SeekStorm
v0.11.0

SeekStorm — это библиотека полнотекстового поиска с открытым исходным кодом, работающая за доли миллисекунды, и многопользовательский сервер, реализованный на Rust .
Разработка началась в 2015 году, в производстве с 2020 года, порт Rust в 2023 году, открытый исходный код в 2024 году, работа в стадии разработки.
SeekStorm имеет открытый исходный код и распространяется по лицензии Apache License 2.0.
Сообщения в блоге: SeekStorm теперь имеет открытый исходный код, а SeekStorm получил фасетный поиск, поиск по географической близости, сортировку результатов.
Типы запросов
Типы результатов
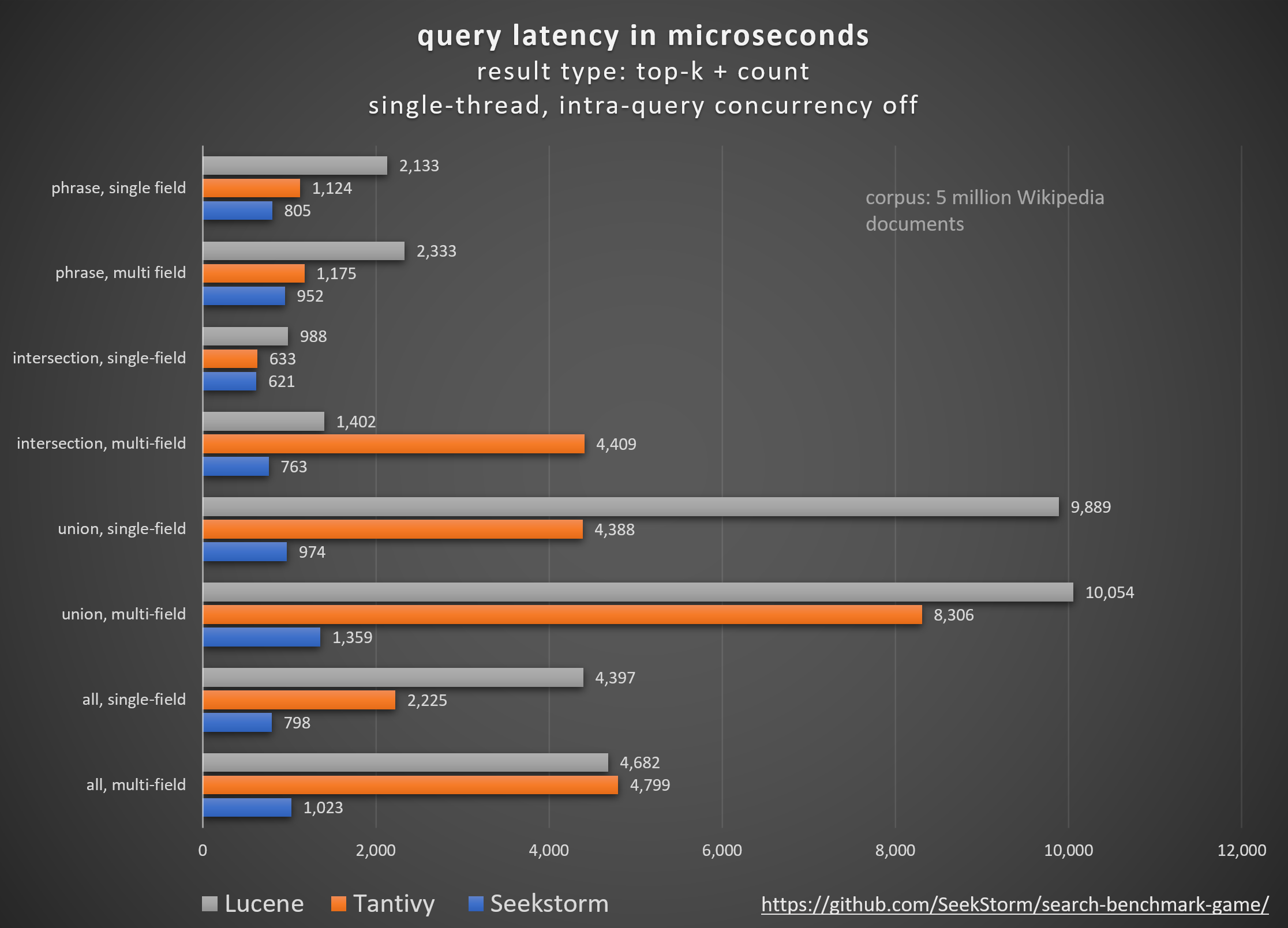
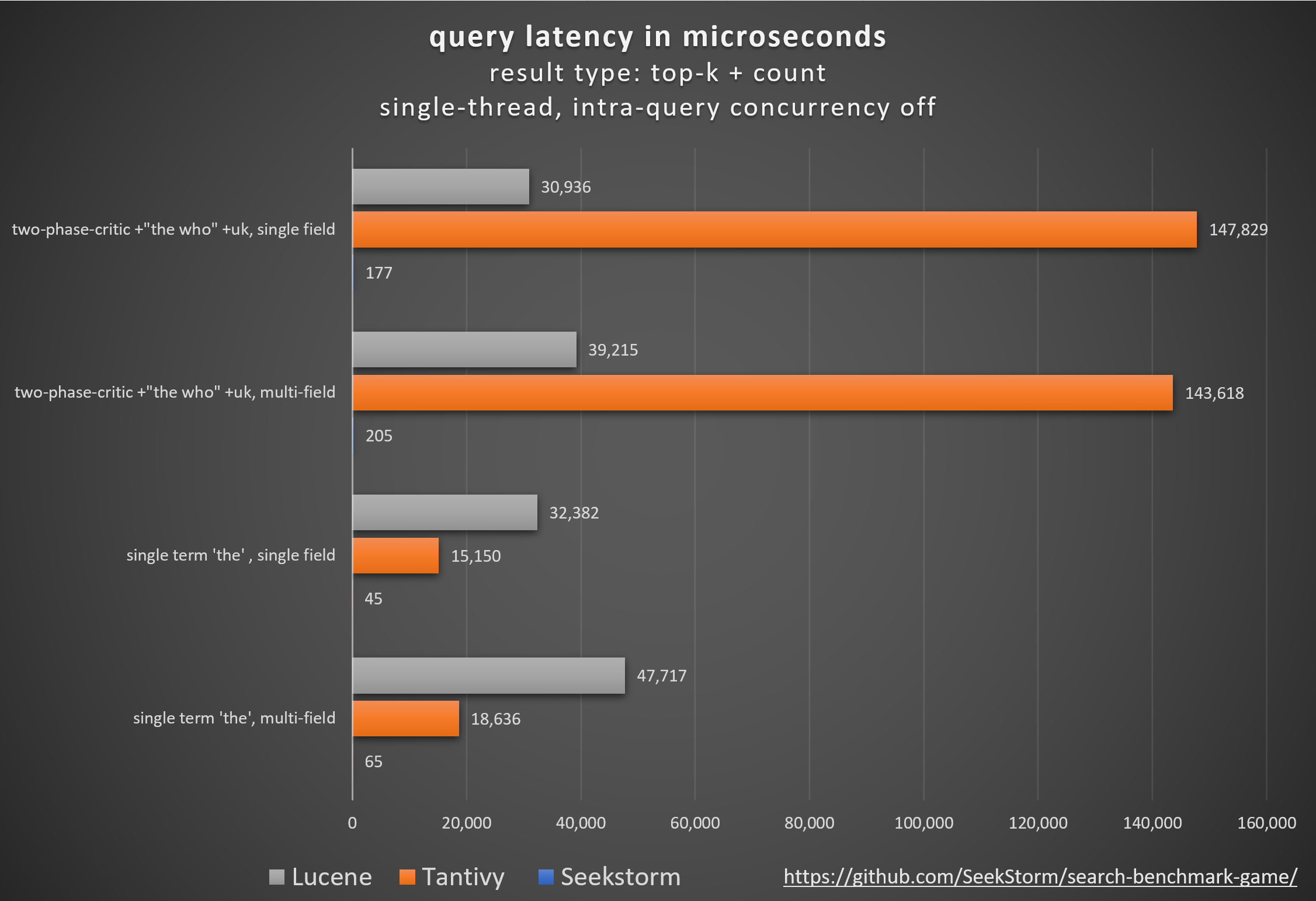
Производительность
Меньшая задержка, более высокая пропускная способность, более низкие затраты и энергопотребление, особенно. для многополевых и одновременных запросов.
