project omega
Последний шаблон корпоративной веб-архитектуры, который вам когда-либо понадобится. До следующего.
ТЛ;ДР
Цель состоит в том, чтобы оптимизировать работу разработчиков, имея возможность:
- Развивайтесь локально, как если бы это был монолит
- Развертывание как отдельные микросервисы
- Смоделируйте производственную среду локально с помощью Docker
Демо
project omega Proof of Concept — гибрид монолита микросервисов
Демонстрация project omega — микросерверы Kubernetes и развертывание автономного контейнера
Почему
Я хочу доказать, что нам не нужно жертвовать эффективностью разработчиков ради масштабируемости. Более подробное обсуждение плюсов и минусов микросервисов и монолитов можно найти здесь: Микросервисы и монолиты.
У меня сложилось впечатление, что многие отраслевые эксперты хотят, чтобы мы поверили, что это три наших основных варианта:
- Монолит
- Микросервисы
- «Гибрид» (не совсем гибрид, одновременно монолит и еще какие-то микросервисы)
Я хочу показать, что нам не обязательно выбирать какой-либо из этих вариантов. Проявив немного творчества, мы можем создать настоящий «гибрид», который одновременно представляет собой монолит и набор микросервисов. Я не думаю, что с помощью моей нынешней стратегии мы сможем устранить все недостатки монолита и микросервисов, но мы можем избавиться от многих болевых точек обоих.
Что это не так
- Я не пытаюсь создать структуру (по крайней мере, пока...). Я просто в качестве эксперимента собираю все имеющиеся у меня лего в другую конфигурацию.
- Это не проект сообщества. Я намерен часто вносить кардинальные изменения без предварительного уведомления. Если эта концепция кажется вам интересной и вы хотите внести свой вклад, сначала свяжитесь со мной.
Цели проекта
- Создайте шаблон, который будет работать как с небольшими проектами-хобби для одного разработчика, так и масштабироваться для десятков или даже сотен разработчиков, работающих над большими и сложными корпоративными веб-приложениями.
- Иметь возможность разрабатывать локально, как если бы это был монолит:
- Один репозиторий. По тем же причинам компании выбирают подход монорепо.
- Максимум 3 процесса для запуска (пользовательский интерфейс клиента, сервер, зависимости докера с базой данных, очередь сообщений и т. д.). Мы не хотим, чтобы страницы документации по настройке запускались и работали.
- Уметь развертывать как микросервисы.
- Уметь моделировать производственную среду с микросервисами, работающими в докер-контейнерах.
- Чрезвычайно быстрое время установки. Все зависимости, кроме Node и .NET, должны быть включены как зависимости Docker (база данных, очередь сообщений и т. д.). Новые пользователи должны иметь возможность устанавливать .NET, Node, клонировать репозиторий, а затем выполнять команды установки и запуска.
- Чрезвычайно быстрая горячая перезагрузка как клиента, так и сервера в среде разработки.
- Уметь разрабатывать и запускать приложения на Windows, Linux и Mac.
- Уметь быстро развернуть новую услугу.
