segment anything
1.0.0
Пожалуйста, ознакомьтесь с нашим новым выпуском Segment Anything Model 2 (SAM 2) .
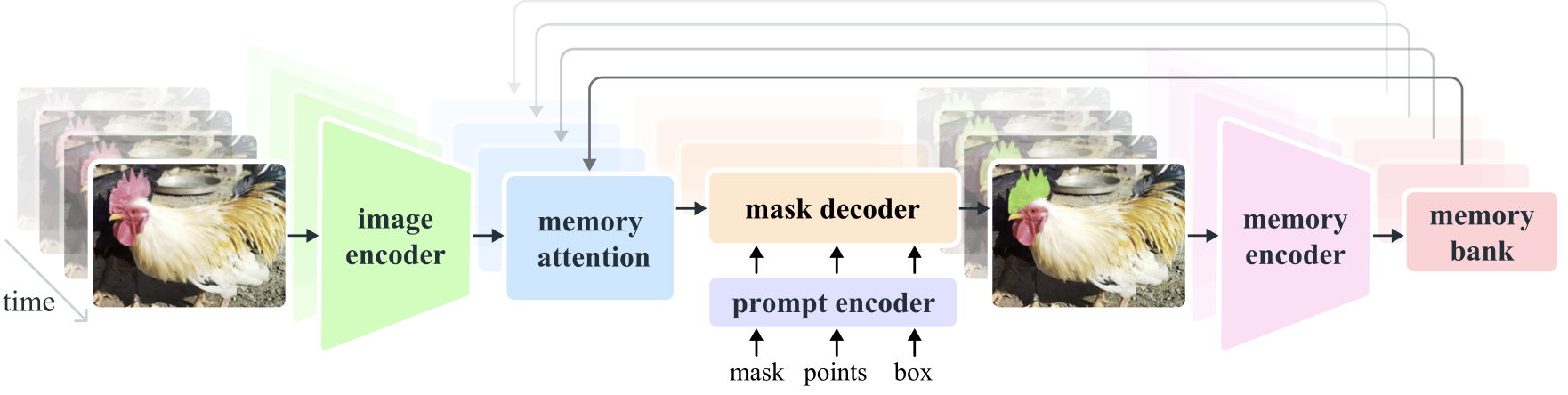
Segment Anything Model 2 (SAM 2) — это базовая модель для решения быстрой визуальной сегментации изображений и видео. Мы расширяем SAM на видео, рассматривая изображения как видео с одним кадром. Конструкция модели представляет собой простую архитектуру преобразователя с потоковой памятью для обработки видео в реальном времени. Мы создаем механизм обработки данных «модель в цикле», который улучшает модель и данные посредством взаимодействия с пользователем, чтобы собрать наш набор данных SA-V , крупнейший на сегодняшний день набор данных сегментации видео. SAM 2, обученный на наших данных, обеспечивает высокую производительность в широком спектре задач и визуальных областей.
Мета-исследование искусственного интеллекта, FAIR
Александр Кириллов, Эрик Минтун, Никила Рави, Ханзи Мао, Хлоя Роллан, Лаура Густафсон, Тете Сяо, Спенсер Уайтхед, Алекс Берг, Ван-Йен Ло, Петр Доллар, Росс Гиршик
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
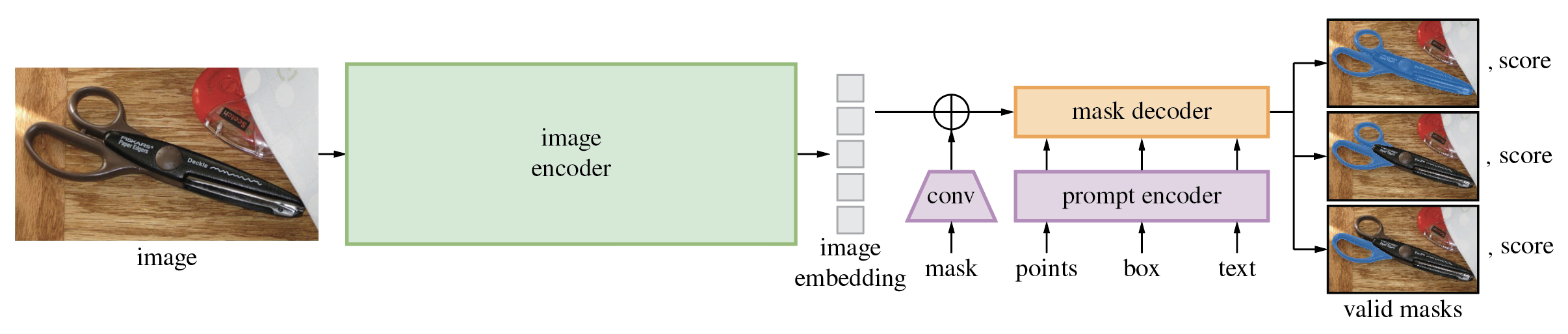
Модель Segment Anything Model (SAM) создает высококачественные маски объектов из подсказок ввода, таких как точки или прямоугольники, и ее можно использовать для создания масок для всех объектов на изображении. Он был обучен на наборе данных, состоящем из 11 миллионов изображений и 1,1 миллиарда масок, и демонстрирует высокую производительность с нулевым результатом при выполнении различных задач сегментации.


