wagtail_textract
1.0.0
Этот пакет не поддерживается, и мы не планируем его поддерживать.
Мы советуем вам использовать его в качестве примера, возможно, скопировать код в свой проект, но не устанавливать пакет.
Этот пакет предназначен для замены класса Document Wagtail на класс, который позволяет выполнять поиск по содержимому файла документа с использованием текстового фрагмента.
Textract может извлекать текст (помимо прочего) из файлов PDF, Excel и Word.
Пакет был создан на основе проблемы «Поиск: Извлечение текста из документов» в Wagtail.
Документы будут работать как и раньше, за исключением того, что поиск документов в интерфейсе администратора Wagtail также будет находить условия поиска в содержимом файлов.
Несколько скриншотов для иллюстрации.
На нашем новом сайте Wagtail с установленным wagtail_textract мы загрузили файл test_document.pdf с рукописным текстом. Он указан в интерфейсе администратора в разделе «Документы»:
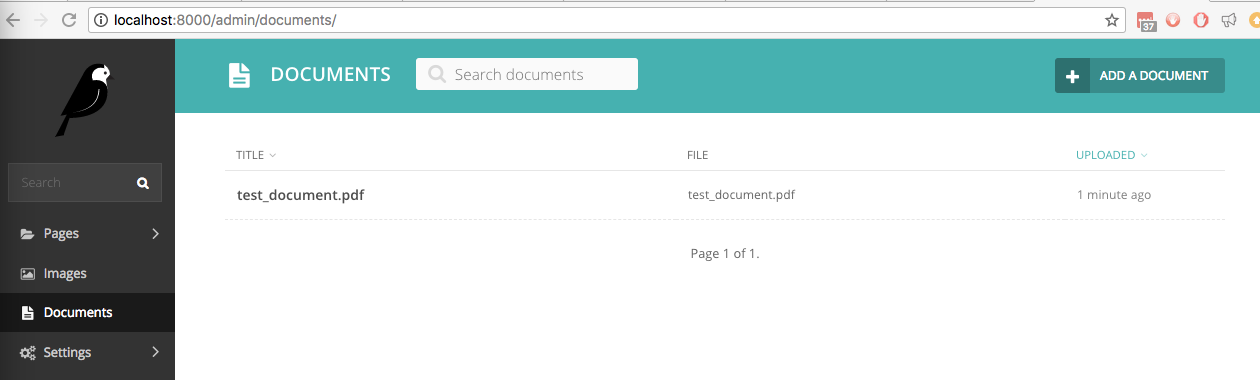
Если теперь мы ищем в Документах слово correct , которое является одним из рукописных слов, живой поиск найдет его:
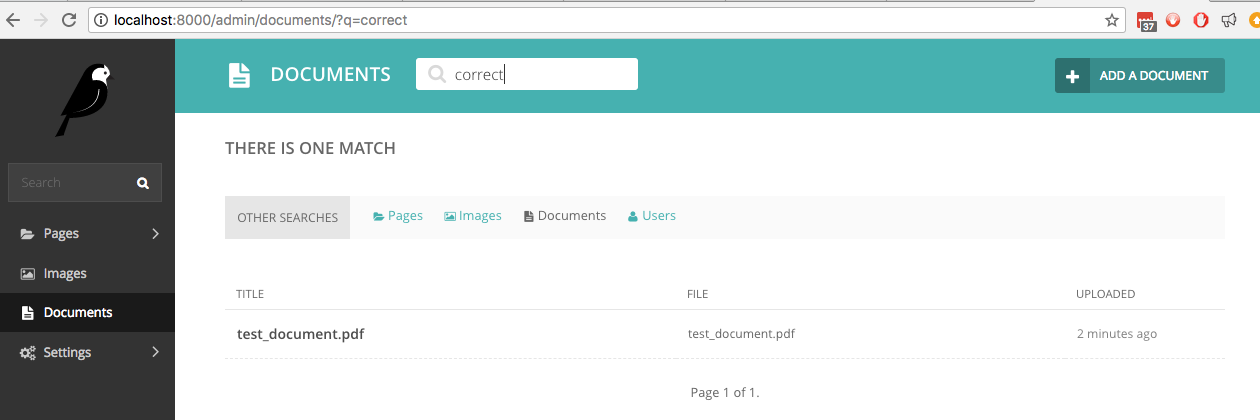
Предполагается, что этот поиск должен быть доступен не только в интерфейсе администратора Wagtail, но и в общедоступном представлении поиска, для которого мы приводим пример кода.
Мы используем этот пакет в производстве с августа 2018 года на https://nuffic.nl.
wagtail_textract к вашим требованиям и/или pip install wagtail_textractINSTALLED_APPS .WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document" в настройках Django.Примечание. Вы получите предупреждение о несовместимости во время установки wagtail_texttract (установлена версия Wagtail 2.0.1):
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
Мы не видели, чтобы это приводило к проблемам, но об этом следует помнить.
Чтобы textract использовал Tesseract (что происходит, если обычный textract не находит текста), вам необходимо добавить файлы данных, на которых Tesseract может основывать сопоставление слов.
Создайте каталог tessdata в каталоге вашего проекта и загрузите нужные языки.
Транскрипция выполняется автоматически после сохранения документа в исполнителе asyncio , чтобы предотвратить блокировку ответа во время обработки.
Чтобы расшифровать все существующие документы, запустите команду управления::
./manage.py transcribe_documents
Очевидно, это может занять много времени.
Вот пример кода для представления поиска (вне интерфейса администратора Wagtail), в котором отображаются результаты как на странице, так и на документе.
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
}) Ваш шаблон должен позволять обрабатывать документы иначе, чем страницы, поскольку вы не можете выполнить pageurl result для документа:
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} Чтобы использовать wagtail_texttract, ваша модель CustomizedDocument должна делать то же самое, что и Document wagtail_texttract:
TranscriptionMixinsearch_fields from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
] Обратите внимание, что первым подклассом должен быть TranscriptionMixin , поэтому его save() имеет приоритет над методом save() других родительских классов.
Чтобы запустить тесты, извлеките этот репозиторий и:
make test
Отчет о покрытии будет создан в ./coverage_html_report/ .


