KoGPT2 FineTuning
1.0.0
Мы использовали KoGPT2, который был предварительно обучен SKT-AI примерно на 20 ГБ корейских данных. Во-первых, для написания текстов мы тщательно настраивали данные о текстах, романах, статьях и т. д., права на которые истекли, придавая каждому из данных разный вес. Вы также можете узнать жанры и просмотреть результаты изучения текстов для каждого музыкального жанра.
Кроме того, Colab связал Google Drive и Dropbbox для более удобного обучения. После перемещения изученных промежуточных результатов с Google Диска в Dropbbox удалите результаты с Google Диска. Код, связанный с этим
Если с KoGPT2-FineTuning сложно работать с измененным кодом версии 2, которая получает наборы данных формата CSV для каждого музыкального жанра, используйте версию 1.1.
Ниже вы можете проверить результаты изучения различных корейских текстов. Мы будем работать и над другими проектами.

| масса | Жанр | тексты песен |
|---|---|---|
| 1100,0 | баллада | 'Ты знаешь, что я чувствую.nnnЯ просто смотрю на тебя, стоящего безучастно, как фараонnnnУ меня нет другого выбора, кроме как сдаться...' |
| ... |
python main.py --epoch=200 --data_file_path=./dataset/lyrics_dataset.csv --save_path=./checkpoint/ --load_path=./checkpoint/genre/KoGPT2_checkpoint_296000.tar --batch_size=1
parser . add_argument ( '--epoch' , type = int , default = 200 ,
help = "epoch 를 통해서 학습 범위를 조절합니다." )
parser . add_argument ( '--save_path' , type = str , default = './checkpoint/' ,
help = "학습 결과를 저장하는 경로입니다." )
parser . add_argument ( '--load_path' , type = str , default = './checkpoint/Alls/KoGPT2_checkpoint_296000.tar' ,
help = "학습된 결과를 불러오는 경로입니다." )
parser . add_argument ( '--samples' , type = str , default = "samples/" ,
help = "생성 결과를 저장할 경로입니다." )
parser . add_argument ( '--data_file_path' , type = str , default = 'dataset/lyrics_dataset.txt' ,
help = "학습할 데이터를 불러오는 경로입니다." )
parser . add_argument ( '--batch_size' , type = int , default = 8 ,
help = "batch_size 를 지정합니다." )Вы можете запустить тонкую настройку кода с помощью Colab.
function ClickConnect ( ) {
// 백엔드를 할당하지 못했습니다.
// GPU이(가) 있는 백엔드를 사용할 수 없습니다. 가속기가 없는 런타임을 사용하시겠습니까?
// 취소 버튼을 찾아서 클릭
var buttons = document . querySelectorAll ( "colab-dialog.yes-no-dialog paper-button#cancel" ) ;
buttons . forEach ( function ( btn ) {
btn . click ( ) ;
} ) ;
console . log ( "1분 마다 다시 연결" ) ;
document . querySelector ( "#top-toolbar > colab-connect-button" ) . click ( ) ;
}
setInterval ( ClickConnect , 1000 * 60 ) ; function CleanCurrentOutput ( ) {
var btn = document . querySelector ( ".output-icon.clear_outputs_enabled.output-icon-selected[title$='현재 실행 중...'] iron-icon[command=clear-focused-or-selected-outputs]" ) ;
if ( btn ) {
console . log ( "10분 마다 출력 지우기" ) ;
btn . click ( ) ;
}
}
setInterval ( CleanCurrentOutput , 1000 * 60 * 10 ) ; nvidia-smi.exe
python generator.py --temperature=1.0 --text_size=1000 --tmp_sent=""
python generator.py --temperature=5.0 --text_size=500 --tmp_sent=""
parser . add_argument ( '--temperature' , type = float , default = 0.7 ,
help = "temperature 를 통해서 글의 창의성을 조절합니다." )
parser . add_argument ( '--top_p' , type = float , default = 0.9 ,
help = "top_p 를 통해서 글의 표현 범위를 조절합니다." )
parser . add_argument ( '--top_k' , type = int , default = 40 ,
help = "top_k 를 통해서 글의 표현 범위를 조절합니다." )
parser . add_argument ( '--text_size' , type = int , default = 250 ,
help = "결과물의 길이를 조정합니다." )
parser . add_argument ( '--loops' , type = int , default = - 1 ,
help = "글을 몇 번 반복할지 지정합니다. -1은 무한반복입니다." )
parser . add_argument ( '--tmp_sent' , type = str , default = "사랑" ,
help = "글의 시작 문장입니다." )
parser . add_argument ( '--load_path' , type = str , default = "./checkpoint/Alls/KoGPT2_checkpoint_296000.tar" ,
help = "학습된 결과물을 저장하는 경로입니다." )Вы можете запустить генератор с помощью Colab.