Низкие задержки обеспечивают плавное взаимодействие с пользователем и предотвращают потерю клиентов и доходов.
Некоторые полагаются на собственные аппаратные ускорители (FPGA/ASIC) или кластеры для повышения производительности.
SeekStorm алгоритмически достигает аналогичного повышения на одном обычном сервере.
Последовательность
Никакой непредсказуемой задержки запроса во время и после индексации большого объема, поскольку SeekStorm не требует ресурсоемких слияний сегментов.
Стабильные задержки — отсутствие затрат на холодный старт из-за своевременной компиляции, отсутствие непредсказуемых задержек при сборке мусора.
Масштабирование
Поддерживает низкую задержку, высокую пропускную способность и низкое потребление оперативной памяти даже для индексов миллиардного масштаба.
Неограниченное количество полей, длина поля и размер индекса.
Актуальность
Рейтинг близости терминов дает более релевантные результаты по сравнению с BM25.
В режиме реального времени
Настоящий поиск в реальном времени, в отличие от NRT: каждый индексированный документ доступен для поиска немедленно, даже до и во время фиксации.
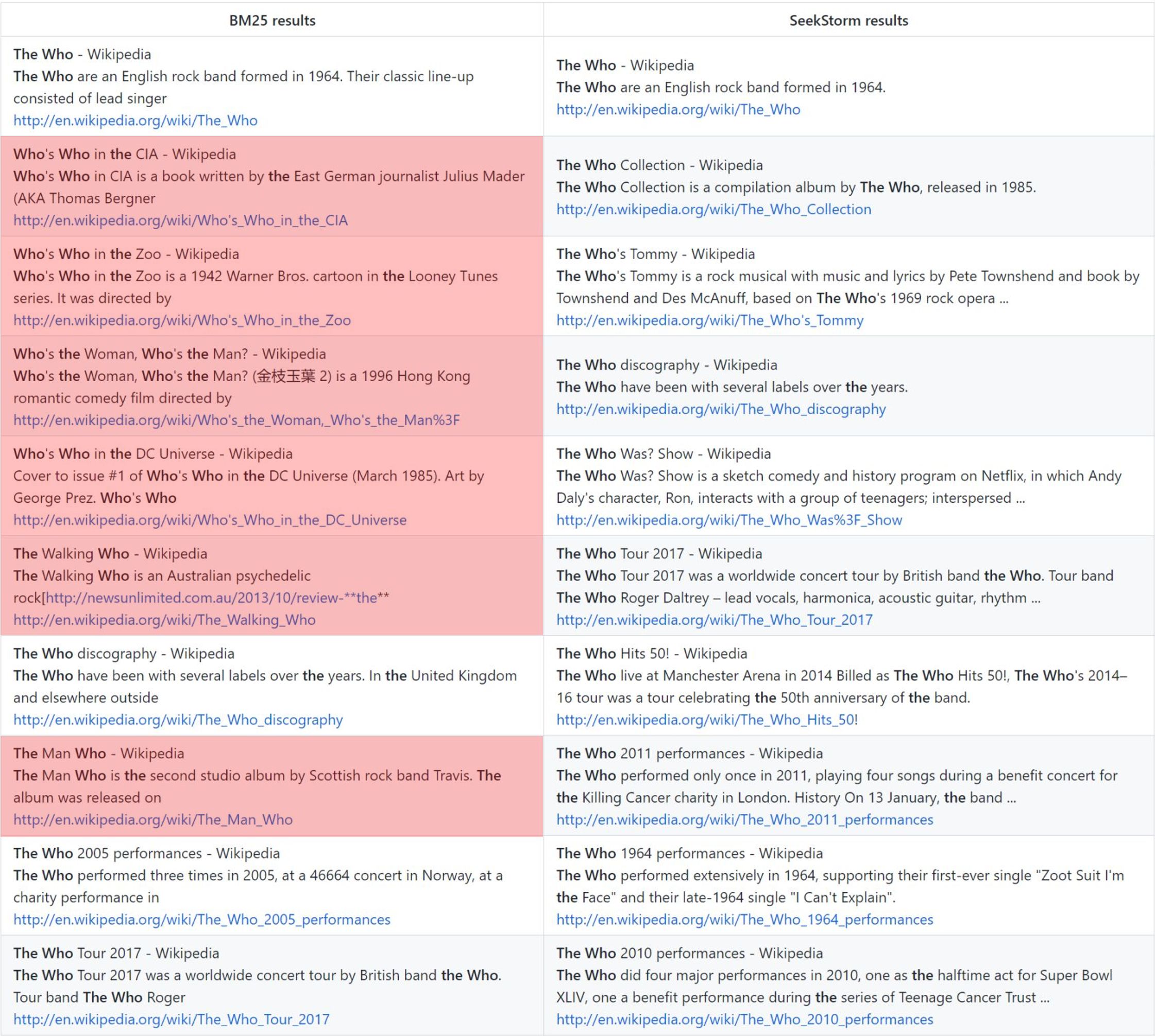
кто: ванильный рейтинг BM25 против рейтинга близости SeekStorm
Методология
Сравнение различных библиотек поисковых систем с открытым исходным кодом (лексический поиск BM25) с использованием игры search_benchmark_game с открытым исходным кодом, разработанной Тантиви и Джейсоном Вулфом.
Преимущества
Подробные результаты тестов https://seekstorm.github.io/search-benchmark-game/
