elastic_transformers
1.0.0
Семантический Elasticsearch с преобразователями предложений. Мы будем использовать мощь Elastic и магию BERT, чтобы проиндексировать миллион статей и выполнить по ним лексический и семантический поиск.
Цель состоит в том, чтобы предоставить простой в использовании способ настройки вашего собственного Elasticsearch с почти современными возможностями контекстного встраивания/семантического поиска с использованием преобразователей NLP.
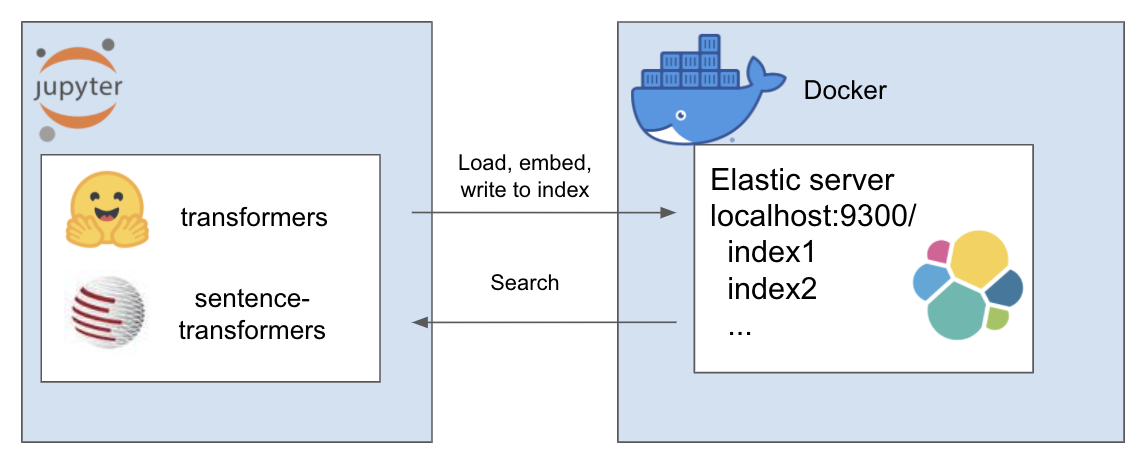
Вышеуказанная установка работает следующим образом
Моя среда называется et , и для этого я использую conda. Навигация внутри каталога проекта
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txtДля этого урока я использую A Million News Headlines от Rohk и помещаю его в папку data внутри каталога проекта.
elastic_transformers/
├── data/
Вы обнаружите, что в остальном шаги довольно абстрактны, поэтому вы также можете сделать это с выбранным вами набором данных.
Следуйте инструкциям по настройке Elastic с помощью Docker на странице Elastic здесь. Для этого руководства вам нужно выполнить всего два шага:
В репозитории представлен класс ElasiticTransformers. Утилиты, которые помогают создавать, индексировать и запрашивать индексы Elasticsearch, включающие встраивания.
Инициируйте ссылки подключения, а также (необязательно) имя индекса для работы.
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec определяет сопоставление индекса. Списки соответствующих полей могут быть предоставлены для поиска по ключевым словам или семантического (плотного векторного) поиска. Он также имеет параметры для размера плотного вектора, поскольку они могут варьироваться. create_index — использует созданную ранее спецификацию для создания индекса, готового для поиска.
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv — разбивает большой файл CSV на фрагменты и итеративно использует предопределенную утилиту внедрения для создания списка внедрений для каждого фрагмента и последующей передачи результатов в индекс.
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )поиск — позволяет выбрать поиск по ключевым словам («совпадение» в Elastic) или семантический (плотный в Elastic). Примечательно, что для этого требуется та же функция внедрения, что и в write_large_csv.
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )После успешной настройки используйте следующие блокноты, чтобы все заработало.
В этом репозитории собраны следующие удивительные работы блестящих людей. Пожалуйста, ознакомьтесь с их работами, если вы еще этого не сделали...


