VSA
1.0.0
[Страница проекта] [?Бумага] [?Обнимающее пространство] [Модельный зоопарк] [Введение] [?Видео]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
Локальная демо-версия основана на Gradio, и вы можете просто запустить ее с помощью:
python app.py
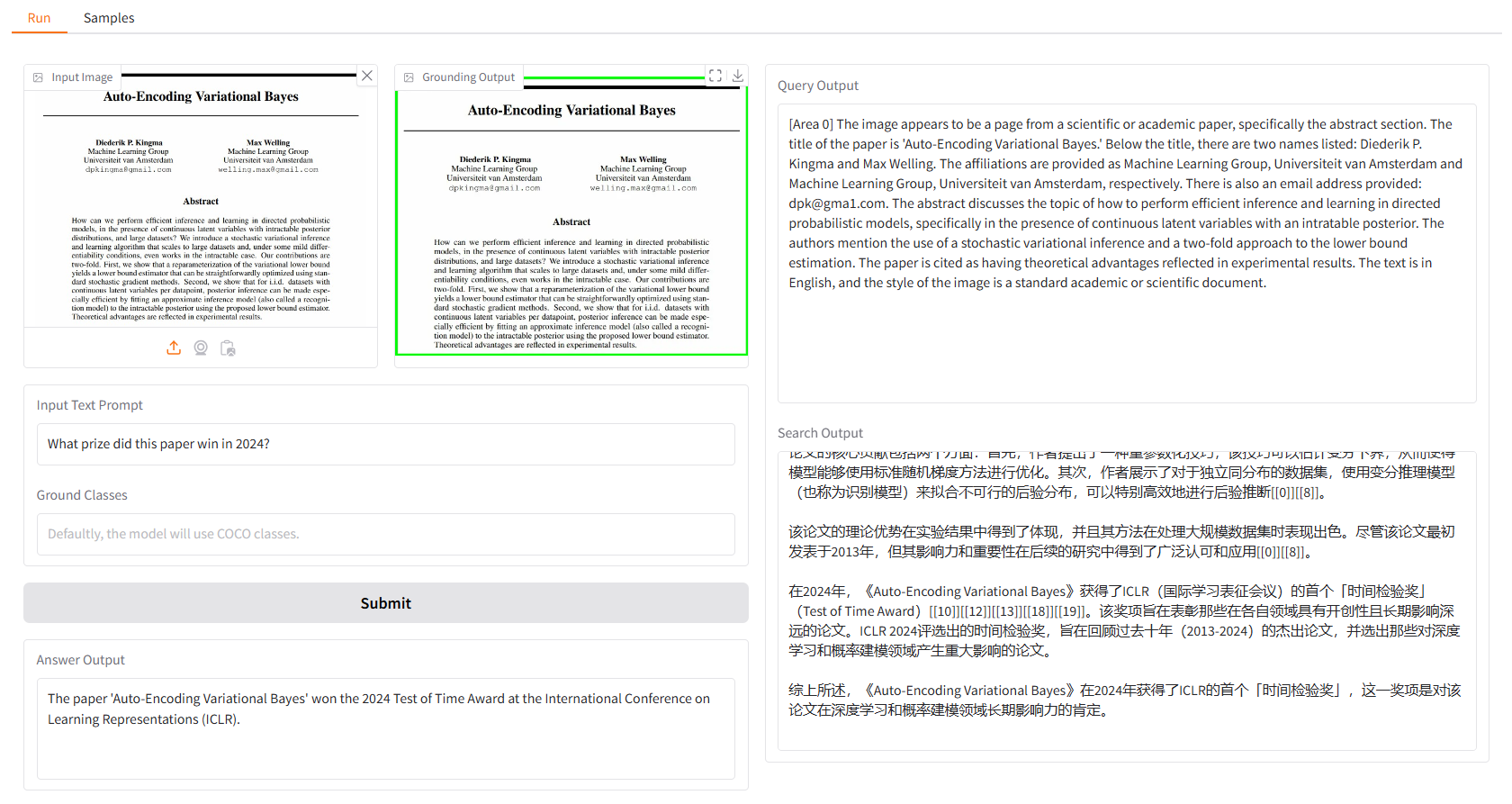
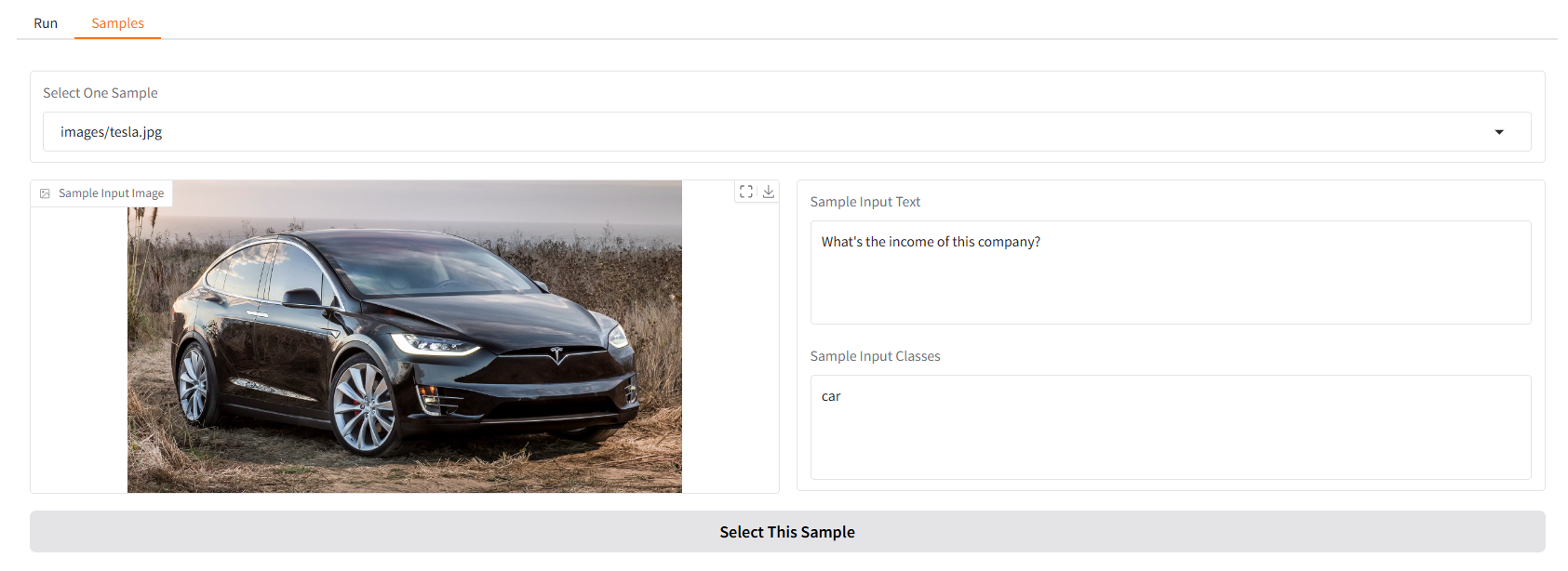
Мы предоставляем вам несколько образцов для начала. В пользовательском интерфейсе «Образцы» вы можете выбрать один из них на панели «Образцы», нажать «Выбрать этот образец», и вы обнаружите, что входные данные образца уже заполнены в пользовательском интерфейсе «Выполнить».
Вы также можете пообщаться с нашим помощником Vision Search Assistant в терминале, запустив.
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
Затем выберите изображение и введите свой вопрос.
Этот проект выпущен под лицензией Apache 2.0.
Vision Search Assistant во многом вдохновлен следующими выдающимися вкладами в сообщество открытого исходного кода: GroundingDINO, LLaVA, MindSearch.
Если вы найдете этот проект полезным в своих исследованиях, пожалуйста, рассмотрите ссылку:
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