Для кода требуется python>=3.8 , а также pytorch>=1.7 и torchvision>=0.8 . Следуйте инструкциям здесь, чтобы установить зависимости PyTorch и TorchVision. Настоятельно рекомендуется установить PyTorch и TorchVision с поддержкой CUDA.
Установить сегмент что угодно:
pip install git+https://github.com/facebookresearch/segment-anything.git
или клонируйте репозиторий локально и установите с помощью
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
Следующие дополнительные зависимости необходимы для постобработки маски, сохранения масок в формате COCO, примеров блокнотов и экспорта модели в формате ONNX. jupyter также необходим для запуска примеров блокнотов.
pip install opencv-python pycocotools matplotlib onnxruntime onnx
Сначала скачайте модель КПП. Затем модель можно использовать всего в несколько строк для получения масок по заданному приглашению:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
или сгенерируйте маски для всего изображения:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
Дополнительно маски для изображений можно генерировать из командной строки:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
Дополнительные сведения см. в блокнотах с примерами использования SAM с подсказками и автоматическим созданием масок.


Облегченный декодер маски SAM можно экспортировать в формат ONNX, чтобы его можно было запускать в любой среде, поддерживающей среду выполнения ONNX, например в браузере, как показано в демонстрации. Экспортируйте модель с помощью
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
См. пример блокнота для получения подробной информации о том, как объединить предварительную обработку изображений через магистраль SAM с прогнозированием по маске с использованием модели ONNX. Для экспорта ONNX рекомендуется использовать последнюю стабильную версию PyTorch.
В папке demo/ есть простое одностраничное приложение React, которое показывает, как запустить прогнозирование по маске с помощью экспортированной модели ONNX в веб-браузере с многопоточностью. Пожалуйста, смотрите demo/README.md для более подробной информации.
Доступны три модельные версии модели с разными размерами магистрали. Эти модели можно создать, запустив
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
Нажмите на ссылку ниже, чтобы загрузить контрольную точку для соответствующего типа модели.
default или vit_h : модель ViT-H SAM.vit_l : модель ЗРК ВиТ-Л.vit_b : модель ЗРК ВиТ-Б. См. здесь обзор набора данных. Набор данных можно скачать здесь. Загружая наборы данных, вы соглашаетесь с тем, что прочитали и приняли условия лицензии на исследование наборов данных SA-1B.
Мы сохраняем маски для каждого изображения в виде файла json. Его можно загрузить как словарь в Python в формате ниже.
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}Идентификаторы изображений можно найти в файле sa_images_ids.txt, который также можно загрузить по ссылке выше.
Чтобы декодировать маску в формате COCO RLE в двоичный код:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
Дополнительные инструкции по управлению масками, хранящимися в формате RLE, см. здесь.
Модель распространяется по лицензии Apache 2.0.
См. вклад и кодекс поведения.
Проект Segment Anything стал возможен благодаря многим участникам (в алфавитном порядке):
Аарон Адкок, Вайбхав Аггарвал, Мортеза Бехруз, Ченг-Ян Фу, Эшли Гэбриэл, Ахува Голдстанд, Аллен Гудман, Сумант Гуррам, Цзябо Ху, Сомья Джайн, Деванш Кукреджа, Роберт Куо, Джошуа Лейн, Янхао Ли, Лилиан Луонг, Джитендра Малик, Маллика Малхотра, Уильям Нган, Омкар Паркхи, Нихил Райна, Дирк Роу, Нил Седжор, Ванесса Старк, Бала Варадараджан, Брэм Васти, Закари Уинстром
Если вы используете SAM или SA-1B в своих исследованиях, используйте следующую запись BibTeX.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