Репозиторий тестового кода https://github.com/SeekStorm/search-benchmark-game/
Более подробную информацию можно найти в сообщениях нашего блога : SeekStorm теперь имеет открытый исходный код, а SeekStorm получил фасетный поиск, поиск по географической близости, сортировку результатов.
Несмотря на то, во что вас хотят убедить рекламные циклы https://www.bitecode.dev/p/hype-cycles, поиск по ключевым словам не умер, поскольку NoSQL не стал смертью SQL.
Вам следует иметь набор инструментов и выбирать лучший инструмент для вашей задачи. https://seekstorm.com/blog/vector-search-vs-keyword-search1/
Поиск по ключевым словам — это просто фильтр для набора документов, возвращающий те, в которых встречаются определенные ключевые слова, обычно в сочетании с показателем ранжирования, например BM25. Очень простая и основная функциональность, которую очень сложно реализовать в масштабе с низкой задержкой. Поскольку функциональность настолько проста, существует неограниченное количество полей приложения. Это компонент, который можно использовать вместе с другими компонентами. Есть случаи использования, которые сегодня лучше решать с помощью векторного поиска и LLM, но для многих других поиск по ключевым словам по-прежнему остается лучшим решением. Поиск по ключевым словам является точным, без потерь и очень быстрым, с лучшим масштабированием, лучшей задержкой, меньшими затратами и энергопотреблением. Векторный поиск работает с семантическим сходством, возвращая результаты с заданной близостью и вероятностью.