Технический стек
Стек технологий по большей части не имеет значения для концепции высокого уровня, которую я пытаюсь доказать, но для этого проекта я собираюсь использовать:
- .NET 5 для сервисов
- Интерфейс React (базовое приложение create-react с машинописным текстом)
- Докер
Концепции высокого уровня
Компании с большими приложениями все больше и больше подталкиваются к микросервисам, чтобы иметь возможность горизонтального масштабирования (среди других причин). Итак, чтобы добиться этого, мы рассматриваем что-то вроде следующего:
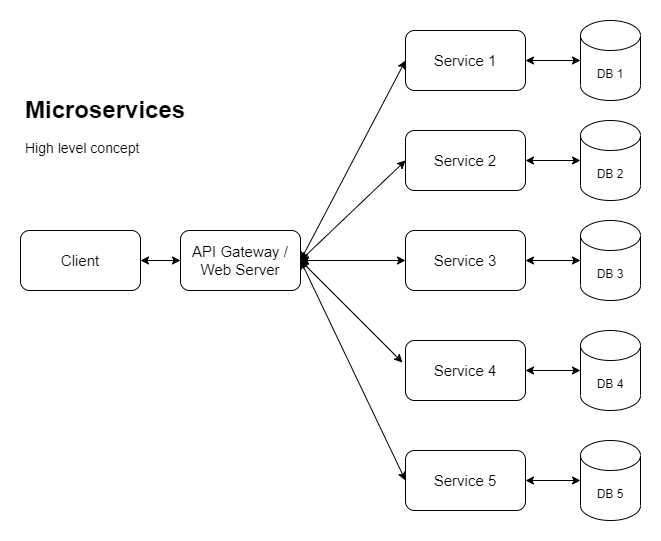
Вот еще одна версия, показывающая один из способов реализации горизонтального масштабирования:
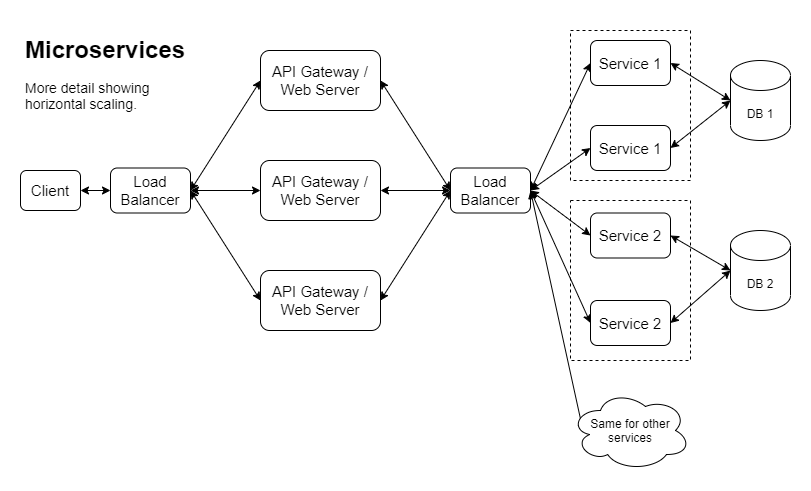
Если мы пойдем по этому пути, мы столкнемся с настоящей проблемой местного развития. Это действительно зависит от того, что представляет собой продукт, сколько в нем разработчиков, кто над чем работает и как часто. При этом большая часть компаний, выбирающих микросервисы, окажутся в ситуации, когда разработчикам придется делать трудный выбор в отношении того, как вести повседневную разработку. Цель project omega — показать, что мы можем устранить накладные расходы на локальный запуск службы, объединив их все в одно приложение при локальном запуске:
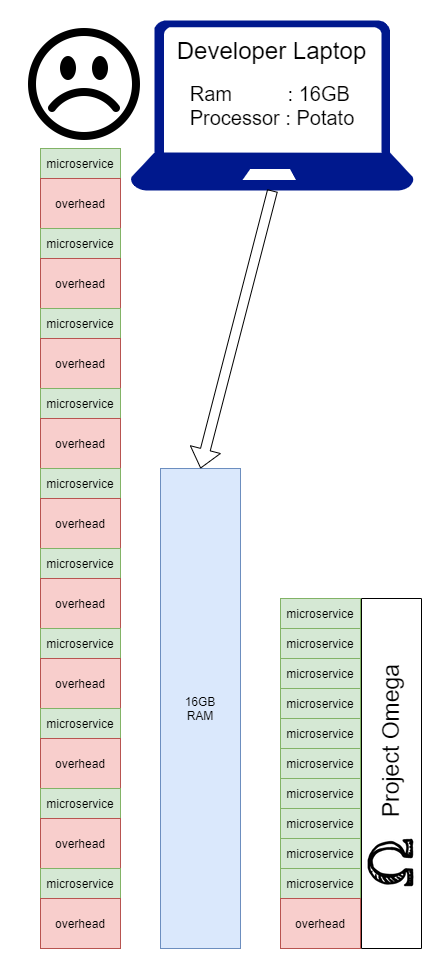
