aug pe
1.0.0
? Бумага • Данные (Yelp/OpenReview/PubMed) • Страница проекта
В этом репозитории реализован алгоритм Augmented Private Evolution (Aug-PE), который использует доступ API вывода к большим языковым моделям (LLM) для генерации дифференциально частного (DP) синтетического текста без необходимости обучения модели. Сравниваем тонкую настройку DP-SGD и Aug-PE:

Под
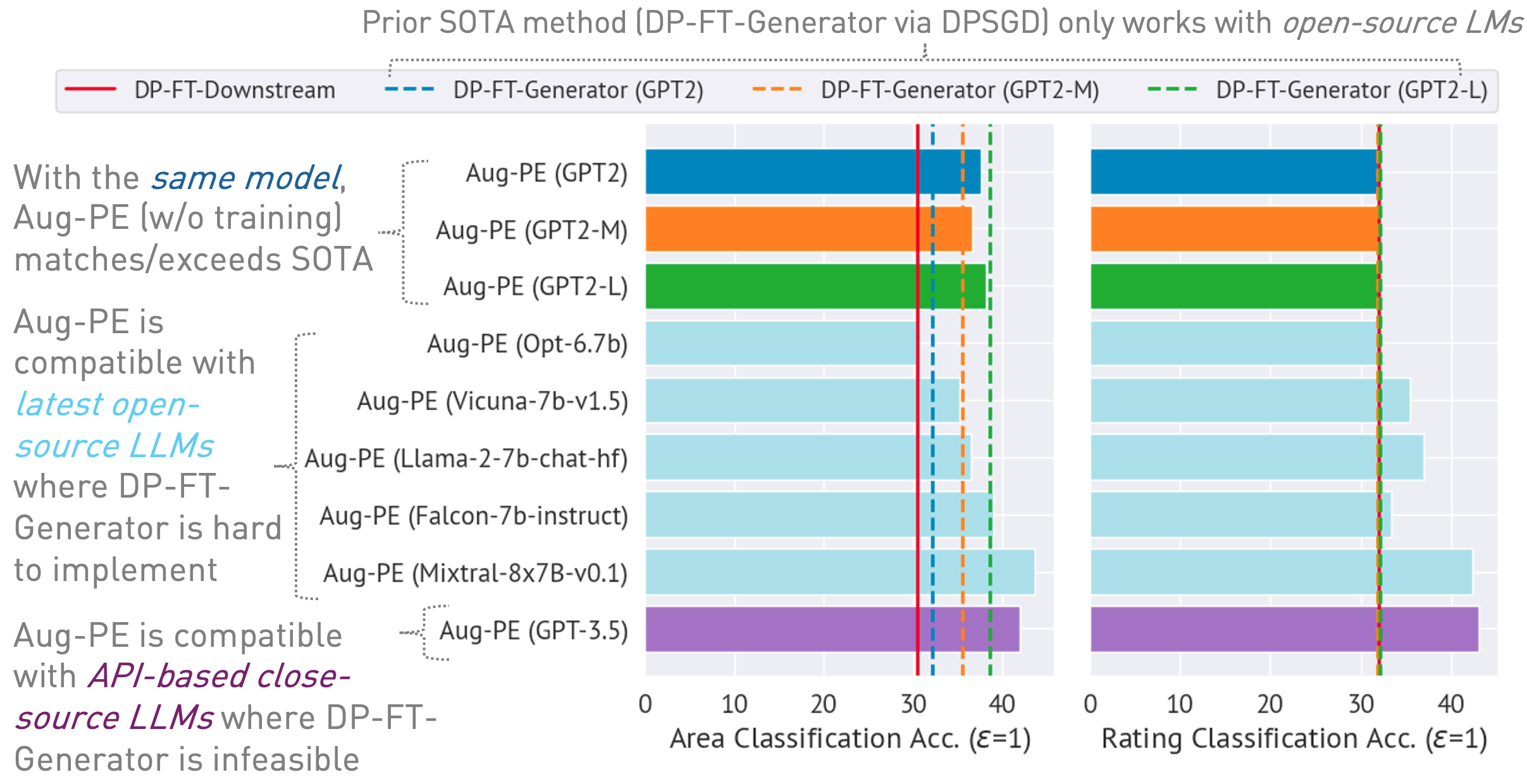
03/13/2024 : Доступна страница проекта, на которой описан алгоритм и его результаты.03/11/2024 : Доступны код и статья ArXiv. conda env create -f environment.yml
conda activate augpe
Наборы данных расположены по адресу data/{dataset} , где dataset — yelp , openreview и pubmed .