Если вы ищете точные результаты, такие как имена собственные, номера, номерные знаки, доменные имена и фразы (например, обнаружение плагиата), то поиск по ключевым словам — ваш друг. С другой стороны, векторный поиск скрывает точный результат, который вы ищете, среди множества результатов, которые лишь каким-то образом связаны семантически. В то же время, если вы не знаете точных терминов или вас интересует более широкая тема, значение или синоним, независимо от того, какие именно термины используются, то поиск по ключевым словам вас не устроит.
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.Векторный поиск идеален, если вы не знаете точных терминов запроса или вас интересует более широкая тема, значение или синоним, независимо от того, какие именно термины запроса используются. Но если вы ищете точные термины, например, имена собственные, номера, номерные знаки, доменные имена и фразы (например, обнаружение плагиата), вам всегда следует использовать поиск по ключевым словам. Векторный поиск лишь спрячет точный результат, который вы ищете, среди множества результатов, которые лишь каким-то образом связаны между собой. Он имеет хороший отзыв, но низкую точность и более высокую задержку. Он склонен к ложным срабатываниям, например, при обнаружении плагиата, поскольку теряются точные слова и порядок слов.
Векторный поиск позволяет искать не только похожий текст, но и все, что можно преобразовать в вектор: текст, изображения (распознавание лиц, отпечатки пальцев), аудио, а также позволяет совершать магические действия, например: королева - женщина + мужчина = король. .
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generationВекторный поиск — это не замена поиска по ключевым словам, а дополняющее его дополнение , которое лучше всего использовать в составе гибридного решения, в котором сочетаются сильные стороны обоих подходов. Поиск по ключевым словам не устарел, а проверен временем .
Мы (частично) перенесли кодовую базу SeekStorm с C# на Rust.
Rust отлично подходит для приложений, критичных к производительности, которые работают с большими данными и/или множеством одновременных пользователей. Быстрые алгоритмы станут еще лучше благодаря языку программирования, ориентированному на производительность.
см. ARCHITECTURE.md
cargo build --release
ВНИМАНИЕ : обязательно установите для переменной среды MASTER_KEY_SECRET значение секрета, иначе ваши сгенерированные ключи API будут скомпрометированы.
https://docs.rs/seekstorm
Документация сборки
cargo doc --no-deps
Доступ к документации локально
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
Добавьте необходимые ящики в свой проект
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;используйте асинхронную среду выполнения Rust
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {создать индекс
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;открытый индекс (альтернативно создать индекс)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; индексные документы
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; фиксировать документы
index_arc . commit ( ) . await ;индекс поиска
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;отображать результаты
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}многопоточный поиск
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}индексный файл JSON в формате JSON, JSON с разделителями-новой строкой и объединенном формате JSON.
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;индексировать все PDF-файлы в каталоге и подкаталогах
ingest ): [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;индексный PDF-файл
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;индексировать PDF-файл в байтах
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;получить байты PDF-файла
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;очистить индекс
index . clear_index ( ) ;удалить индекс
index . delete_index ( ) ;индекс закрытия
index . close_index ( ) ;строка версии библиотеки searchstorm
let version= version ( ) ;
println ! ( "version {}" ,version ) ;Фасеты определяются в трех разных местах:
Минимальный рабочий пример фасетного индексирования и поиска требует всего 60 строк кода. Но собирать все это воедино, опираясь только на документацию, может оказаться утомительным. Вот почему мы приводим здесь пример быстрого запуска:
Добавьте необходимые ящики в свой проект
cargo add seekstorm
cargo add tokio
cargo add serde_jsonДобавить декларации об использовании
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;используйте асинхронную среду выполнения Rust
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {создать индекс
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;индексные документы
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; фиксировать документы
index_arc . commit ( ) . await ;индекс поиска
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;отображать результаты
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}отображение фасетов
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;конец основной функции
Ok ( ( ) )
} Краткое пошаговое руководство о том, как создать поисковую систему Википедии на основе корпуса Википедии с использованием сервера SeekStorm за 5 простых шагов.

