CrawlerTutorial
1.0.0
Когда мы просматриваем Интернет, мы часто видим разнообразный интересный контент, такой как новости, продукты, видео, изображения и т. д. Но если вы хотите собрать большой объем конкретной информации с этих веб-страниц, ручные операции будут отнимать много времени и утомительны.
В этот раз вам пригодится веб-сканер (Web Crawler)! Проще говоря, веб-сканер — это программа, которая может имитировать поведение человеческого браузера и автоматически сканировать веб-информацию. Используя возможности автоматизации этой программы, мы можем легко «сканировать» интересующие нас данные с сайта и затем сохранять эти данные для последующего анализа.
Обычно веб-сканер сначала отправляет HTTP-запрос на целевой веб-сайт, затем получает HTML-ответ от веб-сайта, анализирует содержимое страницы и затем извлекает полезные данные. Например, если мы хотим собрать название, автора, время и другую информацию о статьях на доске новостей PTT, мы можем использовать технологию веб-сканера для автоматического сбора этой информации и ее хранения. Таким образом, вы можете получить необходимую информацию, не просматривая веб-сайт вручную.
Веб-сканеры имеют множество практических применений, таких как:
Конечно, при использовании веб-сканеров мы должны соблюдать условия использования веб-сайта и политику конфиденциальности и не можем сканировать информацию в нарушение правил веб-сайта. В то же время, чтобы обеспечить нормальную работу веб-сайта, нам также необходимо разработать соответствующие стратегии сканирования, чтобы избежать чрезмерной нагрузки на веб-сайт.
В этом руководстве используется Python3, а для установки необходимых пакетов будет использоваться pip. Необходимо установить следующие пакеты:
requests : используется для отправки и получения HTTP-запросов и ответов.requests_html : используется для анализа и сканирования элементов HTML.rich : позволяет красиво выводить информацию на консоль, например, отображать красивую таблицу.lxml или PyQuery : используется для анализа элементов HTML.Используйте следующие инструкции для установки этих пакетов:
pip install requests requests_html rich lxml PyQueryВ основной главе мы кратко расскажем, как собирать данные с веб-страницы PTT, такие как название статьи, автор и время.
Давайте использовать статьи PTT о чтении версий в качестве целей нашего сканера!
При сканировании веб-страницы мы используем функцию requests.get() , чтобы имитировать отправку браузером HTTP-запроса GET для «просмотра» веб-страницы. Эта функция вернет объект requests.Response , который содержит содержимое ответа веб-страницы. Однако следует отметить, что этот контент представлен в виде чистого текстового исходного кода и не отображается браузером. Мы можем получить его через свойство response.text .
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )
В дальнейшем нам requests_html requests_html.HTML requests_html для расширения requests Помимо просмотра как в браузере, нам также необходимо response.text веб-страницы HTML. Перезапись также очень проста. Используйте session.get() для замены приведенного выше requests.get() .
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )Однако когда мы пытаемся применить этот метод к сплетням, мы можем столкнуться с ошибками. Это связано с тем, что когда мы впервые просматриваем доску сплетен, веб-сайт подтвердит, что нам больше 18 лет, когда мы нажмем для подтверждения, браузер запишет соответствующие файлы cookie, чтобы мы не спрашивали снова в следующий раз; войти (Вы можете попробовать использовать режим инкогнито, чтобы открыть тест и посмотреть домашнюю страницу версии Bagua). Однако для веб-сканеров нам необходимо записать этот специальный файл cookie, чтобы мы могли притвориться, что прошли тест восемнадцатилетней давности во время просмотра.
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text ) Далее мы можем использовать метод response.html.find() , чтобы найти элемент, и использовать селектор CSS, чтобы указать целевой элемент. На этом этапе мы можем заметить, что в веб-версии PTT информация о заголовке каждой статьи находится в теге div с категорией r-ent . Поэтому мы можем использовать CSS-селектор div.r-ent для нацеливания на эти элементы.
