CTCWordBeamSearch
1.0.0
Декодер коннекционистской временной классификации (CTC) со словарем и языковой моделью (LM).
pip install .tests/ и выполните pytest чтобы проверить, сработала ли установка. В следующем игрушечном примере показано, как использовать поиск по лучу слов. Гипотетическая модель (например, модель распознавания текста) способна распознавать 3 разных символа: «a», «b» и « » (пробелы). Слова в этом игрушечном примере могут содержать символы «a» и «b» (но не «», который является разделителем слов). Языковая модель обучается на текстовом корпусе, который содержит только два слова: «а» и «ба».
В этом фрагменте кода создается экземпляр поиска по лучу слов и декодируется массив numpy в форме TxBx(C+1):
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )Декодер возвращает список с декодированной строкой метки для каждого элемента пакета. Чтобы наконец получить строки символов, сопоставьте каждую метку с соответствующим символом:
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )Примеры:
tests/test_word_beam_search.py Параметры конструктора класса WordBeamSearch :
0<len(wordChars)<len(chars) . Если необходимо обнаружить только отдельные слова, разделительный символ не нужен, поэтому два параметра также могут быть равны: 0<len(wordChars)<=len(chars) Входные данные для метода WordBeamSearch.compute :
Поиск луча слов — это алгоритм декодирования CTC. Он используется для задач распознавания последовательностей, таких как распознавание рукописного текста или автоматическое распознавание речи.
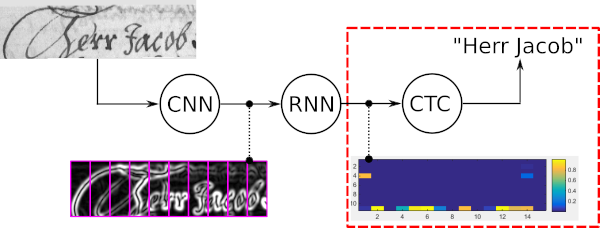
Четыре основных свойства поиска по лучу слов:
В следующем примере показан типичный вариант использования поиска по лучу слов, а также результаты, полученные пятью различными декодерами. Лучшее декодирование пути и поиск ванильного луча дают неверные слова, поскольку эти декодеры используют только зашумленный выходной сигнал оптической модели. Расширение поиска ванильного луча с помощью LM на уровне символов улучшает результат, допуская только вероятные последовательности символов. При передаче токенов используется словарь и LM на уровне слов, поэтому все слова обрабатываются правильно. Однако он не может распознавать произвольные строки символов, такие как числа. Поиск по лучу слов способен распознавать слова с помощью словаря, а также правильно идентифицировать символы, не являющиеся словами.

Дополнительная информация:
extras/prototype/extras/tf/ Пожалуйста, цитируйте следующую статью, если вы используете поиск по лучу слов в своей исследовательской работе.
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