Скачать SeekStorm
Загрузите SeekStorm из репозитория GitHub.
Разархивируйте в каталог по вашему выбору, откройте в коде Visual Studio.
или альтернативно
git clone https://github.com/SeekStorm/SeekStorm.git
Сборка SeekStorm
Установите Rust (если его еще нет): https://www.rust-lang.org/tools/install.
В терминале кода Visual Studio введите:
cargo build --release
Получить корпус Википедии
Предварительно обработанный корпус английской Википедии (5 032 105 документов, 8,28 ГБ в распакованном виде). Хотя wiki-articles.json имеет расширение .JSON, он не является допустимым файлом JSON. Это текстовый файл, каждая строка которого содержит объект JSON с атрибутами URL, заголовка и тела. Формат называется ndjson («JSON с разделителями новой строки»).
Скачать корпус Википедии
Распаковывает корпус Википедии.
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
Переместите распакованный файл wiki-articles.json в каталог выпуска.
Запустить сервер SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Индексирование
Введите «ingest» в командную строку работающего сервера SeekStorm:
ingest
Это создает демонстрационный индекс и индексирует локальный файл Википедии.
Начните поиск во встроенном веб-интерфейсе
Откройте встроенный веб-интерфейс в браузере: http://127.0.0.1.
Введите запрос в поле поиска
Тестирование конечных точек REST API
Откройте src/seekstorm_server/test_api.rest в VSC вместе с расширением VSC «Rest client», чтобы выполнять вызовы API и проверять ответы.
интерактивные примеры конечных точек API
Установите «индивидуальный ключ API» в test_api.rest на ключ API, отображаемый в консоли сервера, когда вы вводите «индекс» выше.
Удалить демонстрационный индекс
Введите «delete» в командной строке работающего сервера SeekStorm:
delete
Выключение сервера
Введите «quit» в командной строке работающего сервера SeekStorm.
quit
Настройка
Хотите использовать что-то подобное для своего проекта? Ознакомьтесь с документацией по вставке и веб-интерфейсу.
Краткое пошаговое руководство о том, как создать поисковую систему PDF из каталога, содержащего файлы PDF, с помощью сервера SeekStorm.
Сделайте все свои научные статьи, электронные книги, резюме, отчеты, контракты, документацию, руководства, письма, банковские выписки, счета-фактуры, накладные доступными для поиска - дома или в вашей организации.
Сборка SeekStorm
Установите Rust (если его еще нет): https://www.rust-lang.org/tools/install.
В терминале кода Visual Studio введите:
cargo build --release
Скачать PDFium
Загрузите и скопируйте библиотеку Pdfium в ту же папку, что и searchstorm_server.exe: https://github.com/bblanchon/pdfium-binaries.
Запустить сервер SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Индексирование
Выберите каталог, содержащий PDF-файлы, которые вы хотите индексировать и выполнять поиск, например, ваши документы или каталог загрузки.
Введите «ingest» в командную строку работающего сервера SeekStorm:
ingest C:UsersJohnDoeDownloads
При этом создается pdf_index и индексируются все PDF-файлы из указанного каталога, включая подкаталоги.
Начните поиск во встроенном веб-интерфейсе
Откройте встроенный веб-интерфейс в браузере: http://127.0.0.1.
Введите запрос в поле поиска
Удалить демонстрационный индекс
Введите «delete» в командной строке работающего сервера SeekStorm:
delete
Выключение сервера
Введите «quit» в командной строке работающего сервера SeekStorm.
