ndvr
1.0.0
2-е место на хакатоне нейронного поиска?
Мы стали свидетелями взрывного роста видеоданных на различных веб-сайтах для обмена видео, причем в Интернете доступны миллиарды видеороликов, и становится серьезной проблемой выполнение почти дублированного извлечения видео (NDVR) из крупномасштабной базы данных видео. Целью NDVR является извлечение почти повторяющихся видео из огромной базы данных видео, где почти повторяющиеся видео определяются как видео, визуально близкие к исходным видео.
У пользователей есть сильный стимул скопировать популярное короткое видео и загрузить дополненную версию, чтобы привлечь внимание. С ростом количества коротких видеороликов появляются новые трудности и проблемы для обнаружения дубликатов коротких видеороликов.
Здесь мы создали решение для нейронного поиска с использованием Jina для решения проблемы NDVR.
Оглавление

Пример позитивных видеороликов кандидатов. Верхний ряд: боковая морщинка, цветная фильтрация и промывка водой. Средний ряд: горизонтальный экран заменен на вертикальный с большими черными полями. Нижний ряд: повернут
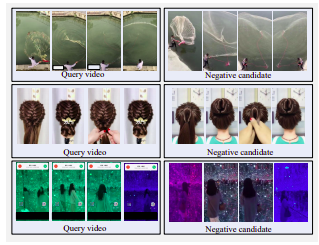
Пример жесткого негатива в видео. Все кандидаты визуально похожи на запрос, но не являются почти дубликатами.
Существует три стратегии выбора видео-кандидатов:
Мы решили использовать стратегию преобразованного поиска из-за ограничений по времени и ресурсам. В реальных приложениях пользователи будут копировать популярные видео в личных целях. Пользователи обычно предпочитают слегка изменять свои скопированные видео, чтобы обойти обнаружение. Эти модификации содержат обрезку видео, вставку границ и так далее.
Чтобы имитировать такое поведение пользователя, мы определяем одно временное преобразование, т. е. ускорение видео, и три пространственных преобразования, т. е. обрезку видео, вставку черной рамки и вращение видео.
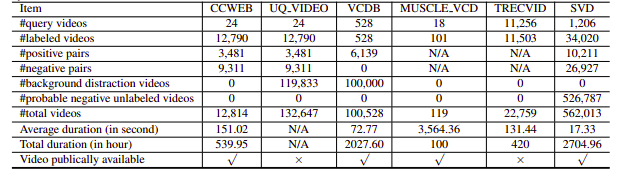
К сожалению, исследованные наборы данных NDVR были либо с низким разрешением, либо огромными, либо специфичными для конкретной области, либо не были общедоступными (мы также связались с немногими лично). Поэтому мы решили создать небольшой собственный набор данных для экспериментов.
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexИндекс Flow определяется следующим образом:
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : trueЭто разбивается на следующие этапы:
Здесь мы используем файл YAML для определения потока и используем его для индексации данных. Функция index принимает параметр input_fn , который использует итератор для передачи путей к файлам, которые в дальнейшем будут заключены в IndexRequest и отправлены в поток.
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query Затем вы можете открыть Jinabox с пользовательской конечной точкой http://localhost:45678/api/search
Поток запроса определяется следующим образом:
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.ymlПоток запроса разбивается на следующие этапы:


