LM SupCon
1.0.0
В этом репозитории рассматривается реализация следующего документа: «Контрастное обучение для быстро изучающих язык с небольшим количеством попыток», авторы Ижэнь Цзянь, Чонгян Гао и Соруш Восуги, принятые в NAACL 2022.
Если вы найдете этот репозиторий полезным для вашего исследования, рассмотрите возможность цитирования статьи.
@inproceedings { jian-etal-2022-contrastive ,
title = " Contrastive Learning for Prompt-based Few-shot Language Learners " ,
author = " Jian, Yiren and
Gao, Chongyang and
Vosoughi, Soroush " ,
booktitle = " Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies " ,
month = jul,
year = " 2022 " ,
address = " Seattle, United States " ,
publisher = " Association for Computational Linguistics " ,
url = " https://aclanthology.org/2022.naacl-main.408 " ,
pages = " 5577--5587 " ,
abstract = "The impressive performance of GPT-3 using natural language prompts and in-context learning has inspired work on better fine-tuning of moderately-sized models under this paradigm. Following this line of work, we present a contrastive learning framework that clusters inputs from the same class for better generality of models trained with only limited examples. Specifically, we propose a supervised contrastive framework that clusters inputs from the same class under different augmented {``}views{''} and repel the ones from different classes. We create different {``}views{''} of an example by appending it with different language prompts and contextual demonstrations. Combining a contrastive loss with the standard masked language modeling (MLM) loss in prompt-based few-shot learners, the experimental results show that our method can improve over the state-of-the-art methods in a diverse set of 15 language tasks. Our framework makes minimal assumptions on the task or the base model, and can be applied to many recent methods with little modification.",
} Наш код во многом заимствован у LM-BFF и SupCon ( /src/losses.py ).
Этот репозиторий был протестирован с Ubuntu 18.04.5 LTS, Python 3.7, PyTorch 1.6.0 и CUDA 10.1. Вам понадобится графический процессор емкостью 48 ГБ для экспериментов с базой RoBERTa и 4 графических процессора по 48 ГБ для RoBERTa-large. Мы проводим эксперименты на Nvidia RTX-A6000 и RTX-8000, но Nvidia A100 с 40 ГБ тоже должна работать.
Мы используем предварительно обработанные наборы данных (SST-2, SST-5, MR, CR, MPQA, Subj, TREC, CoLA, MNLI, SNLI, QNLI, RTE, MRPC, QQP) из LM-BFF. LM-BFF предлагает полезные сценарии для загрузки и подготовки набора данных. Просто запустите команды ниже.
cd data
bash download_dataset.shЗатем используйте следующую команду для создания наборов данных из 16 снимков, которые мы использовали в исследовании.
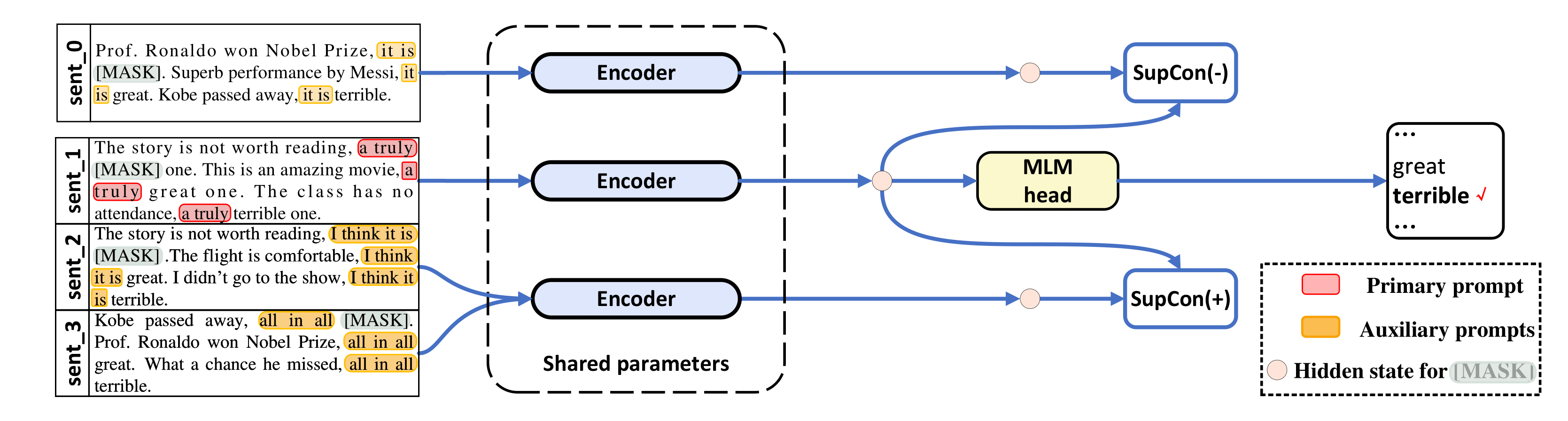
python tools/generate_k_shot_data.py Основные приглашения (шаблоны), используемые для задач, предварительно определены в run_experiments.sh . Вспомогательные шаблоны, используемые при создании нескольких представлений входных данных для контрастного обучения, можно найти в /auto_template/$TASK .
Предполагая, что в вашей системе есть один графический процессор, мы покажем пример выполнения нашей тонкой настройки на SST-5 (случайные шаблоны и случайные демонстрации для «расширенного просмотра» входных данных).
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 40 # ### batch size
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-base
bash run_experiment.sh
done
done
done
done
rm -rf result/ Наша структура также применима к методу на основе подсказок без демонстраций, т. е. TYPE=prompt (в этом случае мы только случайным образом выбираем шаблоны для создания «дополненных представлений»). Результаты сохраняются в log .
Для использования RoBERTa-large в качестве базовой модели требуется 4 графических процессора, каждый с 48 ГБ памяти. Сначала вам нужно отредактировать строку 20 в src/models.py чтобы она была def __init__(self, hidden_size=1024) .
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 10 # ### batch size for each GPU, total batch size is then 40
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-large
bash run_experiment.sh
done
done
done
done
rm -rf result/ python tools/gather_result.py --condition "{'tag': 'exp', 'task_name': 'sst-5', 'few_shot_type': 'prompt-demo'}"
Он соберет результаты из log и вычислит среднее и стандартное отклонение для этих 5 разделений поездного теста.
По всем вопросам обращайтесь к авторам.
Спасибо LM-BFF и SupCon за предварительные реализации.