Загрузите файлы Yelp train.csv (1,21 ГБ) и PubMed train.csv (117 МБ) по этой ссылке или выполните:
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csvОписание набора данных:
Предварительное вычисление встраивания частных данных (строка 1 в алгоритме Aug-PE):
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp Примечание. Вычисление вложений для OpenReview и PubMed происходит относительно быстро. Однако из-за большого размера набора данных Yelp (1,9 млн обучающих выборок) этот процесс может занять около 40 минут.
Рассчитайте уровень шума DP для вашего набора данных в notebook/dp_budget.ipynb учитывая бюджет конфиденциальности.
Для визуализации с помощью Wandb настройте --wandb_key и --project , указав свой ключ и имя проекта в dpsda/arg_utils.py .
Используйте LLM с открытым исходным кодом от Hugging Face для создания синтетических данных:
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmedНекоторые ключевые гиперпараметры:
noise : шум DP.epoch : мы используем 10 эпох для настройки DP. Для настройки без DP мы используем 20 эпох для Yelp и 10 эпох для других наборов данных.model_type : модель на обнимающем лице, например ["gpt2", "gpt2-medium", "gpt2-large", "meta-llama/Llama-2-7b-chat-hf", "tiiuae/falcon-7b-instruct" , "facebook/opt-6.7b", "lmsys/vicuna-7b-v1.5", «mistralai/Mixtral-8x7B-Instruct-v0.1»].num_seed_samples : количество синтетических образцов.lookahead_degree : количество вариантов оценки встраивания синтетической выборки (строка 5 в алгоритме Aug-PE). По умолчанию — 0 (самовнушение).L : связано с количеством вариантов для создания потенциальных синтетических образцов (строка 18 в алгоритме Aug-PE).feat_ext : встраивание модели в преобразователи предложений HuggingFace.select_syn_mode : выберите синтетические образцы в соответствии с голосами гистограммы или вероятностью. По умолчанию — rank (строка 19 в алгоритме Aug-PE).temperature : температура генерации LLM.Настройте последующую модель с помощью синтетического текста DP и оцените точность модели на реальных тестовых данных:
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance Измерьте расстояние распределения встраивания:
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distanceДля упрощенного процесса, объединяющего все этапы генерации и оценки:
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset Мы используем модель с закрытым исходным кодом через API Azure OpenAI. Установите ключ и конечную точку в apis/azure_api.py
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
} Здесь engine может быть gpt-35-turbo в Azure.
Запустите следующий сценарий, чтобы сгенерировать синтетические данные, оценить их в последующей задаче и вычислить расстояние распределения внедрения между реальными и синтетическими данными:
bash scripts/gpt-3.5-turbo/{dataset}.shМы используем подсказки, связанные с длиной текста, для GPT-3.5, чтобы контролировать длину сгенерированного текста. Здесь мы вводим несколько дополнительных гиперпараметров:
dynamic_len используется для включения механизма динамической длины.word_var_scale : дисперсия гауссова шума, используемая для определения target_word.max_token_word_scale : максимальное количество токенов в слове. Мы устанавливаем max_token для генерации LLM на основе target_word (указанного в приглашении) и max_token_word_scale. Используйте блокнот для расчета разницы в распределении длины текста между реальными и синтетическими данными: notebook/text_lens_distribution.ipynb
Если наша работа окажется для вас полезной, пожалуйста, процитируйте ее следующим образом:
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}Если у вас есть какие-либо вопросы, связанные с кодом или статьей, напишите Чулину по электронной почте ([email protected]) или откройте проблему.


