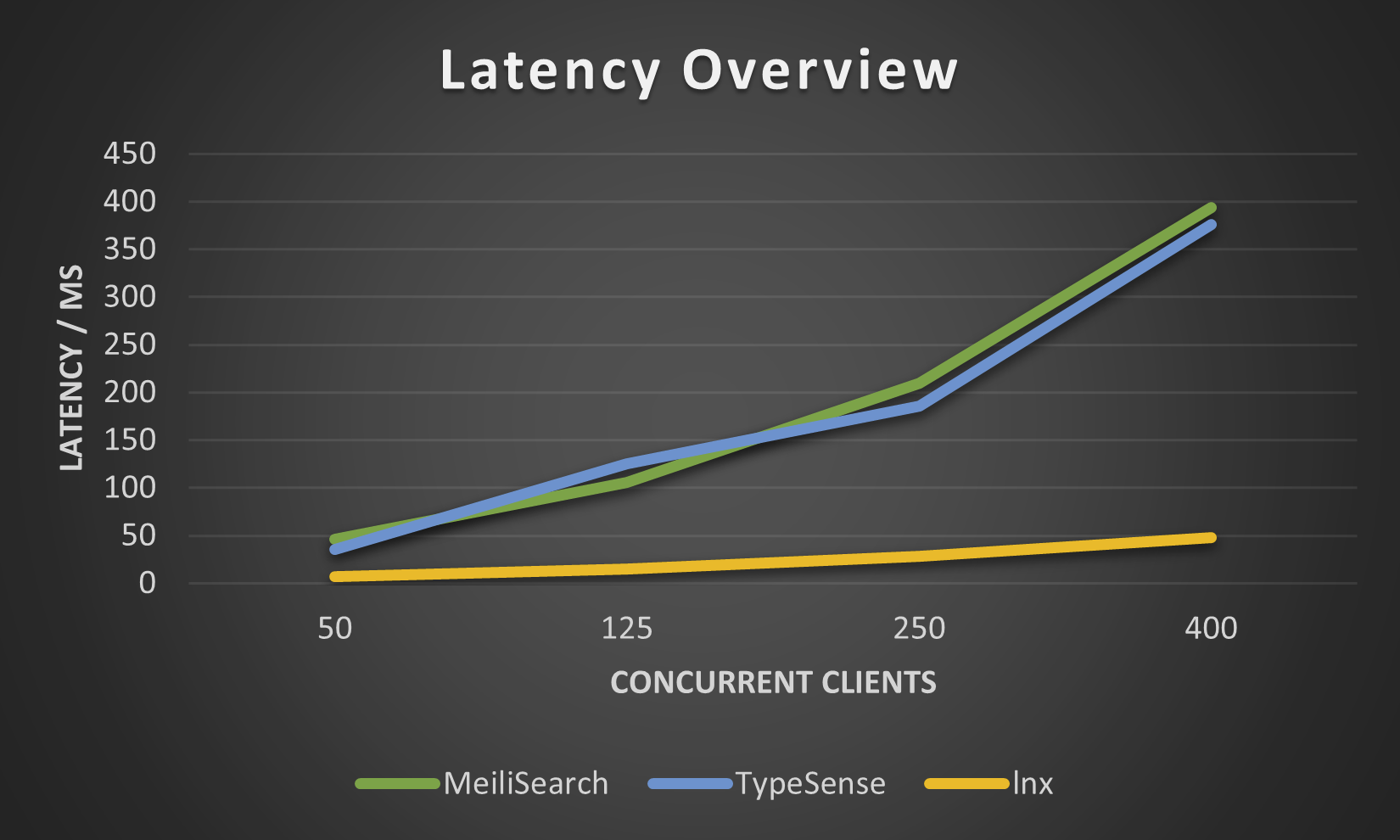
Несмотря на то, что lnx предоставляет широкий спектр функций, он не может делать все это, будучи такой молодой системой. Естественно, у него есть некоторые ограничения:


