nnl
gpt2-xl assets
nnl — это механизм вывода для больших моделей на платформе графического процессора с малым объемом памяти.
Большие модели слишком велики, чтобы поместиться в память графического процессора. nnl решает эту проблему, находя компромисс между пропускной способностью PCIE и памятью.
Типичный конвейер вывода выглядит следующим образом:
Благодаря пулу памяти графического процессора и дефрагментации памяти NNIL позволяет построить большую модель на платформе графического процессора начального уровня.
Это всего лишь хобби-проект, написанный за несколько недель, в настоящее время поддерживается только бэкэнд CUDA.
make lib nnl _cuda.a && make lib nnl _cuda_kernels.aЭта команда создаст две статические библиотеки: lib/lib nnl _cuda.a и lib/lib nnl _cuda_kernels.a . Первая — это основная библиотека с серверной частью CUDA на C++, а вторая — для ядер CUDA.
Демо-программа GPT2-XL (1.6B) представлена здесь. Эту программу можно скомпилировать этой командой:
make gpt2_1558mПосле загрузки всех весов из релиза мы можем запустить следующую команду на младшей платформе графического процессора, такой как GTX 1050 (память 2 ГБ):
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer " И вывод такой: 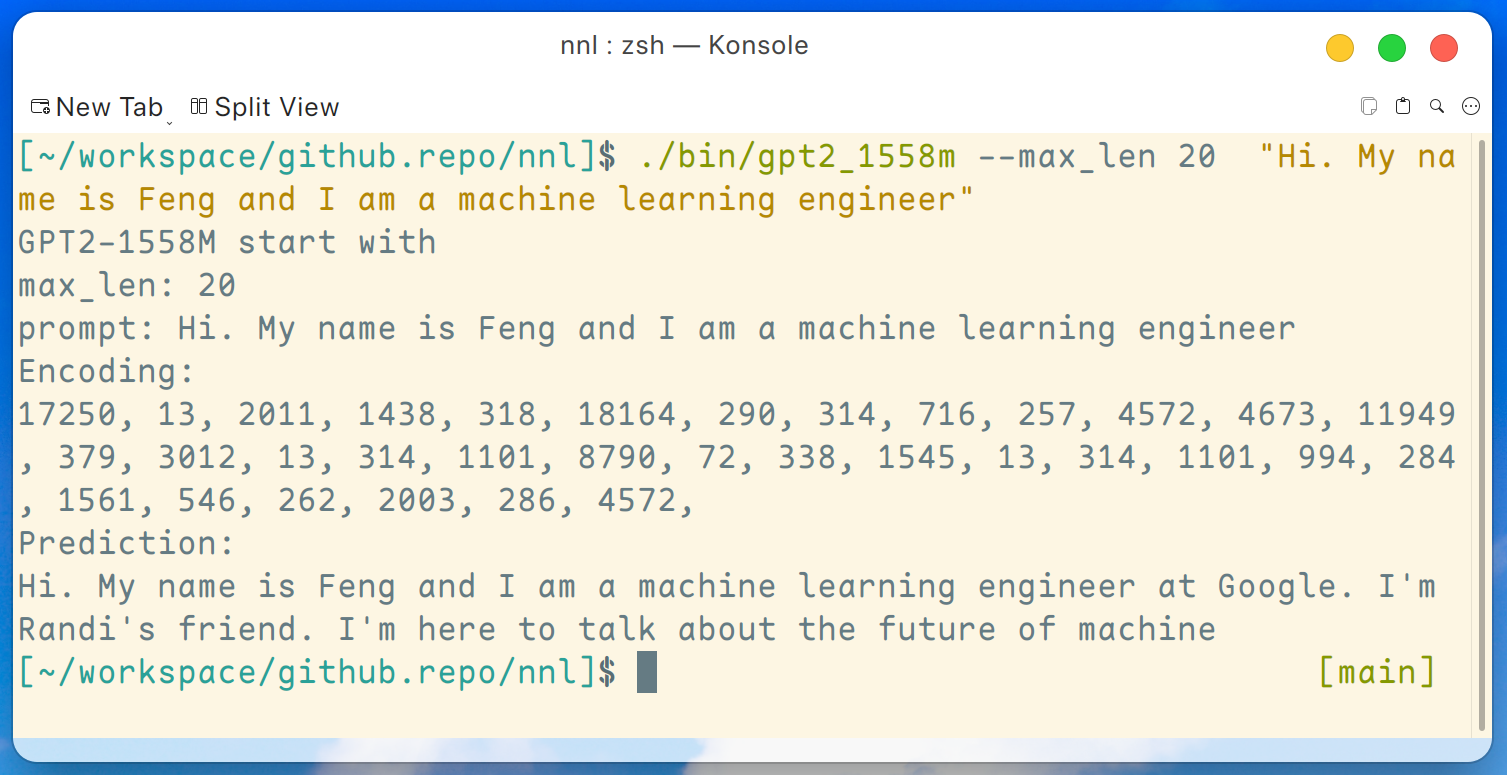
Отказ от ответственности: это всего лишь пример, созданный gpt2-xl, я не работаю в Google и не знаю Рэнди.