Вот структура папок:
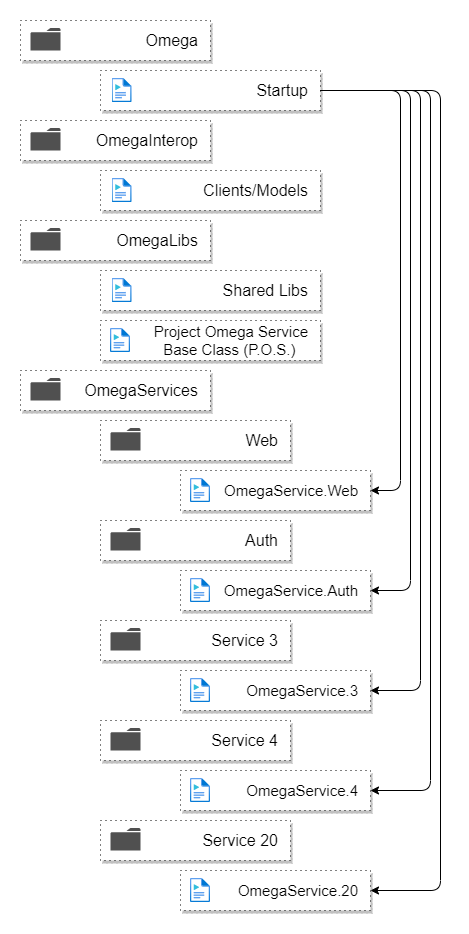
А вот как это будет выглядеть в виде микросервисов:
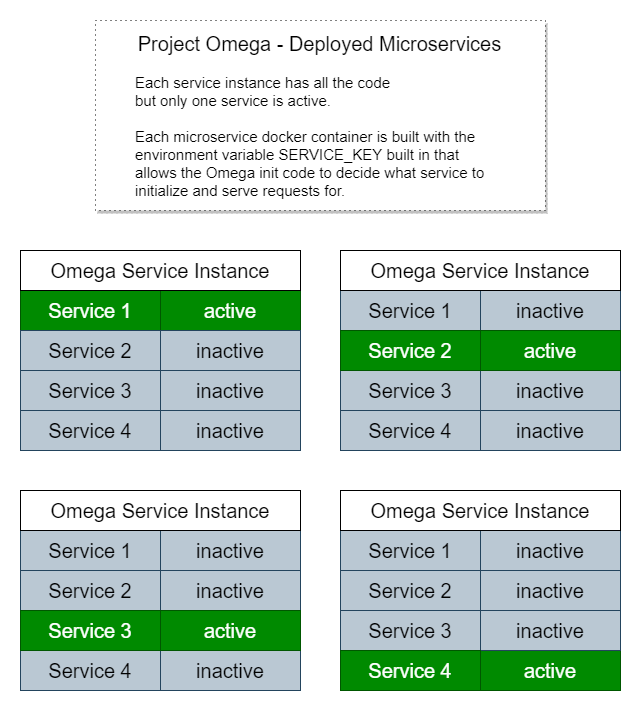
Каждый экземпляр имеет копию всего кода, но выполняет только инициализацию, маршруты конечных точек службы и рабочие процессы для определенного микросервиса.
Вот почему так просто запустить приложение локально как монолит: мы просто ищем переменную среды с именем SERVICE_KEY или, если она отсутствует, инициализируем все службы.
Примеры инициализации других служб:
- Настройка внедрения зависимостей
- Строки подключения к базе данных
- Миграция базы данных
- Инициализация очереди сообщений
- Настройка подключения к распределенному кэшу
- Настройка подключения к другим облачным ресурсам
- Инициализация стороннего API
При вызове Startup он сканирует сборки на наличие типов, наследующих ProjectOmegaService , создает экземпляр и запускает логику инициализации этого сервиса. При локальном запуске они будут запускаться все.
Инструкции по настройке
Установите необходимые условия:
Обратите внимание: для запуска последней версии Docker в Windows могут потребоваться некоторые дополнительные действия, если вы не делали этого какое-то время, например, установка WSL 2 и обновление дистрибутива WSL. Следуйте инструкциям на сайте Docker.