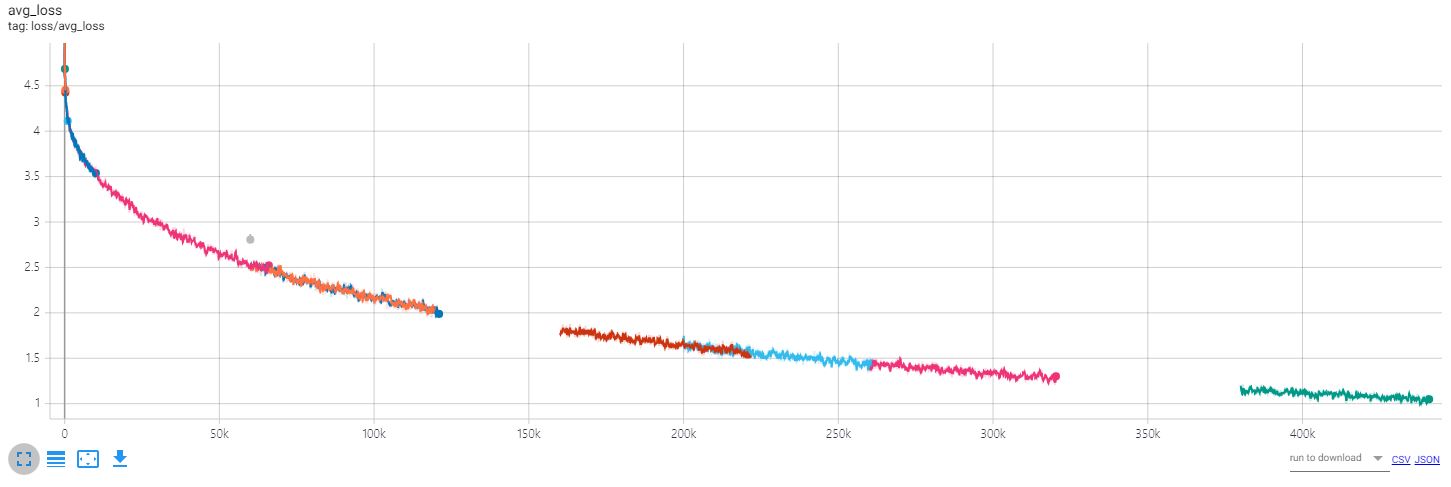
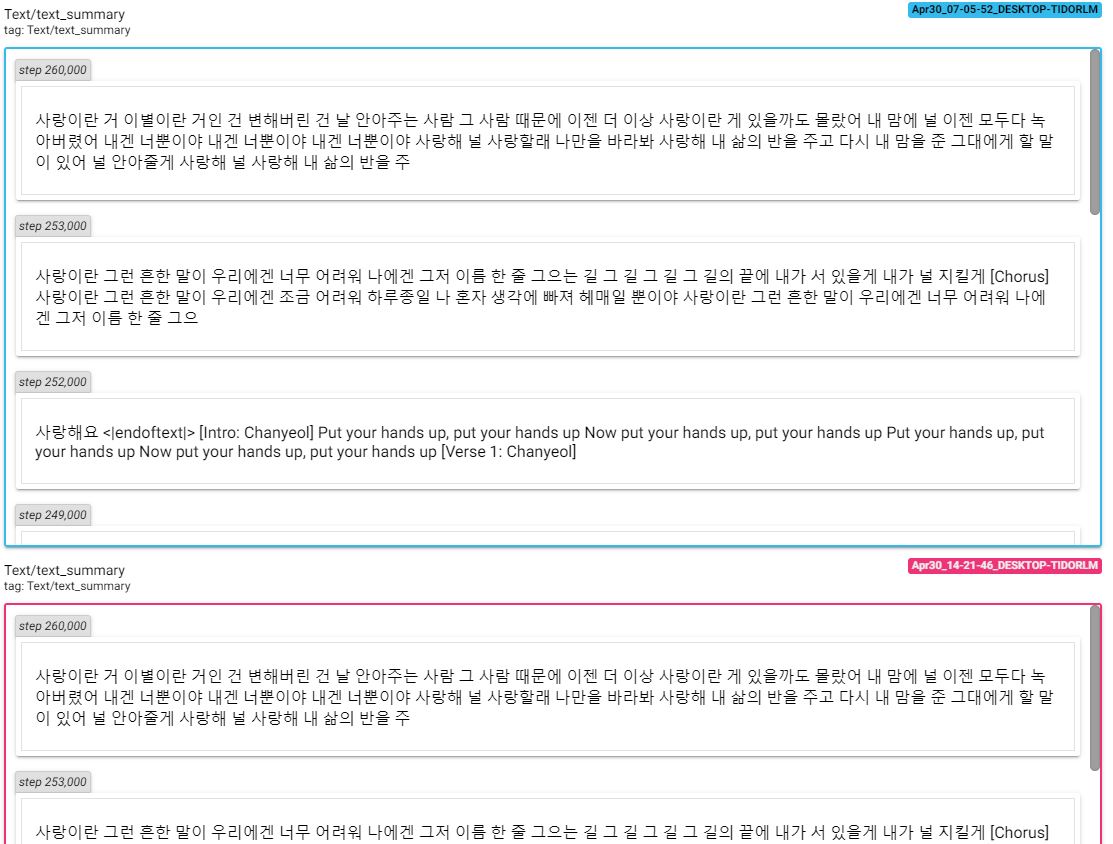
Чтобы проверить изменения, произошедшие в результате обучения, откройте тензорную панель и проверьте потери и текст.
tensorboard --logdir=runs
@misc{KoGPT2-FineTuning,
author = {gyung},
title = {KoGPT2-FineTuning},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gyunggyung/KoGPT2-FineTuning}},
}
Подробные результаты можно найти в образцах. Более подробную информацию об обучении можно найти в соответствующих постах.
https://github.com/openai/gpt-2
https://github.com/nshepperd/gpt-2
https://github.com/SKT-AI/KoGPT2
https://github.com/asyml/texar-pytorch/tree/master/examples/gpt-2
https://github.com/graykode/gpt-2-Pytorch
https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
https://github.com/shbictai/narrativeKoGPT2
https://github.com/ssut/py-hanspell
https://github.com/likejazz/korean-sentence-splitter