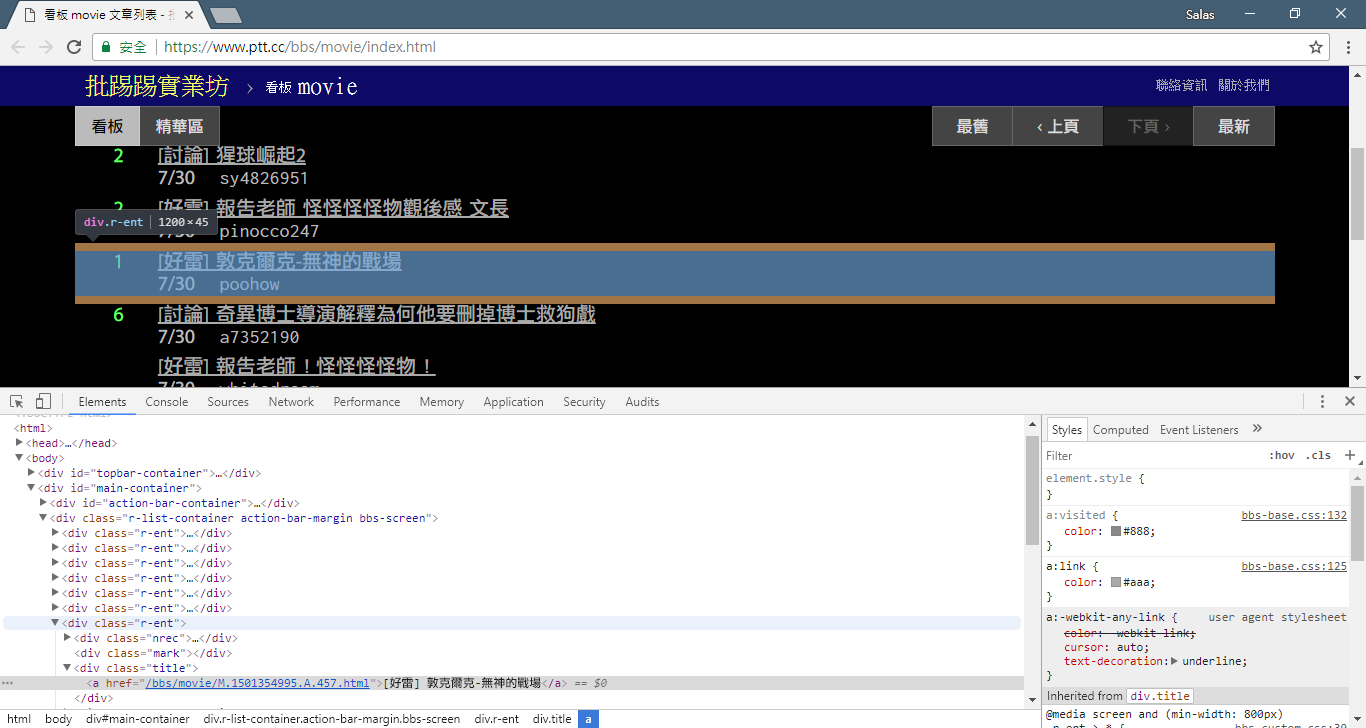
Использование метода response.html.find() вернет список элементов, соответствующих условиям, поэтому мы можем использовать цикл for для обработки этих элементов один за другим. Внутри каждого элемента мы можем использовать метод element.find() для дальнейшего анализа элемента и использовать селекторы CSS для указания информации для извлечения. В этом примере мы можем использовать селектор CSS div.title для нацеливания на элемент заголовка. Аналогичным образом мы можем использовать свойство element.text для получения текстового содержимого элемента.
Вот пример кода с использованием requests_html :
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... На предыдущем шаге мы использовали метод response.html.find() для поиска элементов каждой статьи. Эти элементы выбираются с помощью селектора CSS div.r-ent . Вы можете использовать функцию «Инструменты разработчика», чтобы наблюдать за структурой элементов веб-страницы. После открытия веб-страницы и нажатия клавиши F12 отобразится панель инструментов разработчика, содержащая HTML-структуру веб-страницы и другую информацию.
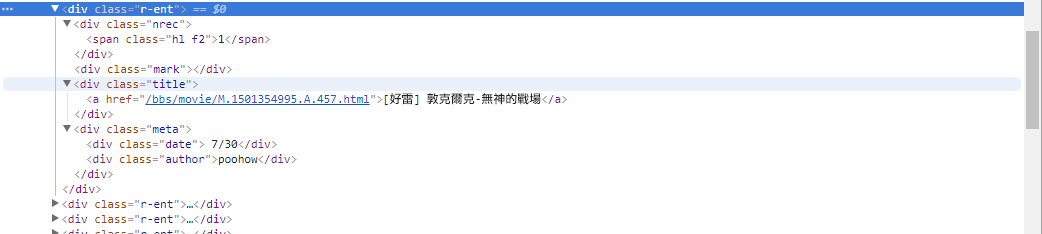
Используя инструменты разработчика, вы можете использовать указатель мыши, чтобы выбрать определенный элемент на веб-странице, а затем просмотреть структуру HTML элемента, атрибуты CSS и другие сведения на панели инструментов разработчика. Это поможет вам определить, на какой элемент следует ориентироваться, и соответствующий селектор CSS. Кроме того, вы сможете узнать, почему программа иногда дает сбой? ! Просматривая веб-версию, я обнаружил, что при удалении статьи на странице結構исходного кода элемента <本文已被刪除> на веб-странице отличалась от исходной! Таким образом, мы можем еще больше усилить его, чтобы справиться с ситуацией, когда статьи удаляются.
Теперь давайте вернемся к примеру кода для извлечения информации с помощью requests_html :
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )Выходная обработка текста:
Здесь мы можем использовать rich для отображения красивых результатов. Сначала создайте объект rich table, а затем замените print в цикле приведенного выше примера кода на add_row в таблицу. Наконец, мы используем функцию print rich для правильного вывода таблицы на терминал.
Результат выполнения
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )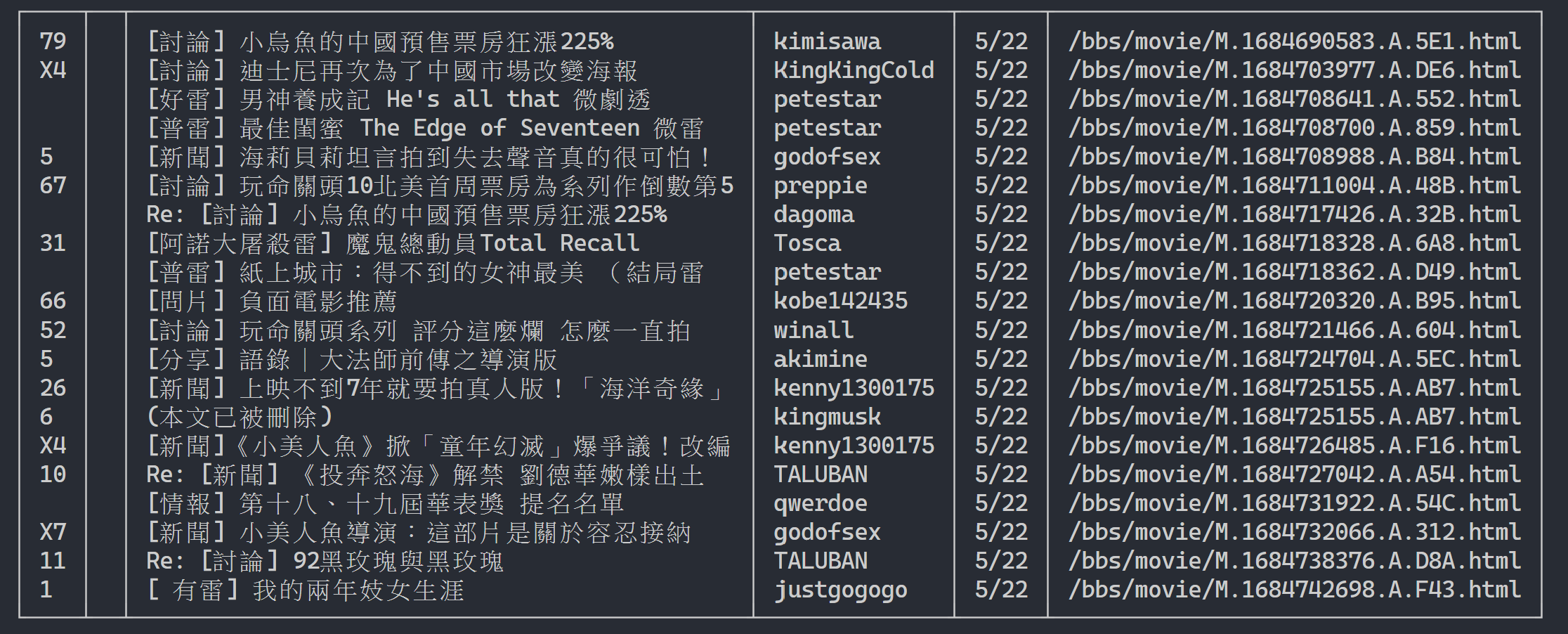
Теперь воспользуемся «методом наблюдения», чтобы найти ссылку на предыдущую страницу. Нет, я спрашиваю вас не о том, где находится кнопка в вашем браузере, а о «дереве исходников» в инструментах разработчика. Я полагаю, вы обнаружили, что гиперссылка для перехода на страницу находится в элементе <a class="btn wide"> <div class="action-bar"> . Поэтому мы можем извлечь их следующим образом:
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )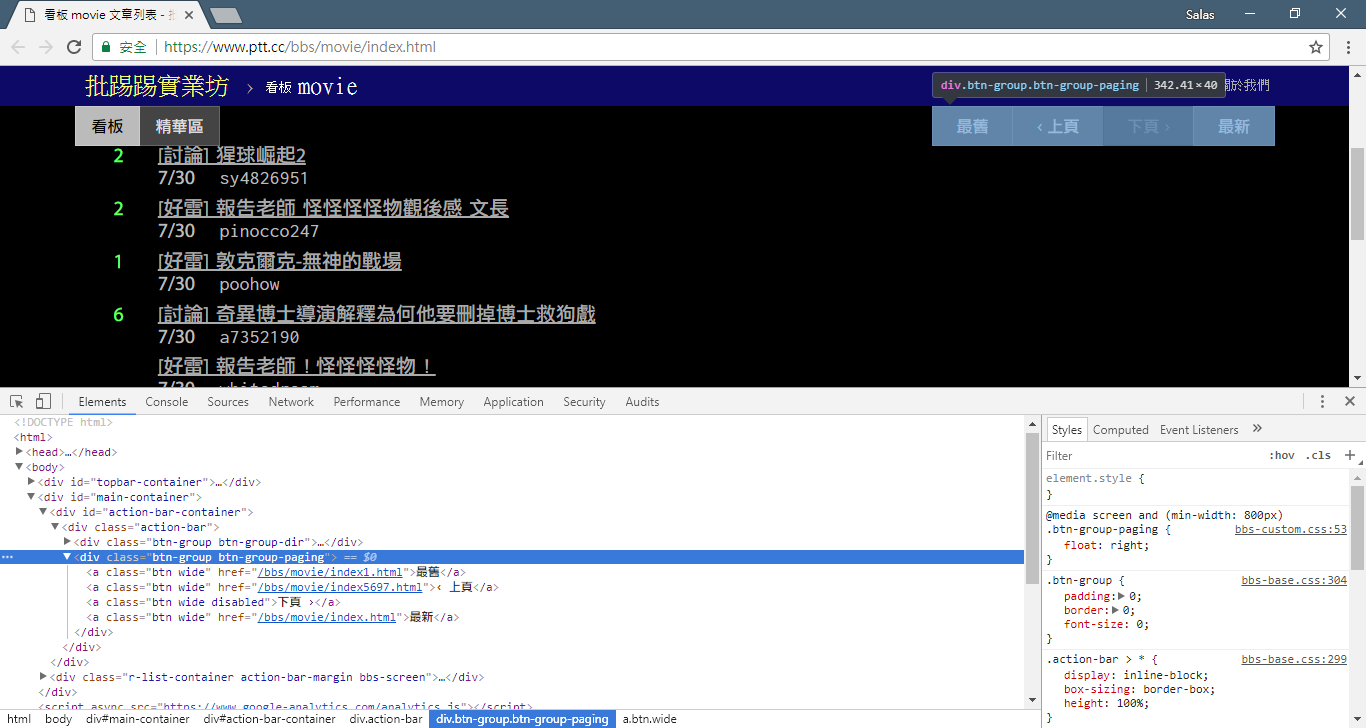
Нам нужна функция «предыдущая страница». Почему? Поскольку последние статьи в PTT отображаются спереди, поэтому, если вы хотите найти информацию, вам необходимо прокрутить вперед.
Так как же его использовать? Сначала возьмите второй href в control (индекс равен 1), тогда он может выглядеть так /bbs/movie/index3237.html , а полный адрес веб-сайта (URL) должен быть https://www.ptt.cc/ ( URL-адрес домена), поэтому используйте urljoin() (или прямое строковое соединение), чтобы сравнить и объединить ссылку на домашнюю страницу фильма с новой ссылкой в полный URL-адрес!
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url Теперь давайте изменим функцию, чтобы облегчить последующее объяснение. Давайте изменим пример обработки каждого элемента статьи на шаге 3: давайте посмотрим на эти сообщения заголовка в независимую функцию parse_article_entries(elements)
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return resultsДалее мы можем обрабатывать многостраничный контент.
