JustJoking.ai
1.0.0
В этом проекте я обучил модель-трансформер генерировать короткие шутки. Затем, с небольшой модификацией метода вывода, я смог использовать ту же модель, так что, учитывая начальную строку в качестве входных данных, модель пытается завершить ее юмористическим способом.
Есть два ноутбука, которые выполняют одну и ту же задачу.
Результат генерации шутки 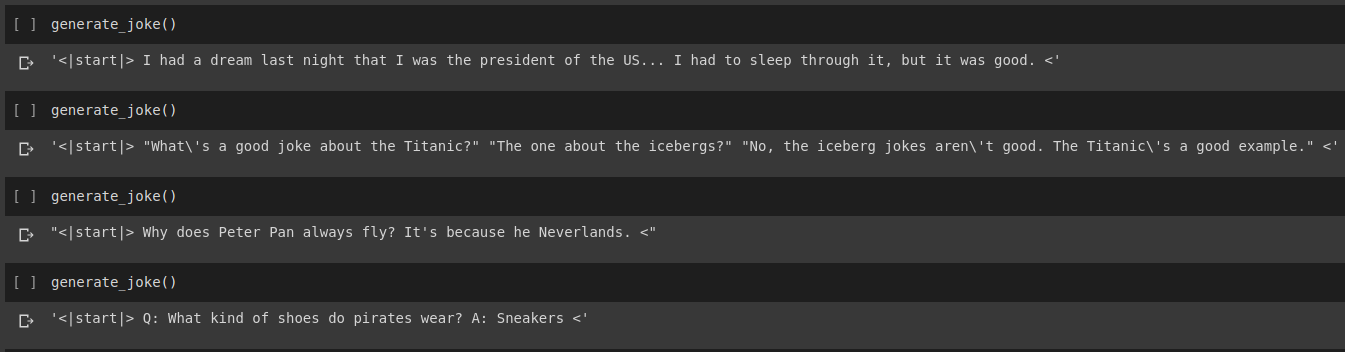
Результат завершения предложения 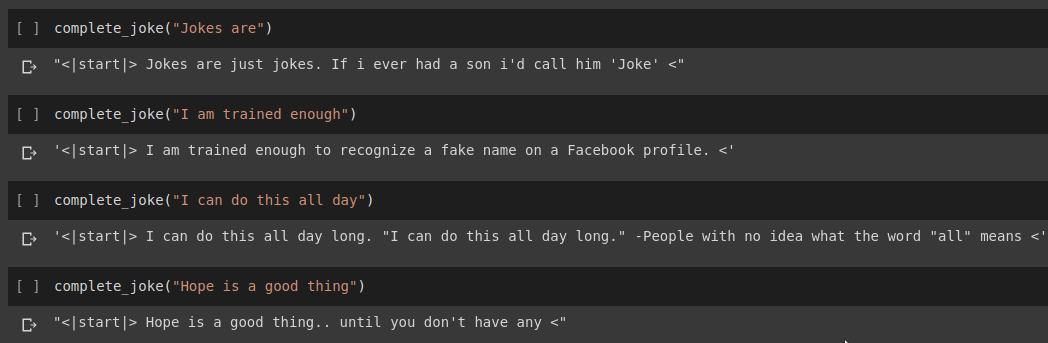
Результаты 
Для нашей задачи мы будем использовать набор данных, предоставленный на Kaggle. Это CSV-файл, содержащий более 200 000 коротких шуток, удаленных с Reddit.
Примечание. Поскольку набор данных просто взят из различных субреддитов, большое количество шуток в наборе данных являются весьма расистскими и сексистскими. Поскольку любой ИИ предполагает, что данные обучения являются единственным источником знаний, следует ожидать, что иногда наша модель будет генерировать подобные шутки.
После того как мы токенизировали нашу строку шутки, мы добавляем start_token и end_token в конце токенизированного списка. Кроме того, поскольку наша строка шутки может иметь разную длину, мы также применяем дополнение ко всем строкам до указанной max_length , чтобы все тензоры в наших пакетах имели одинаковую форму.
Код для этого можно найти в блокноте Joke Generation.ipynb . При этом мы импортируем модель GPT2Tokenizer и TFGPT2LMHead из библиотеки HuggingFace. Код написан на Tensorflow2. В блокноте в подходящих местах имеются комментарии с пояснениями к коду. Кроме того, документация HuggingFace предоставляет хорошую документацию о том, каковы входные параметры и возвращаемое значение модели. Реализацию на основе PyTorch см. в репозитории Humour.ai Танула Сингха.
Код для этого можно найти в блокноте Joke_Completion_Pure_TF2_Implementation.ipynb . Продвигая проект еще дальше для более глубокого понимания того, как все работает, я попытался создать преобразователь без внешней библиотеки. Я сослался на руководство по трансформерам, предоставленное Tensorflow, и поместил некоторые объяснения, упомянутые в их руководстве, в свой блокнот с дополнительными пояснениями, чтобы было легко понять, что происходит.
Сначала я создал токенизатор для нашего набора данных и с его помощью токенизировал строки. Затем построил слой для Positional Encodings и MultiHeadAttention . Кроме того, я использовал Lambda layer для создания подходящих масок для наших данных.
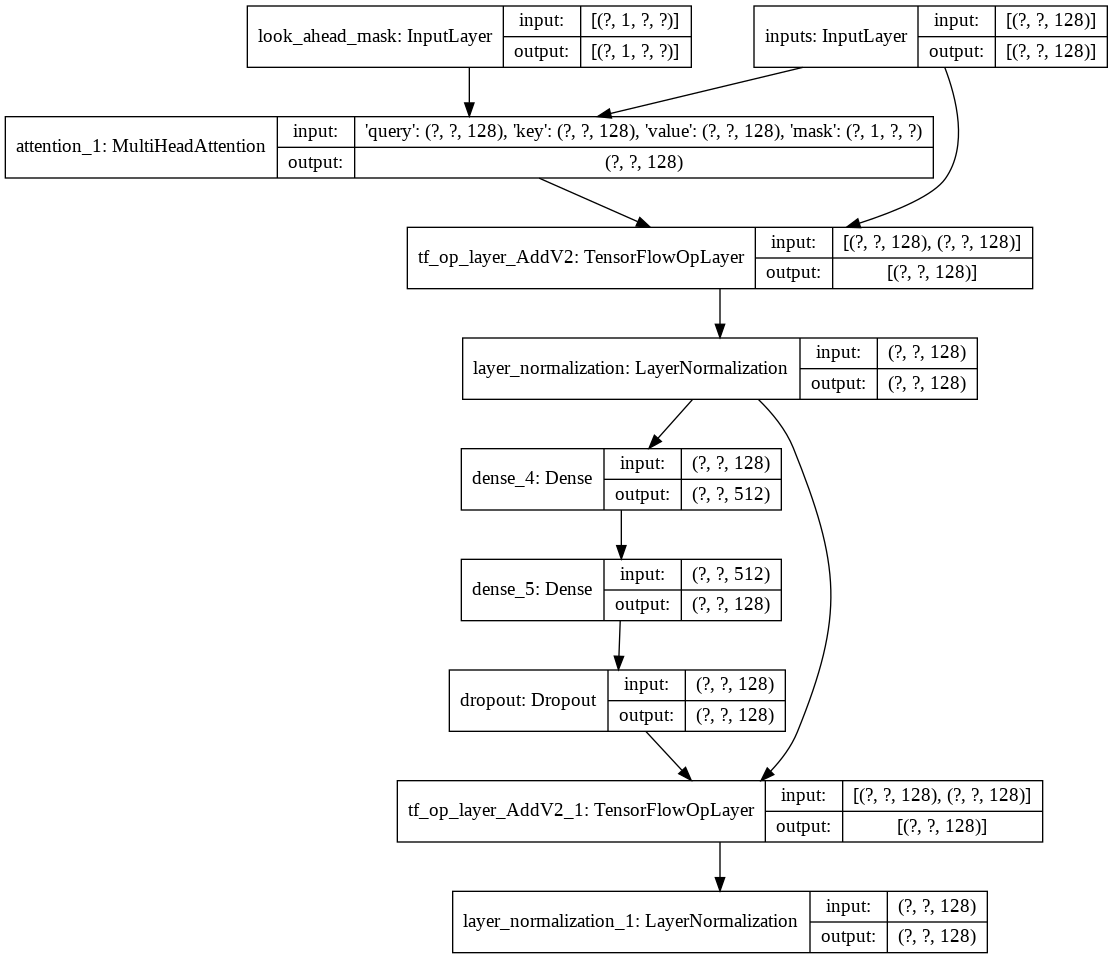
Затем я создал один decoder layer для нашего декодера. Ниже представлена архитектура одного уровня декодера.
