Проект поисково-дополненной генерации (RAG)
If this project helps you, consider buying me a coffee ☕. Your support helps me keep contributing to the open-source community!
Официальная платформа bRAGAI скоро запустится. Присоединяйтесь к списку ожидания, чтобы стать одним из первых пользователей!
Этот репозиторий содержит всестороннее исследование расширенной генерации данных (RAG) для различных приложений. В каждом блокноте содержится подробное практическое руководство по настройке и экспериментированию с RAG, от начального уровня до продвинутых реализаций, включая многозапросы и пользовательские сборки RAG.
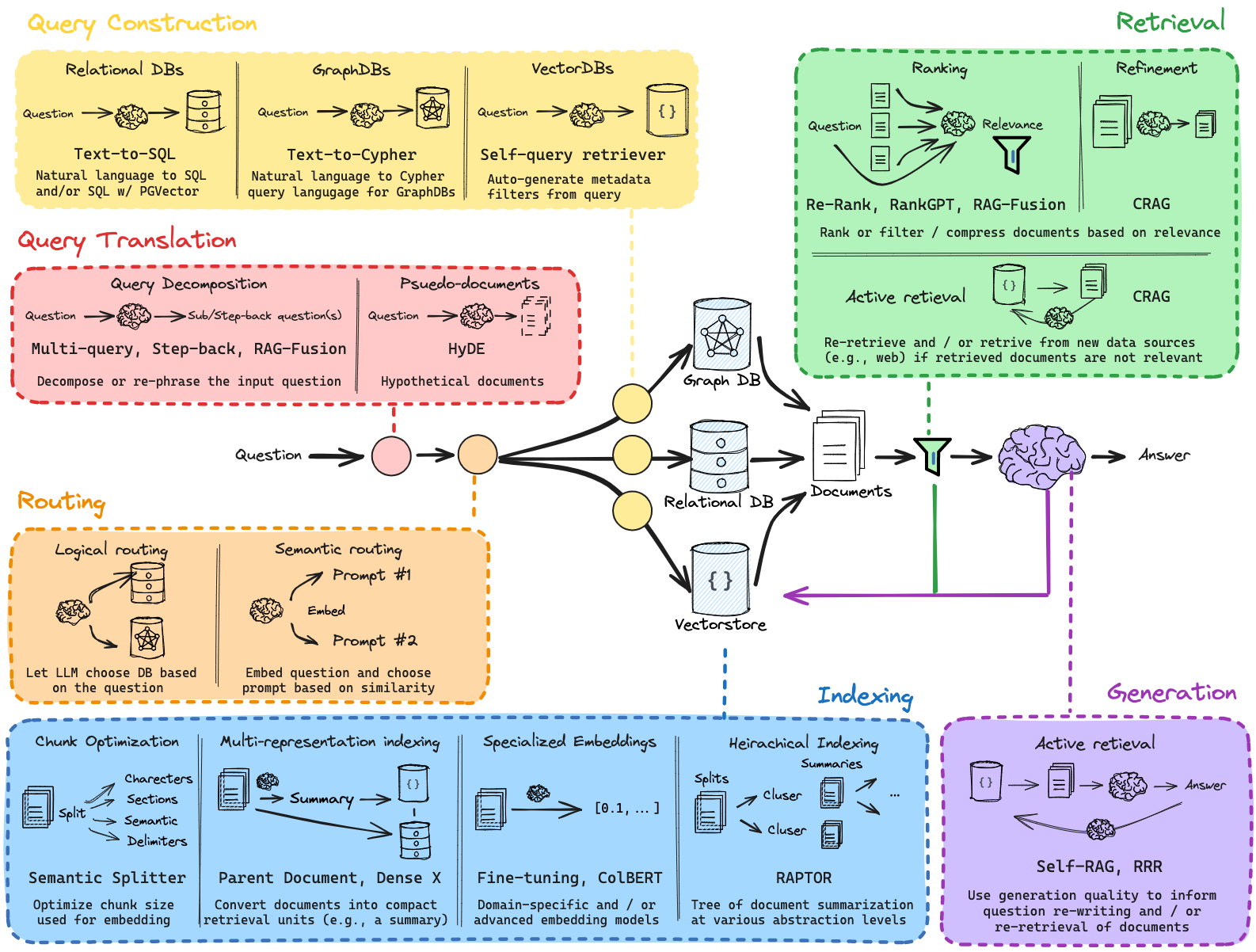
Структура проекта
Если вы хотите сразу приступить к делу, посмотрите файл full_basic_rag.ipynb -> этот файл предоставит вам шаблонный стартовый код полностью настраиваемого чат-бота RAG.
Обязательно запускайте файлы в виртуальной среде (раздел оформления заказа « Get Started »).
Следующие блокноты можно найти в каталоге tutorial_notebooks/ .
[1]_rag_setup_overview.ipynb
В этом вводном блокноте представлен обзор архитектуры RAG и ее базовой настройки. В блокноте проходит:
- Настройка среды : настройка среды, установка необходимых библиотек и настройка API.
- Первоначальная загрузка данных : базовые загрузчики документов и методы предварительной обработки данных.
- Генерация вложений : создание вложений с использованием различных моделей, включая встраивания OpenAI.
- Хранилище векторов : настройка хранилища векторов (ChromaDB/Pinecone) для эффективного поиска по сходству.
- Базовый конвейер RAG : создание простого конвейера поиска и генерации, который будет служить базовым.
