Patron
1.0.0
Этот репозиторий содержит код для нашей статьи ACL 2023 «Выбор данных холодного запуска для точной настройки языковой модели с несколькими выстрелами: подход к распространению неопределенности на основе подсказок».
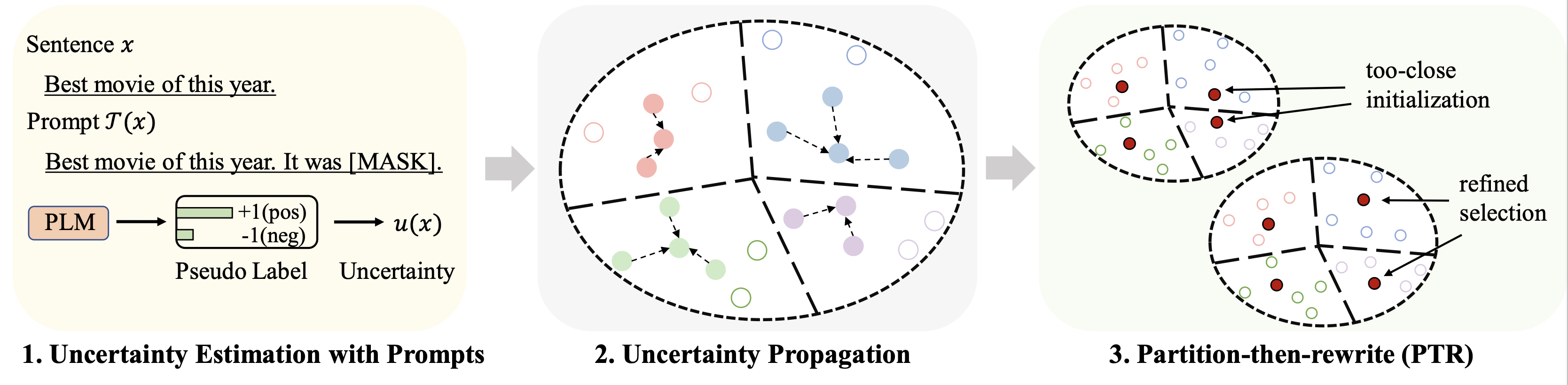
Результаты по различным наборам данных (с использованием 128 меток в качестве бюджета) для точной настройки суммируются следующим образом:
| Метод | ИМДБ | Визг-полный | АГНовости | Yahoo! | ДБПедия | ТРЕК | Иметь в виду |
|---|---|---|---|---|---|---|---|
| Полный контроль (база RoBERTa) | 94,1 | 66,4 | 94,0 | 77,6 | 99,3 | 97,2 | 88,1 |
| Случайная выборка | 86,6 | 47,7 | 84,5 | 60,2 | 95,0 | 85,6 | 76,7 |
| Лучший базовый уровень (Чанг и др., 2021 г.) | 88,5 | 46,4 | 85,6 | 61,3 | 96,5 | 87,7 | 77,6 |
| Patron (наш) | 89,6 | 51,2 | 87,0 | 65,1 | 97,0 | 91,1 | 80,2 |
Для оперативного обучения мы используем тот же конвейер, что и LM-BFF. Результат со 128 метками показан следующим образом.
| Метод | ИМДБ | Визг-полный | АГНовости | Yahoo! | ДБПедия | ТРЕК | Иметь в виду |
|---|---|---|---|---|---|---|---|
| Полный контроль (база RoBERTa) | 94,1 | 66,4 | 94,0 | 77,6 | 99,3 | 97,2 | 88,1 |
| Случайная выборка | 87,7 | 51,3 | 84,9 | 64,7 | 96,0 | 85,0 | 78,2 |
| Лучший базовый уровень (Юань и др., 2020 г.) | 88,9 | 51,7 | 87,5 | 65,9 | 96,8 | 86,5 | 79,5 |
| Patron (наш) | 89,3 | 55,6 | 87,8 | 67,6 | 97,4 | 88,9 | 81,1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
Для основных экспериментов мы используем следующие четыре набора данных.
| Набор данных | Задача | Количество классов | Количество немаркированных данных/тестовых данных |
|---|---|---|---|
| ИМДБ | Настроение | 2 | 25 тыс./25 тыс. |
| Визг-полный | Настроение | 5 | 39 тыс./10 тыс. |
| Новости АГ | Тема новостей | 4 | 119 тыс./7,6 тыс. |
| Yahoo! Ответы | Тема контроля качества | 5 | 180 тыс./30,1 тыс. |
| ДБПедия | Тема онтологии | 14 | 280 тыс./70 тыс. |
| ТРЕК | Тема вопроса | 6 | 5 тыс./0,5 тыс. |
Обработанные данные можно найти по этой ссылке. Папка для размещения этих наборов данных будет описана в следующих частях.
Выполните следующие команды
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
Мы предоставляем псевдопрогноз , полученный с помощью подсказок по приведенной выше ссылке для наборов данных. Пожалуйста, обратитесь к оригинальным документам для получения подробной информации.
Выполните следующие команды (пример в наборе данных AG News)
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
Некоторые важные гиперпараметры:
rho : параметр, используемый для распространения неопределенности в уравнении. 6 из бумагиbeta : регуляризация расстояния в уравнении. 8 из бумагиgamma : вес члена регуляризации в уравнении. 10 из бумаги Подробные инструкции см. в папке finetune .
Подробные инструкции см. в папке prompt_learning .
См. эту ссылку как конвейер для создания прогнозов на основе подсказок. Обратите внимание, что вам необходимо настроить вербализаторы и шаблоны подсказок.
Чтобы создать вложения документа, вы можете выполнить приведенные выше команды с помощью SimCSE.
После создания индекса для выбранных данных вы можете использовать конвейеры в разделах Running Fine-tuning Experiments и Running Prompt-based Learning Experiments для краткосрочных экспериментов по точной настройке и обучению на основе подсказок.
Пожалуйста, процитируйте следующую статью, если вы найдете этот репозиторий полезным для вашего исследования. Заранее спасибо!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
Хотим поблагодарить авторов из репозитория SimCSE и OpenPrompt за хорошо организованный код.