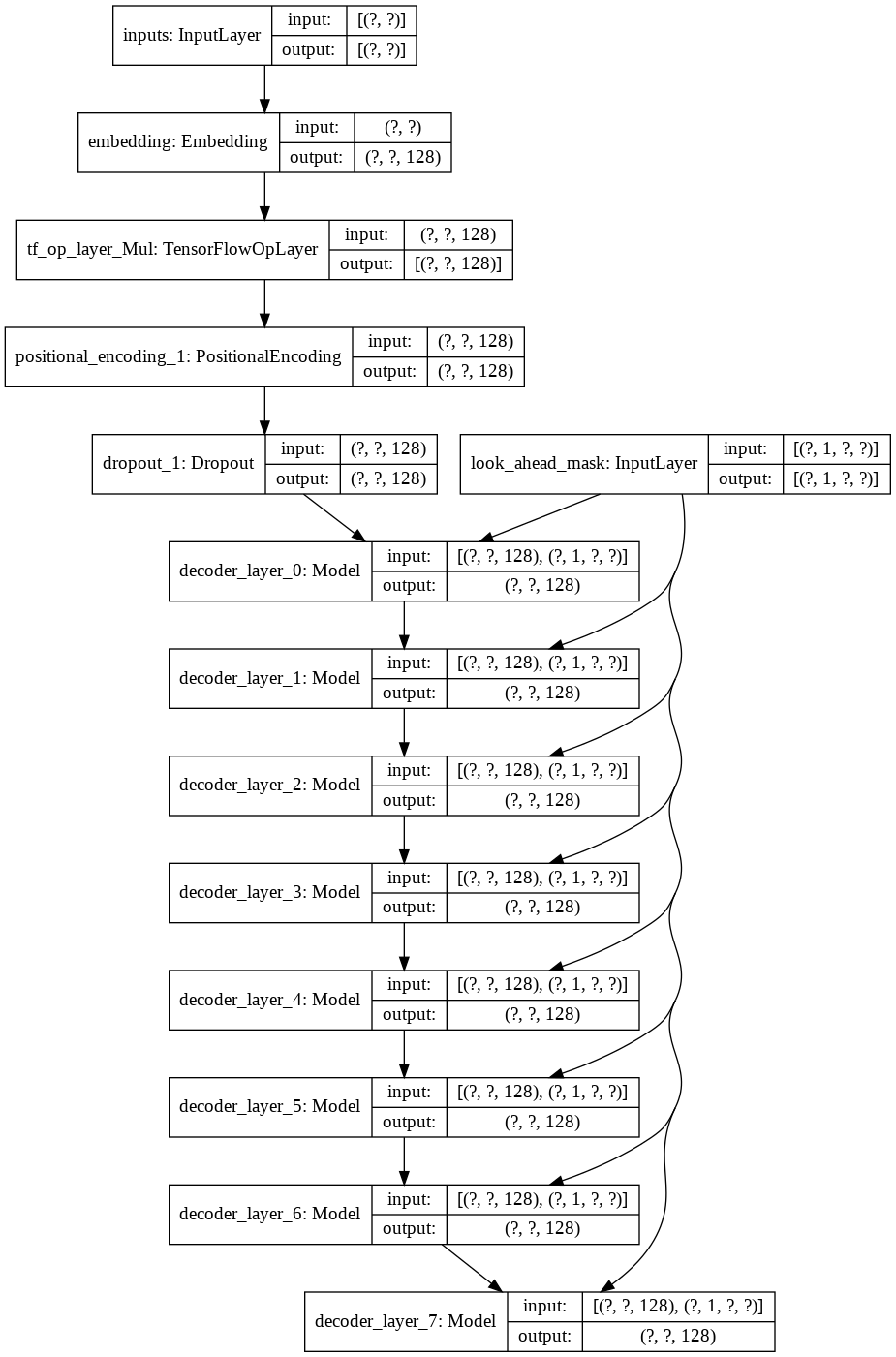
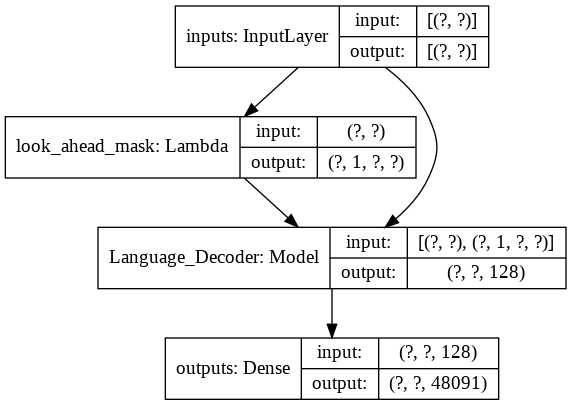
Для окончательной модели transformer он принимает входные токены, пропускает их через лямбда-слой, чтобы получить маску, и передает маску и токены нашему языковому декодеру, выходные данные которого затем передаются через плотный слой. Ниже представлена архитектура нашей окончательной модели.