LaTeX OCR
1.0.0
Цель этого проекта — создать систему, основанную на обучении, которая принимает изображение математической формулы и возвращает соответствующий код LaTeX.
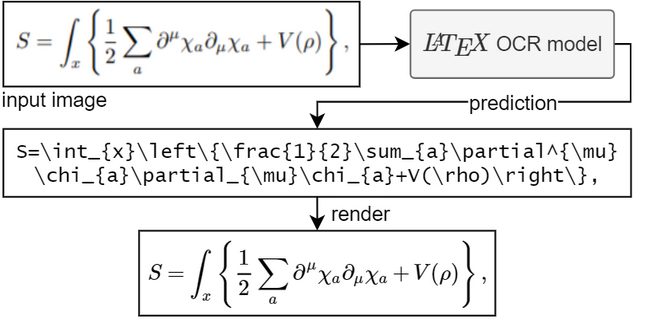
Для запуска модели необходим Python 3.7+.
Если у вас не установлен PyTorch. Следуйте их инструкциям здесь.
Установите пакет pix2tex :
pip install "pix2tex[gui]"
Контрольные точки модели будут загружены автоматически.
Есть три способа получить прогноз по изображению.
Вы можете использовать инструмент командной строки, вызвав pix2tex . Здесь вы можете парсить уже существующие изображения с диска и изображения в буфере обмена.
Благодаря @katie-lim вы можете использовать приятный пользовательский интерфейс как быстрый способ получить прогноз модели. Просто вызовите графический интерфейс с помощью latexocr . Отсюда вы можете сделать снимок экрана, и предсказанный латексный код визуализируется с помощью MathJax и копируется в буфер обмена.
В Linux можно использовать графический интерфейс с gnome-screenshot (который поддерживает несколько мониторов), если gnome-screenshot был установлен заранее. Для Вейланда будут использоваться grim и slurp , когда они оба доступны. Обратите внимание, что gnome-screenshot несовместим с композиторами Wayland на базе wlroots. Поскольку gnome-screenshot будет предпочтительнее, если он доступен, вам, возможно, придется установить переменную среды SCREENSHOT_TOOL на grim (другие доступные значения — gnome-screenshot и pil ).
Если модель не уверена в том, что изображено на изображении, она может выдавать другой прогноз каждый раз, когда вы нажимаете «Повторить». С помощью параметра temperature вы можете контролировать это поведение (низкая температура даст тот же результат).
Вы можете использовать API. Это имеет дополнительные зависимости. Установите через pip install -U "pix2tex[api]" и запустите.
python -m pix2tex.api.run
чтобы запустить демонстрацию Streamlit, которая подключается к API через порт 8502. Для API также доступен образ докера: https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
Чтобы также запустить демонстрационный запускstreamlit
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
и перейдите по адресу http://localhost:8501/.
Использование изнутри Python
из PIL импортировать изображение из pix2tex.cli import LatexOCRimg = Image.open('path/to/image.png')model = LatexOCR()print(model(img))Модель лучше всего работает с изображениями меньшего разрешения. Вот почему я добавил этап предварительной обработки, на котором другая нейронная сеть прогнозирует оптимальное разрешение входного изображения. Эта модель автоматически изменит размер пользовательского изображения, чтобы оно максимально соответствовало обучающим данным, и тем самым повысит производительность изображений, найденных в дикой природе. Тем не менее, он не идеален и, возможно, не сможет оптимально обрабатывать огромные изображения, поэтому не увеличивайте масштаб полностью, прежде чем сделать снимок.
Всегда тщательно проверяйте результат. Вы можете попробовать повторить прогноз с другим разрешением, если ответ был неверным.
Хотите использовать пакет?
Я сейчас пытаюсь собрать документацию.
Посетите здесь: https://pix2tex.readthedocs.io/
Установите пару зависимостей pip install "pix2tex[train]" .
Сначала нам нужно объединить изображения с их фактическими метками. Я написал класс набора данных (который нуждается в дальнейшем улучшении), который сохраняет относительные пути к изображениям с кодом LaTeX, с помощью которого они были визуализированы. Чтобы создать файл Pickle набора данных, запустите
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
Чтобы использовать собственный токенизатор, передайте его через --tokenizer (см. ниже).
Вы также можете найти мои сгенерированные данные обучения на Google Диске (formulae.zip — изображения, math.txt — метки). Повторите этот шаг для данных проверки и тестирования. Все используют один и тот же текстовый файл метки.
Измените запись data (и valdata ) в файле конфигурации на вновь созданный файл .pkl . Если хотите, измените другие гиперпараметры. Шаблон см. в pix2tex/model/settings/config.yaml .
Теперь о самом тренировочном забеге
python -m pix2tex.train --config path_to_config_file
Если вы хотите использовать свои собственные данные, возможно, вас заинтересует создание собственного токенизатора с помощью
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
Не забудьте обновить путь к токенизатору в файле конфигурации и установить num_tokens в соответствии с размером вашего словаря.
Модель состоит из кодера ViT [1] с магистральной сетью ResNet и декодера Transformer [2].
| Оценка BLEU | нормированное расстояние редактирования | точность токена |
|---|---|---|
| 0,88 | 0,10 | 0,60 |
Нам нужны парные данные, чтобы сеть могла учиться. К счастью, в Интернете есть много кода LaTeX, например, в Википедии, arXiv. Мы также используем формулы из набора данных im2latex-100k [3]. Все это можно найти здесь
Чтобы отобразить математические данные в различных шрифтах, мы используем XeLaTeX, создаем PDF-файл и, наконец, конвертируем его в PNG. На последнем шаге нам нужно использовать сторонние инструменты:
КселаТекс
ImageMagick с Ghostscript. (для конвертации PDF в PNG)
Node.js для запуска KaTeX (для нормализации кода Latex)
Python 3.7+ и зависимости (указанные в setup.py )
Современная латинская математика, GFSNeoellenicMath.otf, Asana Math, XITS Math, Cambria Math
добавить больше показателей оценки
создать графический интерфейс
добавить поиск по лучу
поддержка рукописных формул (вроде как готово, см. учебный блокнот Colab)
уменьшить размер модели (перегонка)
найти оптимальные гиперпараметры
изменить структуру модели
исправить очистку данных и очистить больше данных
проследить модель (#2)
Вклад любого рода приветствуется.
Код взят и модифицирован из lucidrains, rwightman, im2markup, arxiv_leaks, pkra: Mathjax, harupy: инструмента для резки
[1] Изображение стоит 16x16 слов.
[2] Внимание — это все, что вам нужно
[3] Генерация изображения в разметке с грубым и точным вниманием