Шаги:
- Клонировать этот репозиторий
- В терминале из корня репо запустите
yarn run installAll - Если вы хотите запустить SQL-сервер на порте, отличном от 1434:
- Запустите
yarn run syncEnvFiles - Измените
OMEGA_DEFAULT_DB_PORT и OMEGA_MSSQL_HOST_PORT в .env.server
- Запустите зависимости с помощью команды
yarn run dockerDepsUpDetached - Запускайте миграцию БД при первом запуске или когда вы получаете чужие изменения вместе с обновлениями базы данных:
yarn run dbMigrate - Запустите приложение в режиме локальной разработки, используя один из этих вариантов:
- Вариант 1: в терминале из корня репо запустите
yarn run both (это используется одновременно для запуска команд из варианта 2) - Вариант 2: использовать 2 отдельных терминала. В одном терминале запустите
yarn run client , а в другом запустите yarn run server
- Доступ к https://localhost:3000 (нажмите после предупреждения https)
Перед первым запуском модульных тестов с помощью dotnet test или после добавления модульных тестов в новую схему БД:
- Запустите зависимости, если они еще не запущены, с помощью
yarn run dockerDepsUpDetached - Запустить
yarn run testDbMigrate - Затем запустите
dotnet test
Чтобы смоделировать производство и микросервисы в докере:
- Убедитесь, что зависимости Docker работают с помощью
yarn run dockerDepsUpDetached - В терминале из корня репо запустите
yarn run dockerRecreateFull - Доступ к https://localhost:3000 (нажмите после предупреждения https)
Следующие шаги
- Регистрация изменений
- Поэкспериментируйте с форматером Serilog json.
- Добавьте идентификатор корреляции и другую контекстную информацию в записи журнала.
- Добавить дополнительную документацию
- Диаграммы того, как работает симуляция докера
- Докер-зависимости
- Текстовое описание что это такое и как работает
- Диаграммы того, как docker deps вписывается в процесс разработки
- Документация по маршрутизации/прокси
- Миграции БД
- RPC-тест между службами вместо вызовов отдыха HTTP (возможно, что-то вроде этого: https://github.com/aspnet/AspLabs/tree/main/src/GrpcHttpApi)
- Добавьте в базовый класс межсервисного клиента для абстрактной обработки и регистрации ошибок.
- Реализация аутентификации
- Регистрация на внешнем сайте
- Авторизация между службами (OAuth?)
- Автоматическое создание документации (вывод документации в формате swagger и html xml)
- Службы настройки очередей и рабочих процессов
- Определение абстрактной очереди (чтобы разрешить использование облачных сервисов в качестве опции)
- Базовая служба типа рабочего процесса с циклом событий для поиска сообщений
- RabbitMQ в docker-compose.deps.yml
- Базовая реализация RabbitMQ, подключенная к службе рабочего процесса
- Дополнительная локальная демонстрационная работа Kubernetes
- База данных, вероятно, потребует изучения того, как использовать постоянный том Kubernetes, если только я не смогу выяснить, как настроить сеть для предоставления доступа к базе данных хоста.
- Добавьте Seq или сделайте функцию Seq необязательной и не используйте ее при работе в Kubernetes.
- Метапроект/скрипт для анализа решения
- Анализировать затронутые службы на основе измененных файлов (для детализации развертывания).
- Строительные леса проекта:
- Возможность развернуть новую копию проекта, используя какой-либо другой «ключ» проекта, кроме Omega, для всех имен проектов/каталогов.
- Возможность запускать докер-контейнеры в новом проекте и эффективно проводить интеграционные тесты для обеспечения успешного создания нового проекта.
Разное
Если вы разрабатываете под Linux, вы можете столкнуться с этой ошибкой при запуске сервера:
System.AggregateException: произошла одна или несколько ошибок. (Достигнут настроенный пользователем предел (128) на количество экземпляров inotify или достигнут предел количества открытых файловых дескрипторов для каждого процесса.)
Вероятно, это вызвано тем, что vscode использует слишком много файлов для отслеживания. Вы можете увеличить лимит экземпляров inotify (а не только лимит наблюдателей, который, вероятно, уже установлен очень высоко в вашем файле /etc/sysctl.conf ), выполнив эту команду:
echo fs.inotify.max_user_instances=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -p
Другая документация
Анализ рентабельности шаблонов проектирования: DesignPatternCostBenefit.md
Варианты шаблонов проектирования: DesignPatternVariations.md
Решения: Decisions.md
Философия разработки программного обеспечения и разглагольствования: https://gist.github.com/mikey-t/3d5d6f0f5316abf9e74fb553be9fdef3


