DialogStudio
1.0.0

Бумага, Обнимающее Лицо, Модель, Щебетать
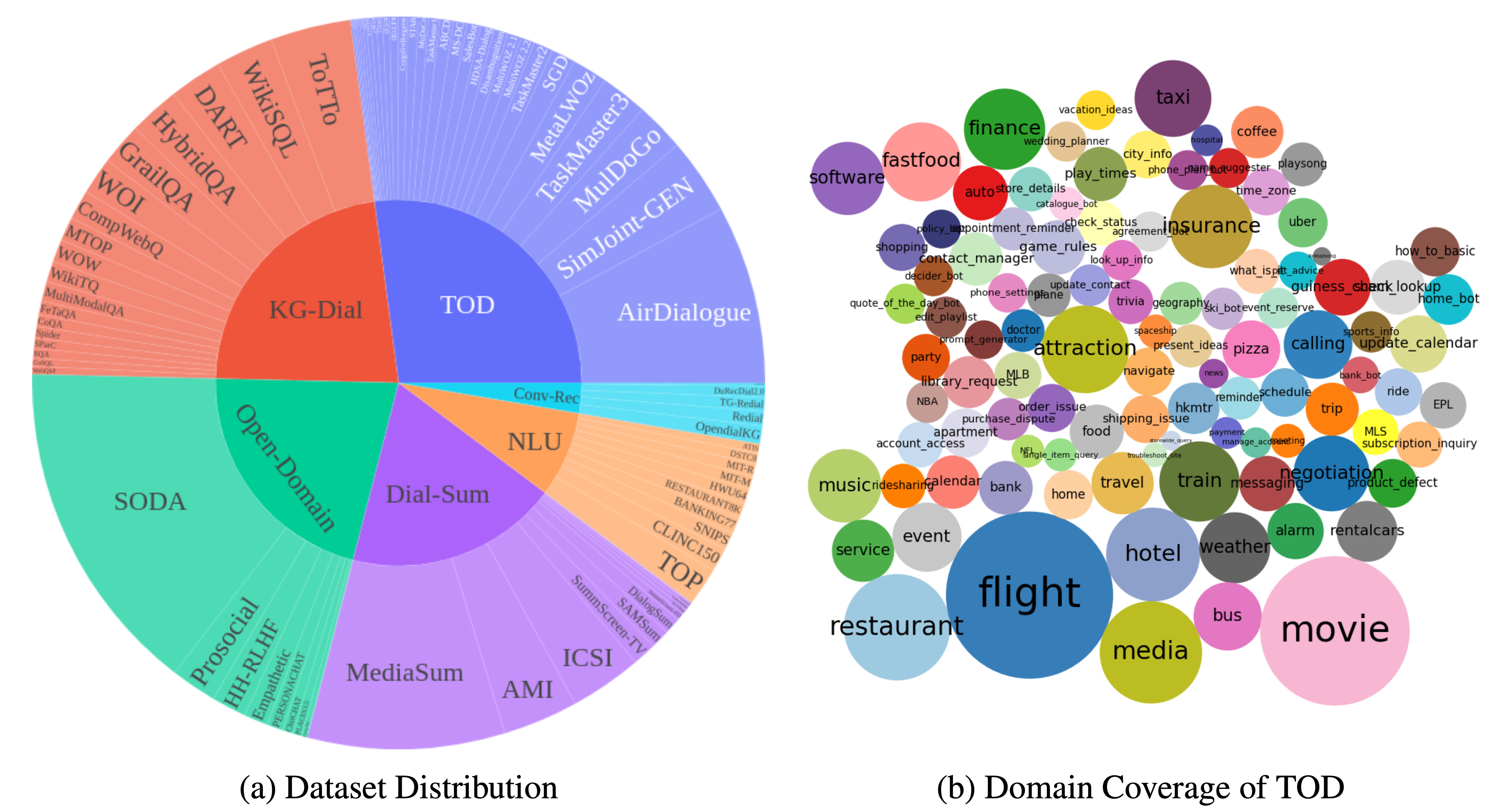
DialogStudio — это большая коллекция и унифицированные наборы данных диалогов. На рисунке ниже представлена сводка общей статистики, связанной с DialogStudio . DialogStudio унифицировал каждый набор данных, сохраняя при этом исходную информацию, и это помогает поддерживать исследования как отдельных наборов данных, так и обучение модели большого языка (LLM). Полный список всех доступных наборов данных находится здесь.