[2]_rag_with_multi_query.ipynb
Основываясь на основах, в этом блокноте представлены методы обработки нескольких запросов в конвейере RAG, а также рассматриваются:
- Настройка нескольких запросов : настройка нескольких запросов для разнообразия поиска.
- Передовые методы внедрения : использование нескольких моделей внедрения для уточнения поиска.
- Конвейер с несколькими запросами : реализация обработки нескольких запросов для повышения релевантности при генерации ответов.
- Сравнение и анализ : сравнение результатов с конвейерами с одним запросом и анализ улучшения производительности.
[3]_rag_routing_and_query_construction.ipynb
Этот блокнот углубляет настройку конвейера RAG. Он охватывает:
- Логическая маршрутизация: реализует маршрутизацию на основе функций для классификации пользовательских запросов к соответствующим источникам данных на основе языков программирования.
- Семантическая маршрутизация: использует вложения и косинусное сходство, чтобы направлять вопросы к математическим или физическим подсказкам, оптимизируя точность ответов.
- Структурирование запросов для фильтров метаданных: определяет структурированную схему поиска для метаданных учебных пособий YouTube, обеспечивая расширенную фильтрацию (например, по количеству просмотров, дате публикации).
- Подсказки структурированного поиска. Использует подсказки LLM для создания запросов к базе данных для получения соответствующего контента на основе ввода данных пользователем.
- Интеграция с векторными хранилищами: связывает структурированные запросы с векторными хранилищами для эффективного поиска данных.
[4]_rag_indexing_and_advanced_retreaval.ipynb
Продолжая предыдущую настройку, в этом блокноте рассматриваются:
- Предисловие к разделению документов на части: указывает на внешние ресурсы, посвященные методам разделения документов.
- Индексирование с несколькими представлениями: устанавливает структуру многовекторного индексирования для обработки документов с различными вложениями и представлениями.
- Хранение сводок в памяти: использует InMemoryByteStore для хранения сводок документов вместе с родительскими документами, обеспечивая эффективный поиск.
- Настройка MultiVectorRetriever: объединяет несколько векторных представлений для извлечения соответствующих документов на основе запросов пользователей.
- Реализация RAPTOR: изучает RAPTOR, расширенную модель индексирования и поиска, связанную с подробными ресурсами.
- Интеграция ColBERT: демонстрирует индексирование и извлечение векторов на уровне токенов на основе ColBERT, которые улавливают контекстуальное значение на детальном уровне.
- Пример Википедии с ColBERT: извлекает информацию о Хаяо Миядзаки, используя для демонстрации модель поиска ColBERT.
[5]_rag_retrival_and_reranking.ipynb
Этот последний блокнот объединяет компоненты системы RAG с упором на масштабируемость и оптимизацию:
- Загрузка и разделение документов: загружает и разбивает документы на фрагменты для индексации, подготавливая их для векторного хранения.
- Генерация нескольких запросов с помощью RAG-Fusion: использует подход на основе подсказок для создания нескольких поисковых запросов на основе одного входного вопроса.
- Взаимное объединение рангов (RRF): реализует RRF для повторного ранжирования нескольких списков поиска, объединения результатов для повышения релевантности.
- Настройка цепочки извлечения и RAG: создает цепочку поиска для ответов на запросы, используя объединенные рейтинги и цепочки RAG для извлечения контекстуально значимой информации.
- Повторное ранжирование Cohere: демонстрирует повторное ранжирование с помощью модели Cohere для дополнительного контекстного сжатия и уточнения.
- Извлечение CRAG и Self-RAG: рассматриваются расширенные подходы к поиску, такие как CRAG и Self-RAG, со ссылками на примеры.
- Исследование влияния длительного контекста: ссылки на ресурсы, объясняющие влияние извлечения длинного контекста на модели RAG.
Начиная
Предварительные требования: Python 3.11.7 (предпочтительно)
Клонируем репозиторий :
git clone https://github.com/bRAGAI/bRAG-langchain.git
cd bRAG-langchain
Создайте виртуальную среду
python -m venv venv
source venv/bin/activate
Установите зависимости : Обязательно установите необходимые пакеты, перечисленные в requirements.txt .
pip install -r requirements.txt
Запустите блокноты : начните с [1]_rag_setup_overview.ipynb чтобы ознакомиться с процессом установки. Последовательно просматривайте другие блокноты, чтобы создавать и экспериментировать с более продвинутыми концепциями RAG.
Настройте переменные среды :
Порядок блокнотов : Чтобы структурировано следить за проектом:
Начните с [1]_rag_setup_overview.ipynb
Перейдите к [2]_rag_with_multi_query.ipynb
Затем пройдите [3]_rag_routing_and_query_construction.ipynb
Продолжите с [4]_rag_indexing_and_advanced_retrieval.ipynb
Завершите с помощью [5]_rag_retrieval_and_reranking.ipynb
Использование
После настройки среды и последовательного запуска блокнотов вы можете:
Поэкспериментируйте с расширенной генерацией извлечения . Используйте базовую настройку в [1]_rag_setup_overview.ipynb чтобы понять основы RAG.
Внедрение множественных запросов . Узнайте, как повысить релевантность ответов, представив методы множественных запросов в [2]_rag_with_multi_query.ipynb .
Входящие блокноты (в работе)
- Контекстная точность с RAGAS + LangSmith
- Руководство по использованию RAGAS и LangSmith для оценки точности контекста, релевантности и точности ответов в RAG.
- Развертывание приложения RAG
- Руководство по развертыванию приложения RAG
The notebooks and visual diagrams were inspired by Lance Martin's LangChain Tutorial.


