auctus
1.0.0
Этот проект представляет собой веб-сканер и поисковую систему для наборов данных, специально предназначенную для задач по увеличению данных в машинном обучении. Он способен находить наборы данных в разных репозиториях и индексировать их для последующего поиска.
Документация доступна здесь
Он разделен на несколько компонентов:
datamart_geo . Содержит данные об административных территориях, извлеченные из Wikidata и OpenStreetMap. Он находится в собственном репозитории и используется здесь как подмодуль.datamart_profiler . Это может быть установлено клиентами, что позволит клиентской библиотеке локально профилировать наборы данных, а не отправлять их на сервер. Он также используется службами apiserver и профилировщика.datamart_materialize . Это используется для материализации набора данных из различных источников, поддерживаемых Auctus. Его могут установить клиенты, что позволит им материализовать наборы данных локально, вместо использования сервера в качестве прокси.datamart_augmentation . Это выполняет объединение или объединение двух наборов данных и используется службой apiserver, но, возможно, может использоваться автономно.datamart_core . Он содержит общий код для служб. Используется только для серверных компонентов. Код блокировки файловой системы выделен как datamart_fslock по соображениям производительности (необходимо быстро импортировать).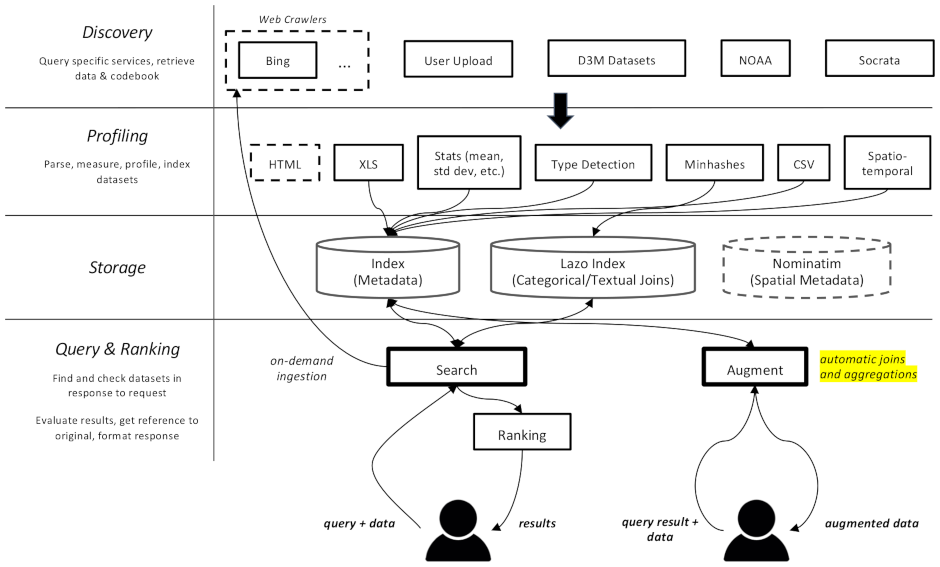
Elasticsearch используется в качестве индекса поиска, сохраняя один документ для каждого известного набора данных.
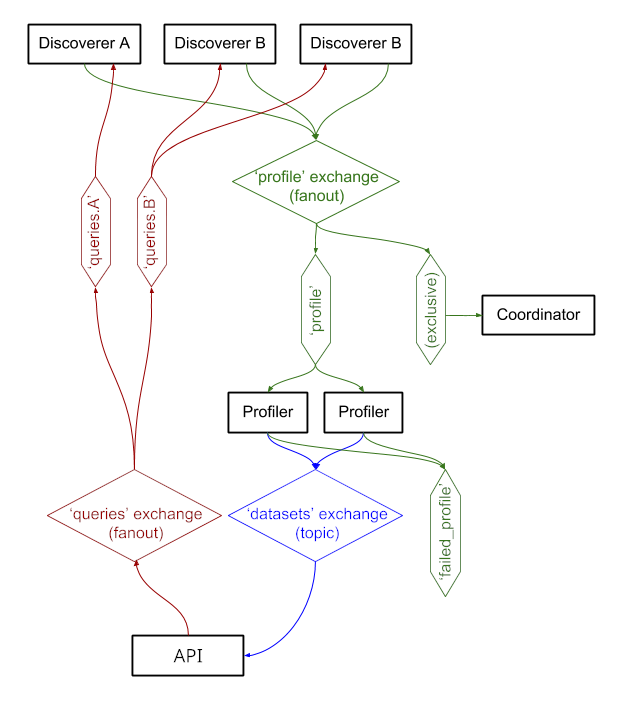
Службы обмениваются сообщениями через RabbitMQ , что позволяет нам использовать сложные шаблоны обмена сообщениями с семантикой организации очередей и повторных попыток, а также сложные шаблоны, такие как запросы по требованию.
В настоящее время система работает по адресу https://auctus.vida-nyu.org/. Статус системы можно увидеть по адресу https://grafana.auctus.vida-nyu.org/.
Чтобы развернуть систему локально с помощью docker-compose, выполните следующие действия:
Убедитесь, что вы извлекли подмодуль с помощью git submodule init && git submodule update
Убедитесь, что у вас установлен и настроен Git LFS ( git lfs install ).
Скопируйте env.default в .env и обновите там переменные. Возможно, вы захотите обновить пароль для производственного развертывания.
Убедитесь, что ваш узел настроен для запуска Elasticsearch. Вероятно, вам придется увеличить лимит mmap.
API_URL — это URL-адрес, по которому контейнеры API-сервера будут видны клиентам. В рабочем развертывании это, вероятно, общедоступный URL-адрес HTTPS. Это может быть тот же URL-адрес, по которому будет обслуживаться компонент «координатор» при использовании обратного прокси-сервера (см. nginx.conf).
Чтобы запускать сценарии локально, вы можете загрузить переменные среды в свою оболочку, запустив: . scripts/load_env.sh (это сценарии с точечным пространством... )
Запустите scripts/setup.sh чтобы инициализировать тома данных. Это установит правильные разрешения для volumes/ подкаталогов.
Если вы когда-нибудь захотите начать с нуля, вы можете удалить volumes/ но обязательно после этого снова запустите scripts/setup.sh чтобы установить разрешения.
$ docker-compose build --build-arg version=$(git describe) apiserver
$ docker-compose up -d elasticsearch rabbitmq redis minio lazo
Это займет несколько секунд, чтобы начать работу. Затем вы можете запустить другие компоненты:
$ docker-compose up -d cache-cleaner coordinator profiler apiserver apilb frontend
Вы можете использовать опцию --scale , чтобы запустить больше контейнеров профилировщика или API-сервера, например:
$ docker-compose up -d --scale profiler=4 --scale apiserver=8 cache-cleaner coordinator profiler apiserver apilb frontend
Порты:
$ scripts/docker_import_snapshot.sh
Будет загружен дамп Elasticsearch с сайта auctus.vida-nyu.org и импортирован в локальный контейнер Elasticsearch.
$ docker-compose up -d socrata zenodo
$ docker-compose up -d elasticsearch_exporter prometheus grafana
Prometheus настроен на автоматический поиск контейнеров (см. prometheus.yml).
Используется собственный образ RabbitMQ с добавленными плагинами (управление и прометей).