Данные можно загрузить через Huggingface, как описано в разделе «Загрузка данных». Мы также предоставляем примеры для каждого набора данных в этом репозитории. Для получения более подробной информации по категориям обратитесь к отдельным папкам, соответствующим каждой категории в коллекции DialogStudio , например, к набору данных MULTIWOZ2_2 в категории «задачно-ориентированные диалоги».
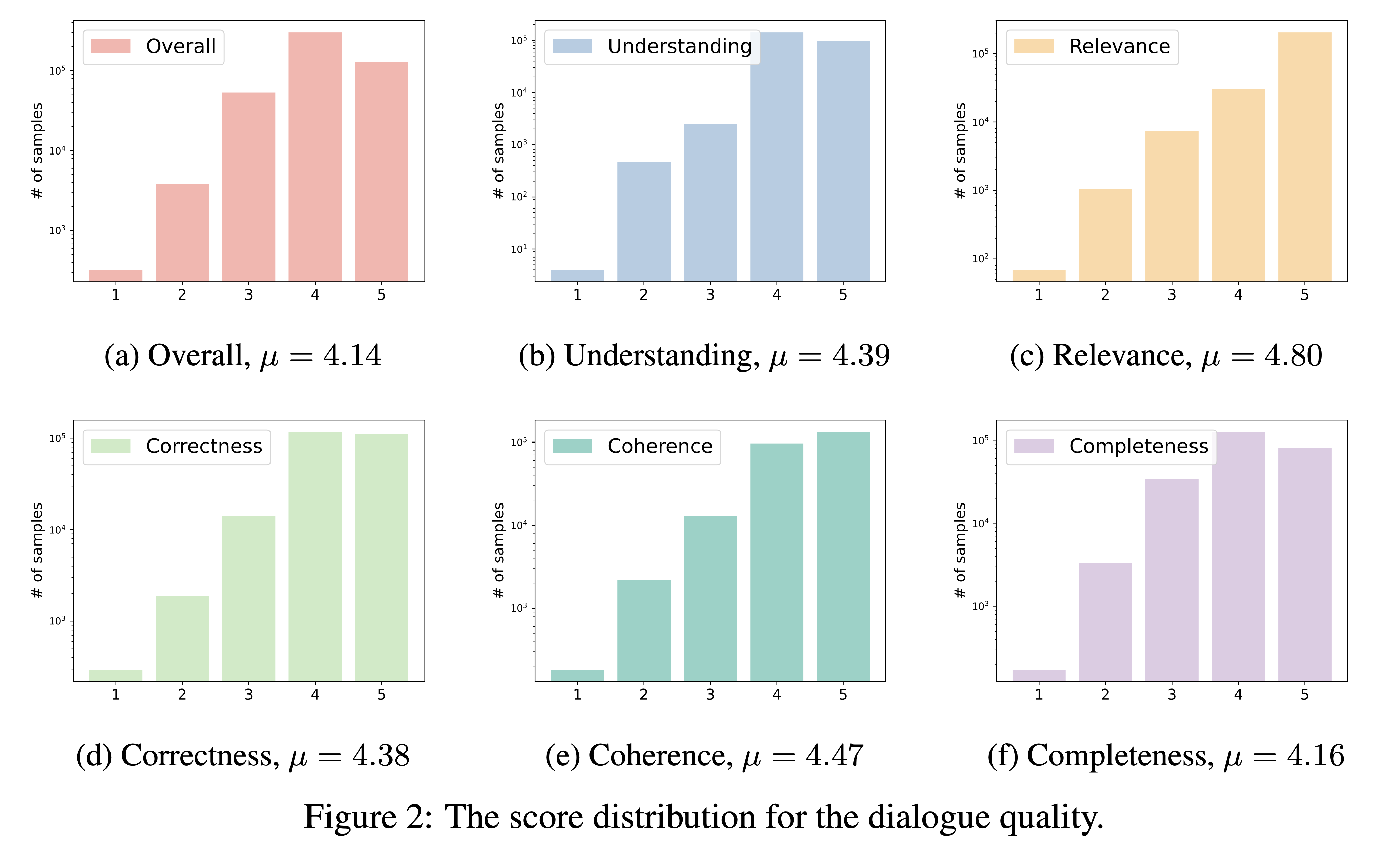
DialogStudio оценивает качество диалога на основе шести важнейших критериев, а именно: понимание, релевантность, корректность, связность, полнота и общее качество. Каждый критерий оценивается по шкале от 1 до 5, причем наивысшие баллы присваиваются исключительным диалогам.