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_urlРезультат вывода:
После получения информации о списке статей следующим шагом будет получение содержания статьи (статьи PO) (контента публикации)! link в метаданных — это ссылка на каждую статью. Мы также используем urllib.parse.urljoin для объединения полного URL-адреса, а затем вызываем HTTP GET для получения содержимого статьи. Мы можем заметить, что задача по захвату содержания каждой статьи сильно повторяется и очень подходит для обработки с использованием метода распараллеливания.
В Python вы можете использовать multiprocessing.Pool для высокоуровневого программирования многопроцессорности. Это самый простой способ использовать многопроцессорность в Python! Он очень подходит для сценария применения SIMD (одна инструкция и несколько данных). Используйте синтаксис оператора with для автоматического освобождения ресурсов процесса после использования. Использование ProcessPool также очень просто: pool.map(function, items) , что немного похоже на концепцию функционального программирования. Примените функцию к каждому элементу и, наконец, получите такое же количество списков результатов, как и элементов.
Используется в задаче сканирования содержимого статьи, представленной ранее:
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )Прилагаю результаты экспериментов:
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章Видно, что общая скорость выполнения увеличилась почти в пять раз, но чем больше Process тем лучше. Помимо аппаратных характеристик, таких как процессор, это в основном зависит от ограничений внешних устройств, таких как сетевые карты и т. д. скорости сети.
Приведенный выше код можно найти в ( src/basic_crawler.py )!
Новая функция в PTT Web: Поиск! Наконец-то доступно в веб-версии
Давайте также будем использовать киноверсию PTT в качестве цели нашего сканера! Контент, доступный для поиска в новой функции, включает в себя:
Первые три могут находить правила из новой версии исходного кода страницы и отправлять запросы, но поиск по количеству твитов, похоже, не появился в интерфейсе пользовательского интерфейса веб-версии, поэтому вот параметры, полученные автором из PTT 網站原始碼; PTT 網站原始碼. PTT, который мы обычно просматриваем, на самом деле включает в себя сервер BBS (то есть BBS) и интерфейсный веб-сервер (веб-версию). Интерфейсный веб-сервер написан на языке Go (Golang) и может напрямую обращаться к серверной части. Данные BBS и их использование. Общий режим взаимодействия с веб-сайтом преобразует содержимое в веб-страницу для просмотра.
На самом деле использовать эти новые функции очень просто. Вам нужно всего лишь использовать HTTP запрос GET и добавить стандартную строку запроса для получения этой информации. URL-адрес endpoint , обеспечивающий функцию поиска, — /bbs/{看板名稱}/search . Просто используйте соответствующий запрос, чтобы получить результаты поиска отсюда. Во-первых, возьмем в качестве примера ключевое слово title:
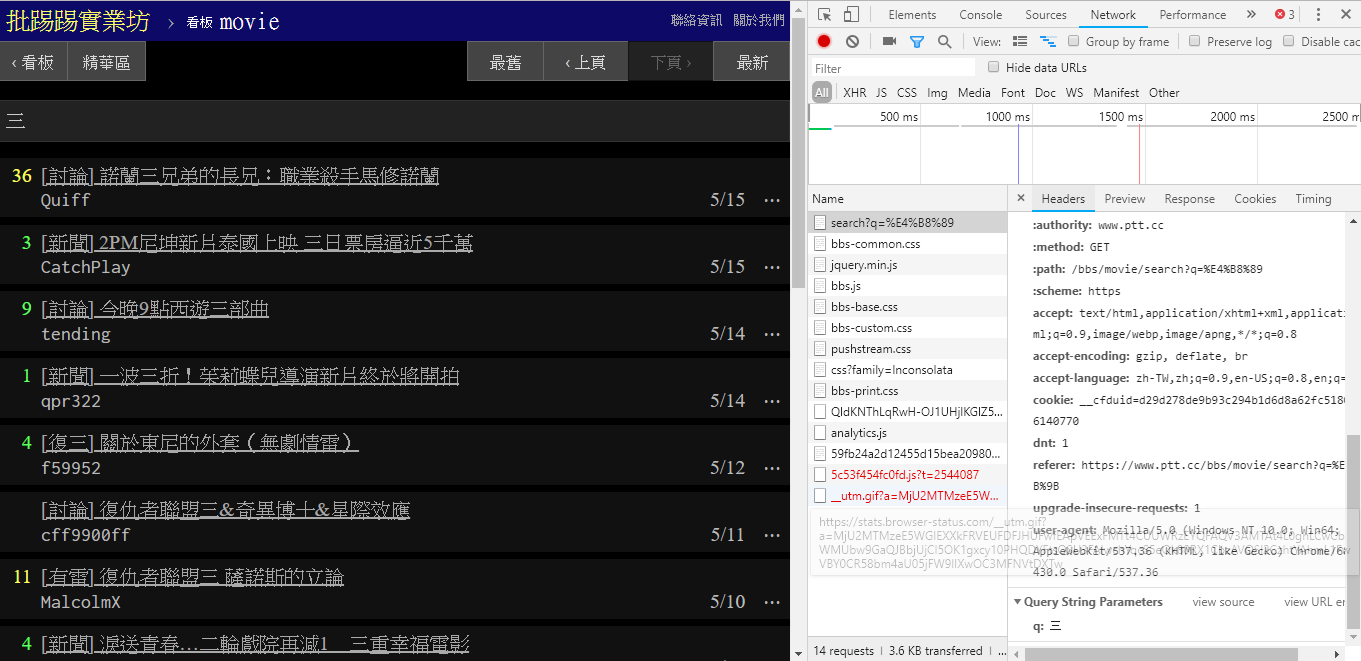
Как видно из правого нижнего угла картинки, при поиске на endpoint фактически отправляется GET запрос с q=三, поэтому весь полный URL-адрес должен иметь вид https://www.ptt.cc/bbs/movie/search?q=三, URL-адрес, скопированный из адресной строки, может иметь вид https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89 поскольку китайский язык В кодировке HTML, но имеет то же значение. В requests , если вы хотите добавить дополнительные параметры запроса, вам не нужно вручную создавать строковую форму. Вам просто нужно поместить их в параметры функции через dict() параметра param= , вот так:
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })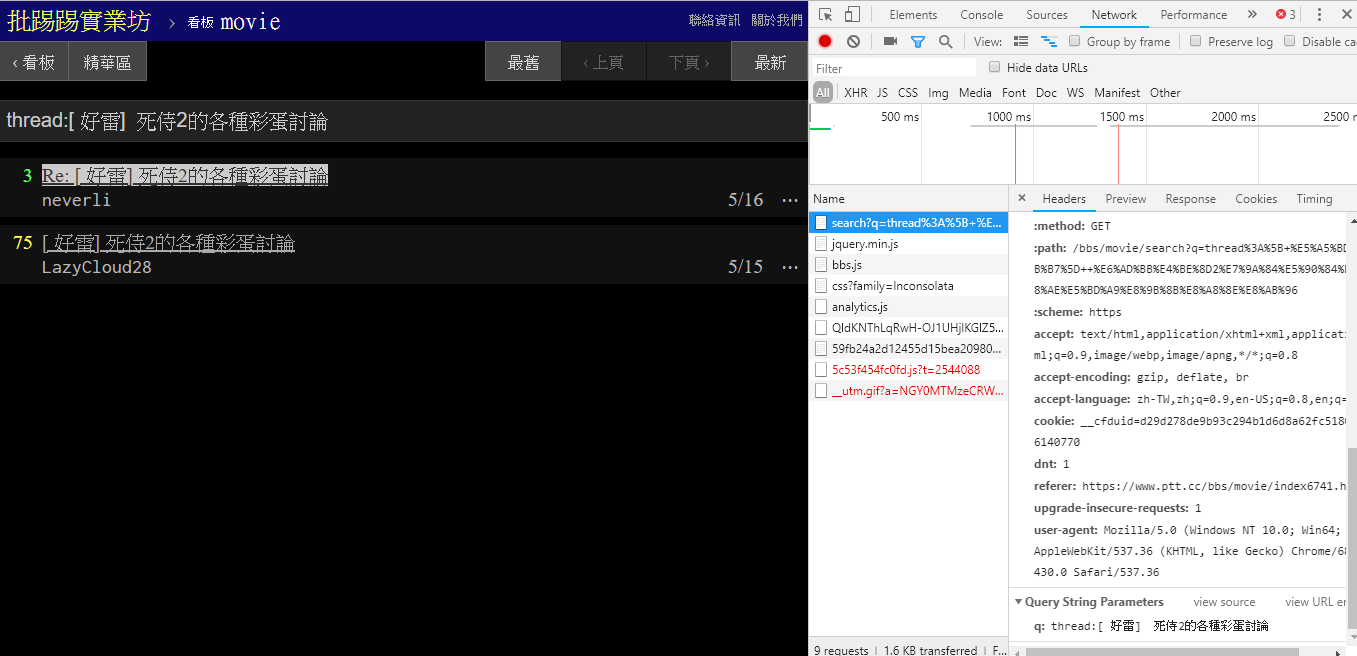
При поиске той же статьи (темы) по информации в правом нижнем углу видно, что вы на самом деле набираете строку thread: перед заголовком и отправляете запрос.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })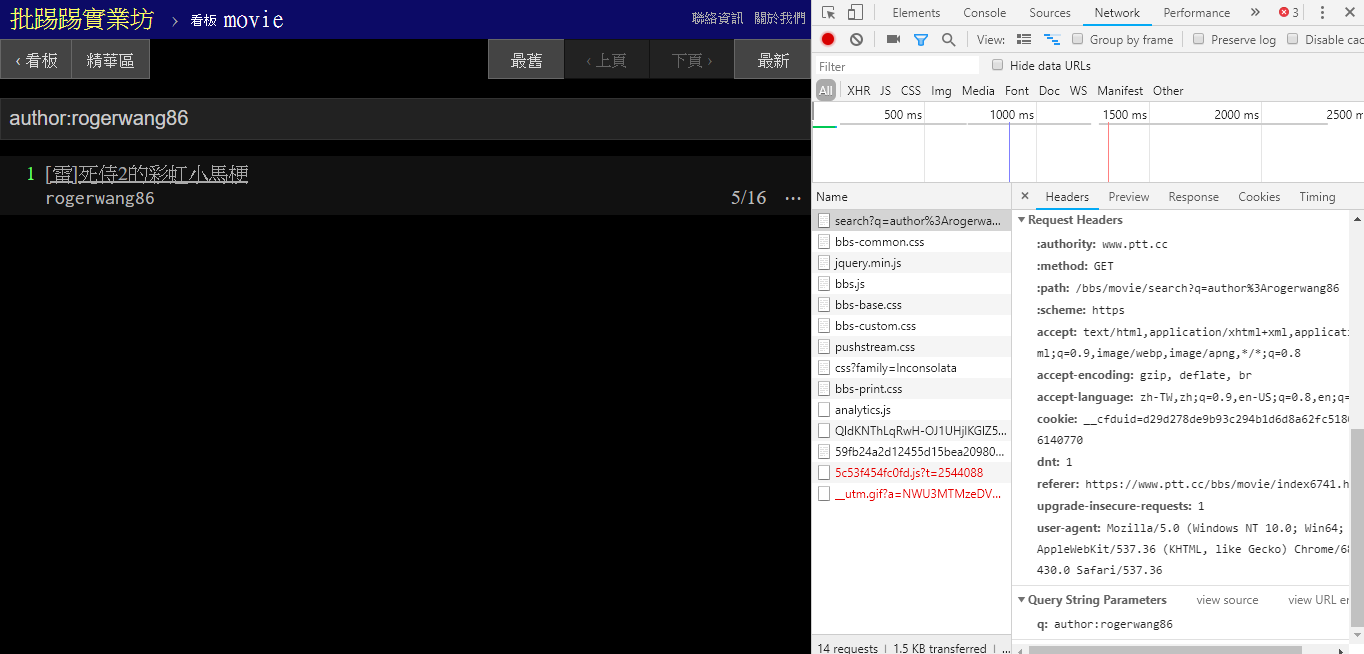
При поиске статей с одним и тем же автором (автором) из информации в правом нижнем углу также видно, что строка author: объединяется с именем автора и затем отправляется запрос.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })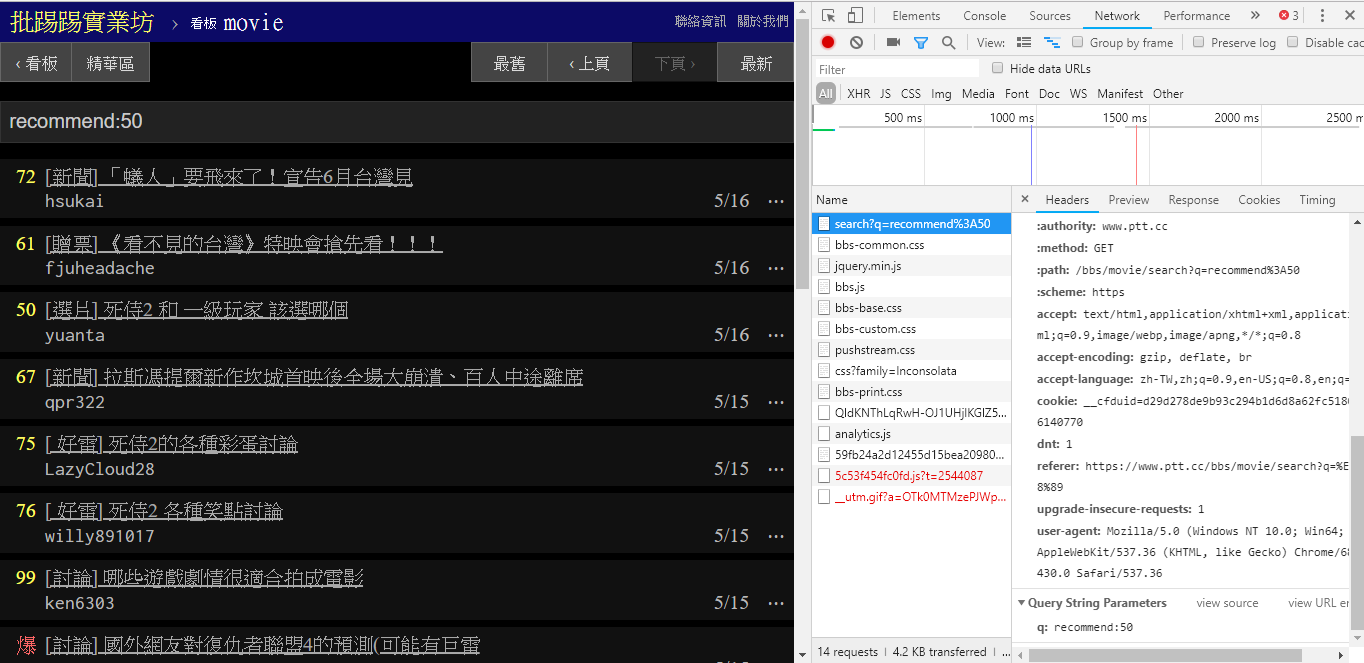