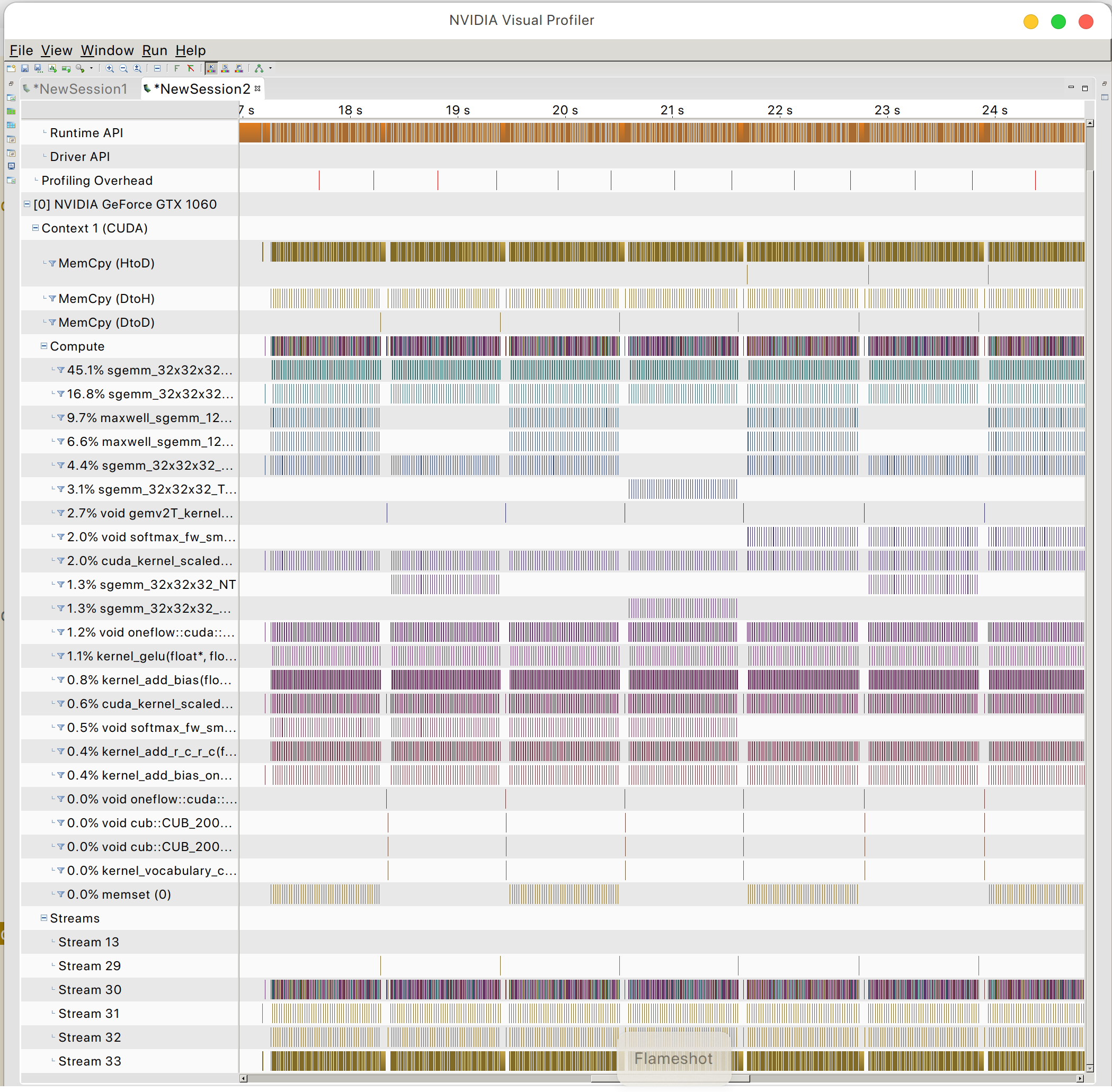
И вы можете найти шаблон доступа к памяти графического процессора.
МирOSL