sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
Сопровождающий: jcudit и lsgos
Проект поддерживается как минимум до (ГГГГ-ММ-ДД): 14 марта 2023 г.
Это пример использования API Cohere для создания простой системы семантического поиска. Он не предназначен для обеспечения готовности к использованию или эффективного масштабирования (хотя может быть адаптирован для этих целей), а скорее служит для демонстрации простоты создания поисковой системы, основанной на представлениях, созданных моделями большого языка (LLM) Cohere.
Используемый здесь алгоритм поиска довольно прост: он просто находит абзац, который наиболее точно соответствует представлению вопроса, используя конечную точку co.embed . Более подробно это объясняется ниже, а вот простая диаграмма того, что происходит. Сначала мы разбиваем входной текст на ряд абзацев, сохраняя их адреса во входных данных в список и генерируя векторное встраивание для каждого абзаца с помощью co.embed :
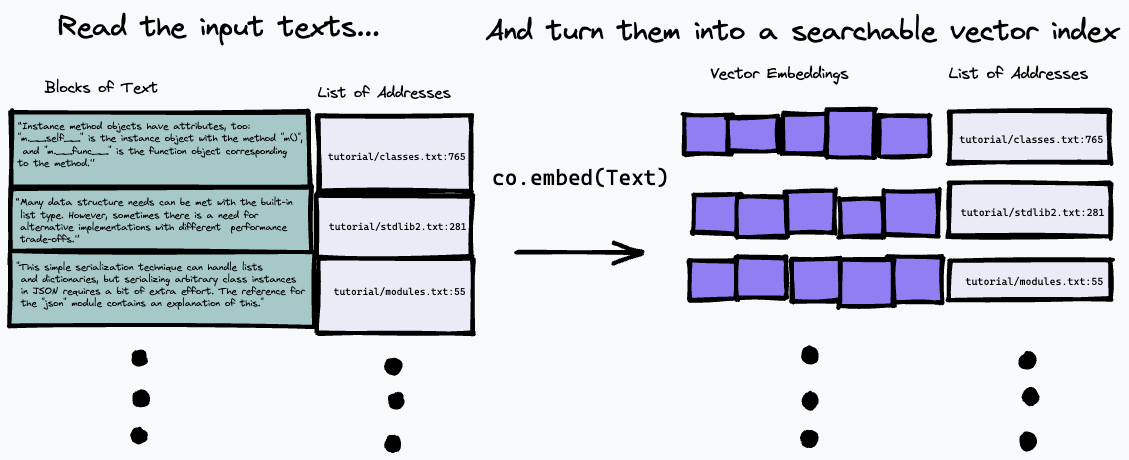
Затем мы можем запросить наш индекс, встроив текстовый запрос и найдя в исходном тексте абзацы, которые имеют наибольшее совпадение, используя некоторую меру векторного сходства (мы использовали косинусное сходство): 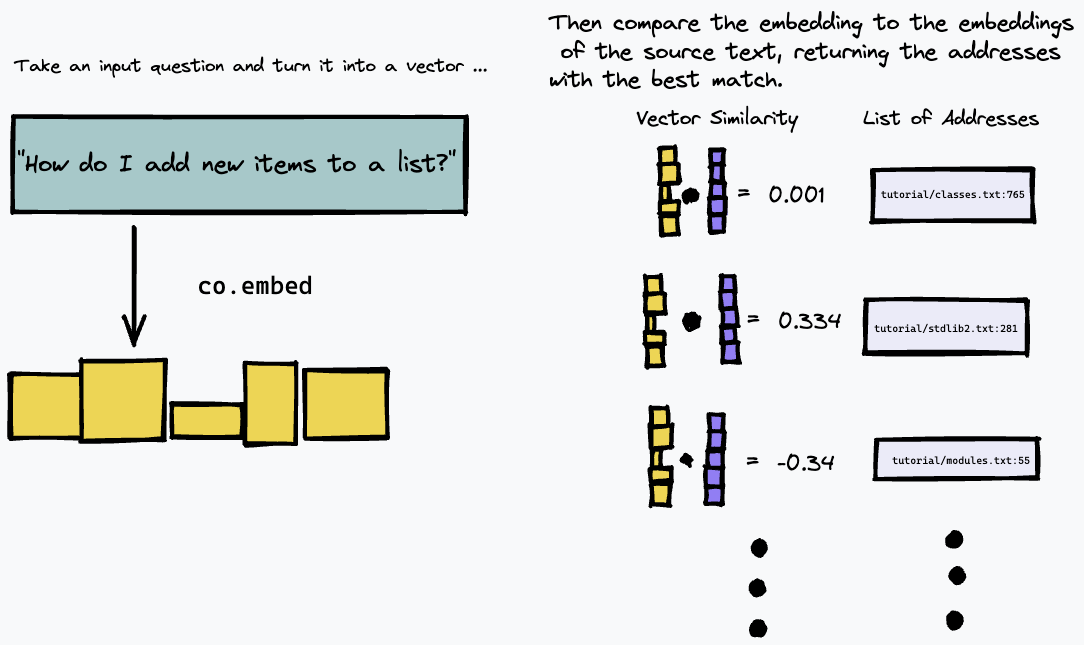
В результате он лучше всего работает с текстовыми источниками, где ответ на данный вопрос, скорее всего, будет дан конкретным абзацем в тексте, например, с технической документацией или внутренними вики-сайтами, которые структурированы как список конкретных инструкций или фактов. Это не так хорошо работает, например, при ответах на вопросы о тексте произвольной формы, например в романах, где информация может быть распределена по нескольким абзацам; для этого вам нужно будет использовать другой метод индексации текста.
Например, этот репозиторий создает простую систему семантического поиска на основе текстовой версии последней документации Python.
Чтобы установить требования Python, убедитесь, что у вас установлена и запущена поэзия:
# install python deps
poetry installУ вас также должен быть установлен докер. В OS X, если вы используете доморощенный вариант, мы рекомендуем запустить
brew install --cask dockerПрежде чем запускать Docker (например, для запуска нашего сервера) в OS X в первый раз, откройте приложение Docker и предоставьте ему привилегии, необходимые для запуска в вашей системе.