При поиске статей с количеством твитов, превышающим (рекомендуется), введите строковую recommend: с минимальным количеством твитов, которые вы хотите найти, а затем отправьте запрос. Кроме того, из исходного кода веб-сервера PTT можно узнать, что количество твитов можно установить только в пределах ±100.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })Исходный код функции веб-анализа PTT этих параметров
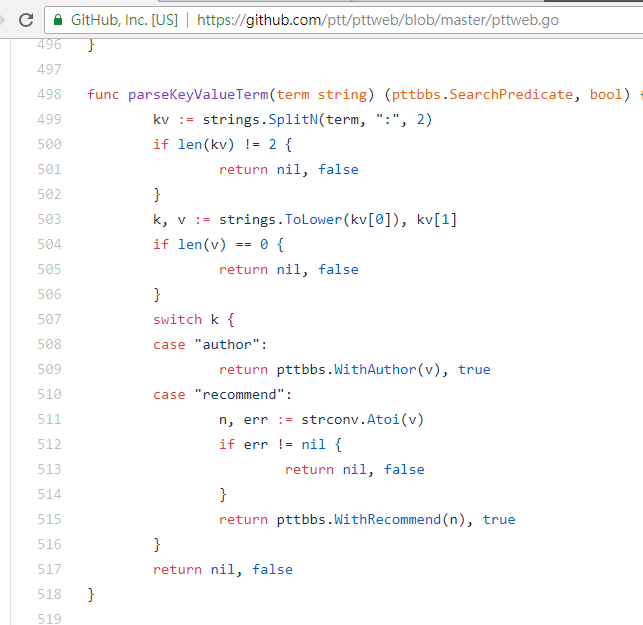
Также стоит отметить, что окончательное представление результатов поиска такое же, как и общий макет, упомянутый в основах, поэтому вы можете напрямую повторно использовать предыдущие функции. Don't do it again!
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用] В поиске есть еще один параметр. Количество page аналогично поиску Google. Искомый объект может иметь много страниц, поэтому вы можете использовать этот дополнительный параметр, чтобы контролировать, какую страницу результатов вы хотите получить, без необходимости анализировать ссылку. страница.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 }) Интеграция всех предыдущих функций в ptt-parser может предоставить функции командной строки и爬蟲в виде API, которые можно вызывать программно.
scrapy для стабильного сканирования данных PTT.
Эта работа была создана leVirve и выпущена под международной лицензией Creative Commons Attribution 4.0.