Учитывая огромное количество наборов данных, включенных в DialogStudio , мы использовали gpt-3.5-turbo для оценки 33 различных наборов данных. Доступ к соответствующему сценарию, использованному для этой оценки, можно получить по ссылке.
Результаты нашей оценки качества диалога представлены ниже. Мы намерены опубликовать оценки для индивидуально выбранных диалогов в предстоящий период.
Вы можете загрузить любой набор данных в DialogStudio из концентратора HuggingFace, заявив {dataset_name} , который в точности соответствует имени папки набора данных. Все доступные наборы данных описаны в содержимом набора данных.
Ниже приведен один из примеров загрузки набора данных MULTIWOZ2_2 в категорию диалогов, ориентированных на задачи:
Загрузите набор данных
from datasets import load_dataset
dataset = load_dataset ( 'Salesforce/ DialogStudio ' , 'MULTIWOZ2_2' )Вот структура вывода MultiWOZ 2.2.
DatasetDict ({
train : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 8437
})
validation : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
test : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
})Наборы данных разделены на несколько категорий в этом репозитории GitHub и хабе HuggingFace. Вы можете проверить таблицу набора данных для получения дополнительной информации. И вы можете нажать на каждую папку, чтобы просмотреть несколько примеров:
Мы выпустили версию 1.0 моделей ( DialogStudio -t5-base-v1.0, DialogStudio -t5-large-v1.0, DialogStudio -t5-3b-v1.0), обученных на нескольких выбранных наборах данных DialogStudio . Проверьте каждую карточку модели для получения более подробной информации.
Ниже приведен один из примеров запуска модели на ЦП:
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write 200 words in a single tweet?"
input_ids = tokenizer ( input_text , return_tensors = "pt" ). input_ids
outputs = model . generate ( input_ids , max_new_tokens = 256 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))В отношении лицензирования наш проект имеет следующую структуру:
Подробную информацию о лицензировании см. в конкретных лицензиях, прилагаемых к исходным наборам данных. Важно ознакомиться с этими условиями, поскольку мы не несем ответственности за вопросы лицензирования.
Мы искренне благодарим всех авторов наборов данных, которые внесли свой вклад в область разговорного ИИ. Несмотря на тщательные усилия, в наших цитатах и ссылках могут возникнуть неточности. Если вы заметили какие-либо ошибки или упущения, сообщите о проблеме или отправьте запрос на включение, чтобы помочь нам улучшиться. Спасибо!
Данные и код в этом репозитории в основном разработаны для статьи ниже или взяты из нее. Если вы используете наборы данных из DialogStudio , мы просим вас цитировать как оригинальную работу, так и нашу собственную работу (принята результатами EACL 2024 как длинная статья).
@article{zhang2023 DialogStudio ,
title={ DialogStudio : Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
Мы с энтузиазмом приглашаем сообщество внести свой вклад! Присоединяйтесь к нашей общей миссии по продвижению вперед области диалогового искусственного интеллекта!