Вам также понадобится ключ Cohere API в COHERE_TOKEN . Получите его с платформы Cohere (при необходимости создайте учетную запись) и запишите его в свою среду.
export COHERE_TOKEN= < MY_API_KEY > (где <MY_API_KEY> — полученный вами ключ без скобок <...> ).
Альтернативно вы можете передать COHERE_TOKEN=<MY_API_KEY> в качестве дополнительного аргумента для любой команды make , указанной ниже.
Выполните следующие шаги, чтобы сначала создать семантический индекс вашей коллекции документов. Эти шаги создают семантический индекс для официальной документации Python, но его можно адаптировать для сбора произвольных данных.
Сначала загрузите документацию Python, выполнив одну из следующих команд.
Если вы хотите быстро начать работу, запустите
make download-python-docs-smallчтобы ограничить набор документов учебным пособием по Python. Мы рекомендуем делать это только для быстрого тестирования, поскольку результаты будут очень ограниченными .
Если вы хотите протестировать поисковую систему по всей документации Python, запустите
make download-python-docsно имейте в виду, что создание вложений займет несколько часов (хотя это нужно сделать только один раз).
Альтернативно, если вы хотите поэкспериментировать со своим собственным текстом, просто загрузите его в виде файлов .txt в каталог с именем txt/ в этом репозитории.
Когда у вас есть текст, нам нужно обработать его в поисковый индекс вложений и адресов.
Это можно сделать с помощью команды
make embeddings предполагая, что ваш целевой текст находится в каталоге ./txt/ .
Команда будет рекурсивно искать в каталоге ./txt/ файлы с расширением .txt и создавать простую базу данных вложений, имени файла и номера строки каждого абзаца.
Предупреждение: если вам нужно найти много текста, поиск может занять некоторое время!
После создания файла embeddings.npz вы можете использовать следующую команду для создания образа Docker, который будет служить простому приложению REST, позволяющему запрашивать созданную вами базу данных:
make buildЗатем вы можете запустить сервер, используя
make runЭто немного излишне для простого примера, но оно призвано отразить тот факт, что построение индекса большого объема текста происходит относительно медленно и гарантирует, что запросы к механизму будут быстрыми.
