loss_function_search
1.0.0
Сяобо Ван*, Шуо Ван*, Чэн Чи, Шифэн Чжан, Тао Мэй
Это официальная реализация нашего поиска функции потерь для распознавания лиц. Он принят ICML 2020.
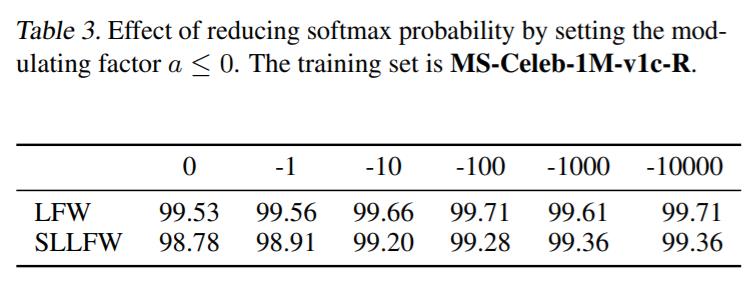
При распознавании лиц разработка функций потерь softmax на основе полей (например, угловых, аддитивных, аддитивных угловых полей) играет важную роль в изучении отличительных признаков. Однако эти эвристические методы, созданные вручную, неоптимальны, поскольку требуют больших усилий для исследования большого пространства проектирования. Сначала мы проанализируем, что ключ к улучшению распознавания признаков на самом деле заключается в том, как уменьшить вероятность softmax . Затем мы разрабатываем унифицированную формулу для текущих потерь softmax на основе маржи. Соответственно, мы определяем новое пространство поиска и разрабатываем метод поиска с вознаграждением, позволяющий автоматически находить лучшего кандидата. Экспериментальные результаты по различным критериям распознавания лиц продемонстрировали эффективность нашего метода по сравнению с современными альтернативами.
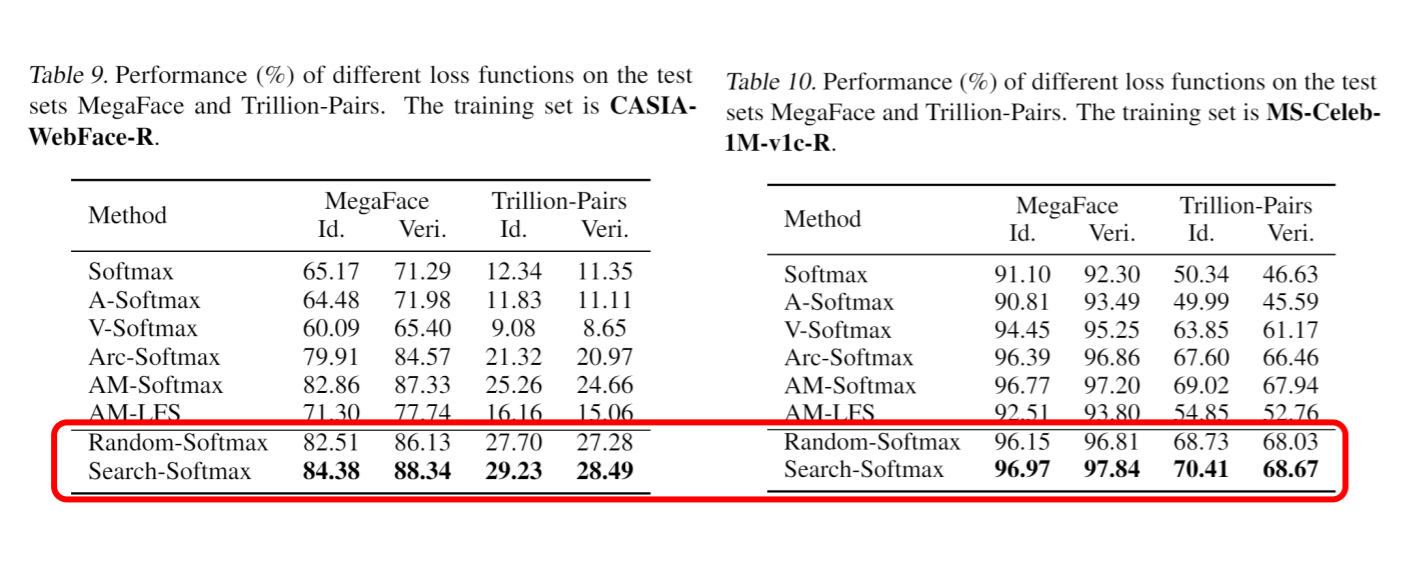

Чтобы проверить эффективность нашего пространства поиска, можно просто выбрать random-softmax. В train.sh вы можете установить do_search=1. Если мы используем случайный softmax для обучения нашей сети, мы получим результат ниже.
Требуется Pytorch 1.1 или выше.
В текущей реализации мы используем lmdb для упаковки наших обучающих изображений. Формат нашей lmdb в основном взят из Caffe. И вы можете написать свой собственный файл caffe.proto следующим образом:
syntax = "proto2";
message Datum {
//the acutal image data, in bytes.
optional bytes data=1;
}
Помимо lmdb, должен существовать текстовый файл, описывающий lmdb. Каждая строка текстового файла содержит два поля, разделенных пробелом. В текстовом файле строка следующая:
lmdb_key label
./train.shВы можете использовать ./train.sh. ОБРАТИТЕ ВНИМАНИЕ: прежде чем запускать train.sh, вам следует предоставить свои собственные train_source_lmdb и train_source_file. Для большего использования, пожалуйста
python main . py - h