quit
Полнотекстовый поиск 30 миллионов сообщений Hacker News И связанных веб-страниц
DeepHN.org
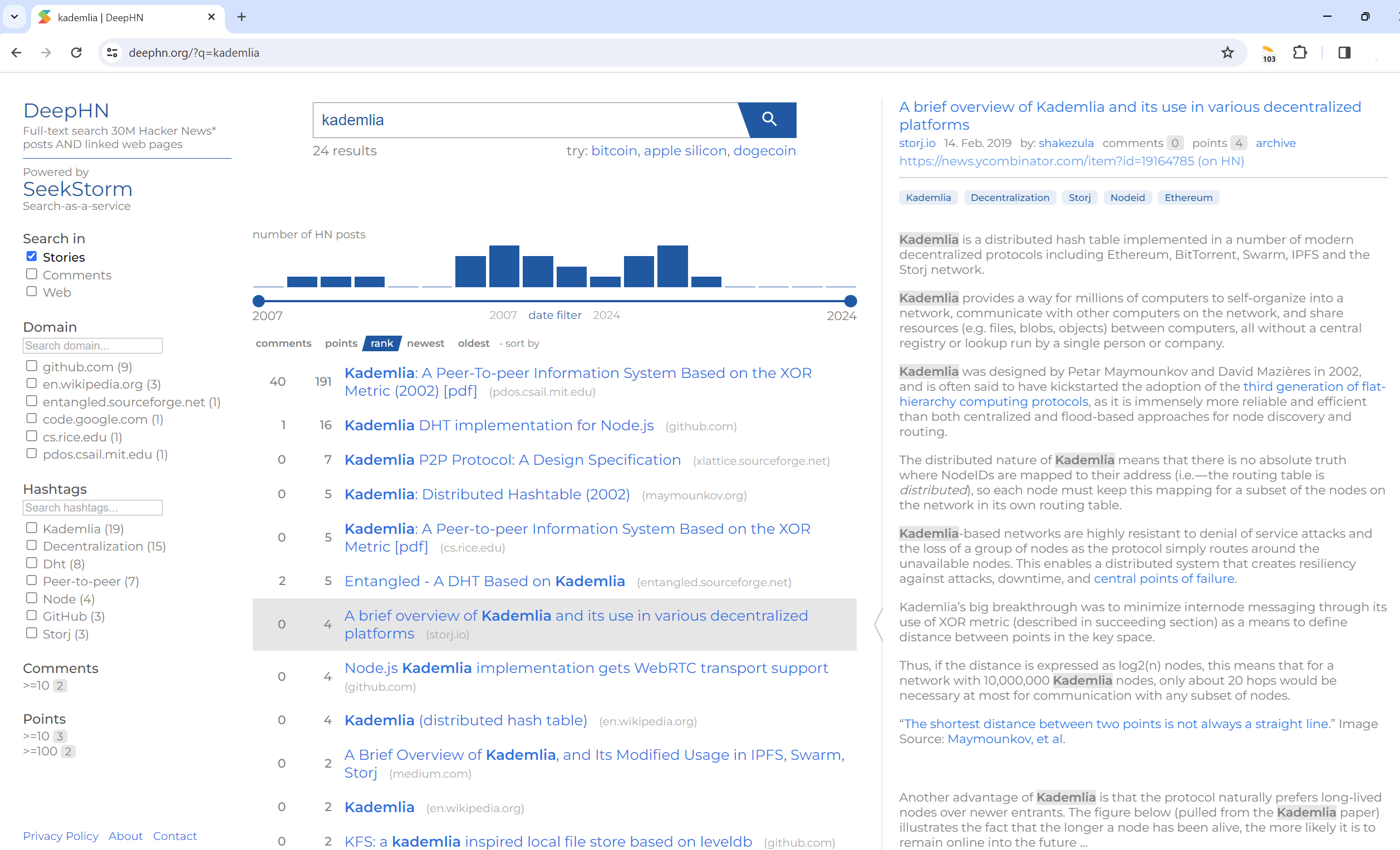
Демо-версия DeepHN по-прежнему основана на кодовой базе SeekStorm C#.
В настоящее время мы портируем все необходимые недостающие функции.
См. дорожную карту ниже.
Порт Rust еще не является полнофункциональным. Следующие функции в настоящее время портированы.
Портирование
Улучшения
Новые возможности