Если вы хотите использовать этот проект в качестве строительного блока для реального приложения, вполне вероятно, что вы захотите сохранить свою базу данных вложений текста в серверной архитектуре и запрашивать ее с помощью легковесного клиента. Упаковка сервера как док-приложения означает, что превратить его в «настоящее» приложение очень просто, развернув его в облачной службе.
Если вы откроете новое окно терминала для любого из приведенных ниже вариантов, не забудьте запустить
export COHERE_TOKEN= < MY_API_KEY > Безусловно, самый простой вариант — запустить наш вспомогательный скрипт:
scripts/ask.sh " My query here "для запроса базы данных. Скрипт принимает необязательный второй аргумент, указывающий количество желаемых результатов.
Скрипт открывает модифицированный интерфейс vim со следующими командами:
q , чтобы выйти.Верхняя панель покажет вам позицию в документе, где находится результат.
Как только сервер заработает, вы можете запросить его, используя простой REST API. Вы можете изучить API напрямую, перейдя по адресу /docs#/default/search_search_post здесь. Это простой API REST JSON; вот как вы можете задать запрос с помощью curl :
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
Это вернет список JSON длиной num_results , каждый из которых содержит имя файла и номер строки ( doc_url и block_url ) блоков, которые наиболее семантически соответствуют вашему запросу. Но вы, вероятно, захотите просто прочитать часть файлов, что является лучшим ответом.
Поскольку мы ищем в локальных текстовых файлах, на самом деле немного проще анализировать выходные данные с помощью инструментов командной строки; используйте предоставленный скрипт Python utils/query_server.py чтобы запросить его в командной строке. query_server.py распечатывает результаты в стандартном формате file_name:line_number: :, поэтому мы можем просматривать фактические результаты удобным способом, используя режим быстрого исправления vim .
Предполагая, что на вашем компьютере установлен vim, вы можете просто
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
чтобы заставить vim открывать индексированные текстовые файлы в местах, возвращенных алгоритмом поиска. (используйте :qall , чтобы закрыть окно и навигатор быстрых исправлений). Вы можете просмотреть возвращаемые результаты, используя :cn и :cp . Результаты не идеальны; это семантический поиск, поэтому можно ожидать, что совпадение будет немного нечетким. Несмотря на это, я часто обнаруживаю, что вы можете получить ответ на свой вопрос в первых нескольких результатах, а использование API Cohere позволяет вам выразить свой вопрос на естественном языке и создать удивительно эффективную поисковую систему всего за несколько строк кода.
Вот несколько полезных запросов в случае с документами Python, которые показывают, что поиск хорошо работает по общим вопросам на естественном языке:
How do I put new items in a list? (Обратите внимание, что в этом вопросе не используется ключевое слово «добавление» и он не совсем соответствует тому, как в документации объясняется добавление (они говорят, что оно используется для добавления новых элементов в конец списка). Но семантический поиск правильно определяет, что соответствующий абзац по-прежнему лучше всего соответствует.)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (обратите внимание на этот вопрос: первым результатом для меня является FAQ по этой же теме, но с вопросом, сформулированным по-другому. Однако, поскольку это семантический поиск, наш алгоритм правильно выбирает результат, соответствующий значению, а не только формулировка нашего запроса)How do I remove an item from a set?How do list comprehensions work? В этом репозитории используется очень простая стратегия индексации документа и поиска наилучшего соответствия. Во-первых, он разбивает каждый документ на абзацы или «блоки». Затем он вызывает co.embed для каждого абзаца, чтобы сгенерировать векторное встраивание с использованием языковой модели Cohere. Затем он сохраняет каждый вектор внедрения вместе с соответствующим документом и номером строки абзаца в простом массиве как «базу данных».
Для фактического поиска мы используем библиотеку поиска по сходству FAISS. Когда мы получаем запрос, мы используем тот же вызов API Cohere для встраивания запроса. Затем мы используем FAISS, чтобы найти вершину
Если у вас есть какие-либо вопросы или комментарии, сообщите о проблеме или свяжитесь с нами в Discord.
Если вы хотите внести свой вклад в этот проект, прочтите CONTRIBUTORS.md в этом репозитории и подпишите Лицензионное соглашение участника, прежде чем отправлять какие-либо запросы на включение. Ссылка для подписания Cohere CLA будет создана при первом запросе на включение в репозиторий Cohere.
Toy Semantic Search имеет лицензию MIT, как указано в файле LICENSE.


