DiSQ Score
1.0.0
Официальная реализация нашей статьи: Дискурсивный сократический опрос: оценка достоверности понимания дискурсивных отношений языковыми моделями (2024) Исонг Мяо, Хунфу Лю, Вэньцян Лэй, Нэнси Ф. Чен, Мин-Йен Кан. ACL 2024.
Документ PDF: https://yisong.me/publications/acl24-DiSQ-CR.pdf.
Слайды: https://yisong.me/publications/acl24-DiSQ-Slides.pdf.
Плакат: https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
Хотите узнать DiSQ Score для какой-либо языковой модели? Вы можете использовать эту однострочную команду!

Мы предоставляем упрощенную команду для оценки любой языковой модели (LM), размещенной в концентраторе моделей HuggingFace. Рекомендуется использовать это для любой новой модели (особенно для тех, которые не изучались в нашей статье).
bash scripts/one_model.sh <modelurl>
Переменная modelurl задает сокращенный путь в хабе Huggingface, например:
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
Перед запуском файлов bash отредактируйте файл bash, указав путь к локальному кэшу HuggingFace.
Например, в scripts/one_model.sh:
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
вы можете изменить YOUR_PATH на абсолютный каталог вашего Huggingface Cache (например, /disk1/yisong/hf-cache ).
Мы рекомендуем не менее 200 ГБ свободного места.
Выходной текстовый файл будет сохранен в data/results/verbalizations/Meta-Llama-3-8B.txt и будет содержать:
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
Мы храним наши наборы данных в файлах JSON, расположенных по адресу data/datasets/dataset_pdtb.json и data/datasets/dataset_ted.json . Например, давайте возьмем один экземпляр из набора данных PDTB:
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
Вот поля в этой словарной статье:
Didx : Идентификатор дискурса.arg1 и arg2 : два аргумента.DR .: Отношения дискурса.Conn : Дискурсивная связка.events : список пар, в котором хранятся пары событий, предсказанные как существенные сигналы.context : Контекст дискурса. cd DiSQ-Score
bash scripts/question_generation.sh
Этот bash-файл будет вызывать question_generation.py для генерации вопросов в различных конфигурациях.
Аргументы для question_generation.py следующие:
--dataset : указывает набор данных: pdtb или ted .--modelname : созданы псевдонимы для моделей. 13b относится к LLaMA2-13B, 13bchat — к LLaMA2-13B-Chat, а vicuna-13b к Vicuna-13B. Конкретные URL-адреса для этих моделей можно найти в disq_config.py .--version : указывает, какую версию шаблонов приглашений использовать, с параметрами v1 , v2 , v3 и v4 .--paraphrase : заменяет стандартные вопросы их перефразированными версиями с опциями p1 и p2 . В отличие от стандартных, вызывающих qa_utils.py , перефразированные функции вызывают qa_utils_p1.py и qa_utils_p2.py соответственно.--feature : указывает, какие лингвистические функции использовать для вопросов обсуждения. К лингвистическим особенностям относятся conn (дискурсивная связка) и context (контекст дискурса). Исторические данные контроля качества требуют отдельного сценария. Выходные данные будут храниться, например, в data/questions/dataset_pdtb_prompt_v1.json в конфигурации dataset==pdtb и version==v1 .
Мы просим наших пользователей самостоятельно генерировать вопросы, поскольку этот подход является автоматическим и помогает сэкономить место в нашем репозитории GitHub (который может занимать до ~ 200 МБ). Если вы не можете запустить файл bash, свяжитесь с нами для получения файлов с вопросами.
cd DiSQ-Score
bash scripts/question_answering.sh
Этот bash-файл вызовет question_answering.py для выполнения дискурсивного сократовского опроса (DiSQ) для любой заданной модели. question_answering.py принимает все аргументы из question_generation.py плюс следующие новые аргументы:
--modelurl : указывает URL-адрес для любых новых моделей, которых в данный момент нет в файле конфигурации. Например, «meta-llama/Meta-Llama-3-8B» указывает модель LLaMA3-8B и перезапишет аргумент modelname .--hf-path : указывает путь для хранения параметров большой модели. Рекомендуется не менее 200 ГБ свободного места на диске.--device_number : указывает идентификатор используемого графического процессора. Вывод будет сохранен, например, в data/results/13bchat_dataset_pdtb_prompt_v1/ . Прогноз для каждого вопроса представляет собой список токенов и их вероятностей, хранящийся в файле рассола в папке.
Предостережение: модель Wizard была удалена разработчиками. Мы советуем пользователям не пробовать эти модели. Посетите ветку обсуждения по адресу: https://huggingface.co/posts/WizardLM/329547800484476.
cd DiSQ-Score
bash scripts/eval.sh
Этот bash-файл вызовет eval.py для оценки ранее полученных прогнозов модели.
eval.py принимает тот же набор параметров, что и question_answering.py .
Результат оценки будет сохранен в disq_score_pdtb.csv если указанный набор данных — PDTB.
В CSV-файле 20 столбцов, а именно:
taskcode : указывает тестируемую конфигурацию, например dataset_pdtb_prompt_v1_13bchat .modelname : указывает, какая языковая модель тестируется.version : указывает версию приглашения.paraphrase : параметр для перефразирования.feature : указывает, какая функция была использована.Overall : общий DiSQ Score .Targeted : целевой показатель, один из трех компонентов DiSQ Score .Counterfactual : контрфактический показатель, один из трех компонентов DiSQ Score .Consistency : показатель согласованности, один из трех компонентов DiSQ Score .Comparison.Concession : DiSQ Score для данного конкретного дискурсивного отношения.Обратите внимание, что мы выбираем лучшие результаты среди версий v1–v4, чтобы минимизировать влияние шаблонов подсказок.
Для этого eval.py автоматически извлекает лучшие результаты:
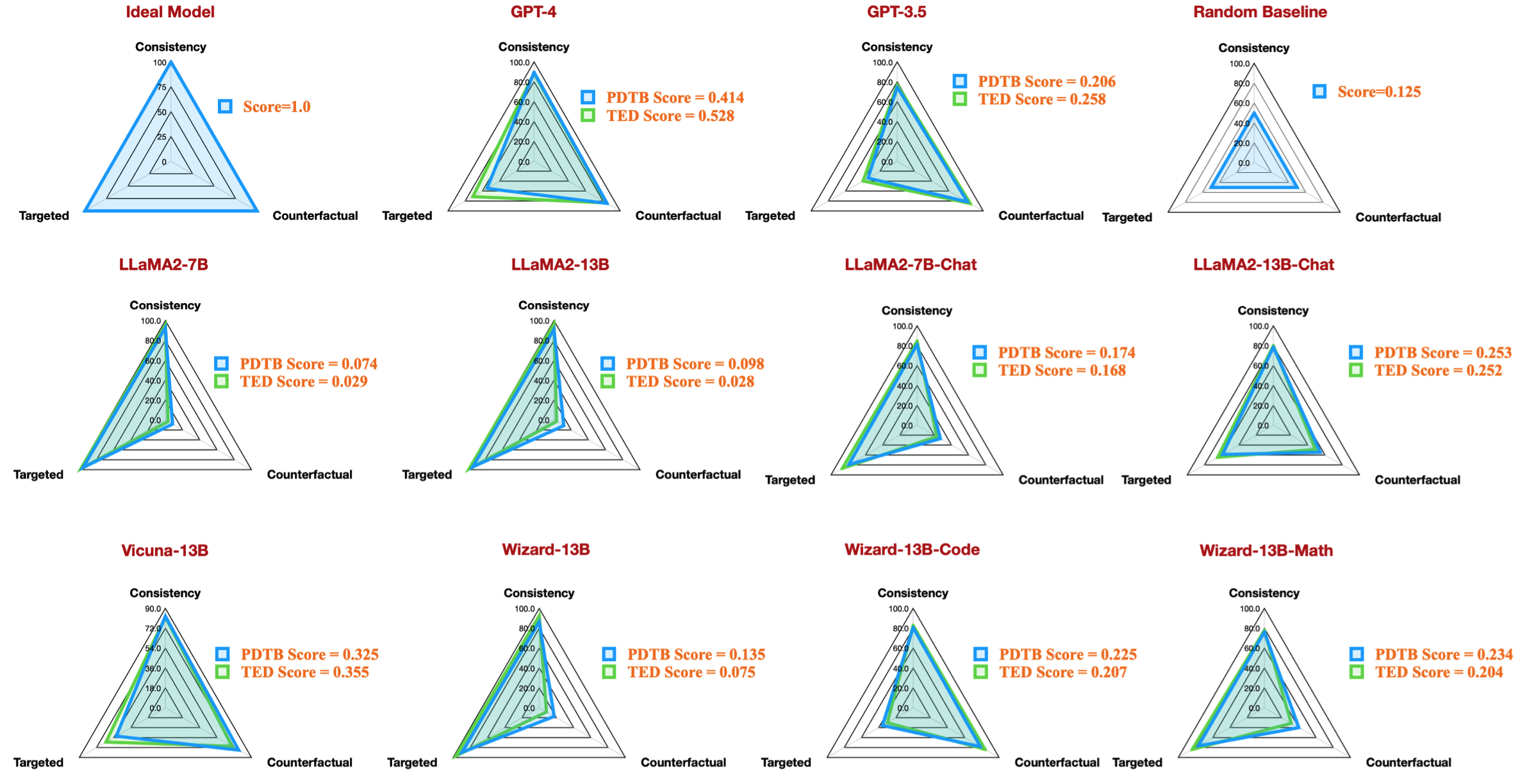
| код задачи | название модели | версия | парафраз | особенность | Общий | Целевой | контрафактный | Последовательность | Сравнение.Уступка | Сравнение.Контраст | Непредвиденное обстоятельство.Причина | Непредвиденные обстоятельства.Результат | Расширение.Соединение | Расширение.Эквивалентность | Расширение. Создание экземпляра | Расширение.Уровень детализации | Расширение.Замена | Временной.Асинхронный | Временной.Синхронный |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dataset_pdtb_prompt_v4_7b | 7б | v4 | 0,074 | 0,956 | 0,084 | 0,929 | 0,03 | 0,083 | 0,095 | 0,095 | 0,077 | 0,054 | 0,086 | 0,068 | 0,155 | 0,036 | 0,047 | ||
| dataset_pdtb_prompt_v1_7bchat | 7бчат | v1 | 0,174 | 0,794 | 0,271 | 0,811 | 0,231 | 0,435 | 0,132 | 0,173 | 0,214 | 0,105 | 0,121 | 0,15 | 0,199 | 0,107 | 0,04 | ||
| dataset_pdtb_prompt_v2_13b | 13б | v2 | 0,097 | 0,945 | 0,112 | 0,912 | 0,037 | 0,099 | 0,081 | 0,094 | 0,126 | 0,101 | 0,113 | 0,107 | 0,077 | 0,083 | 0,093 | ||
| dataset_pdtb_prompt_v1_13bchat | 13бчат | v1 | 0,253 | 0,592 | 0,545 | 0,785 | 0,195 | 0,485 | 0,129 | 0,173 | 0,289 | 0,155 | 0,326 | 0,373 | 0,285 | 0,194 | 0,028 | ||
| dataset_pdtb_prompt_v2_vicuna-13b | викунья-13b | v2 | 0,325 | 0,512 | 0,766 | 0,829 | 0,087 | 0,515 | 0,201 | 0,352 | 0,369 | 0,0 | 0,334 | 0,46 | 0,199 | 0,511 | 0,074 |
Например, в этой таблице показан лучший результат для наборов данных PDTB для доступных моделей с открытым исходным кодом, которые воспроизводят данные радара из нашей статьи:
Мы также предоставляем инструкции по оценке дискуссионных вопросов о языковых особенностях:
--feature в качестве conn и context в question_generation.py (шаг 1) и повторно запустите все эксперименты.question_generation_history.py . Этот скрипт будет извлекать ответы из сохраненных результатов контроля качества и генерировать новые вопросы.Для большинства специалистов по НЛП, вероятно, вы сможете запустить наш код в существующих виртуальных (conda) средах.
Когда мы проводили наши эксперименты, версии пакета были следующими:
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
Однако мы заметили, что для новых моделей требуются обновленные версии пакета:
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
Если наша работа покажется вам интересной, мы приглашаем вас попробовать наш набор данных/кодовую базу.
Пожалуйста, укажите наше исследование, если вы использовали наш набор данных/кодовую базу:
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
Если у вас есть вопросы или сообщения об ошибках, сообщите о проблеме или свяжитесь с нами напрямую по электронной почте:
Адрес электронной почты: ?@?
где ?️= yisong , ?= comp.nus.edu.sg
CC 4.0


