obfuscated gradients
v1.0.0
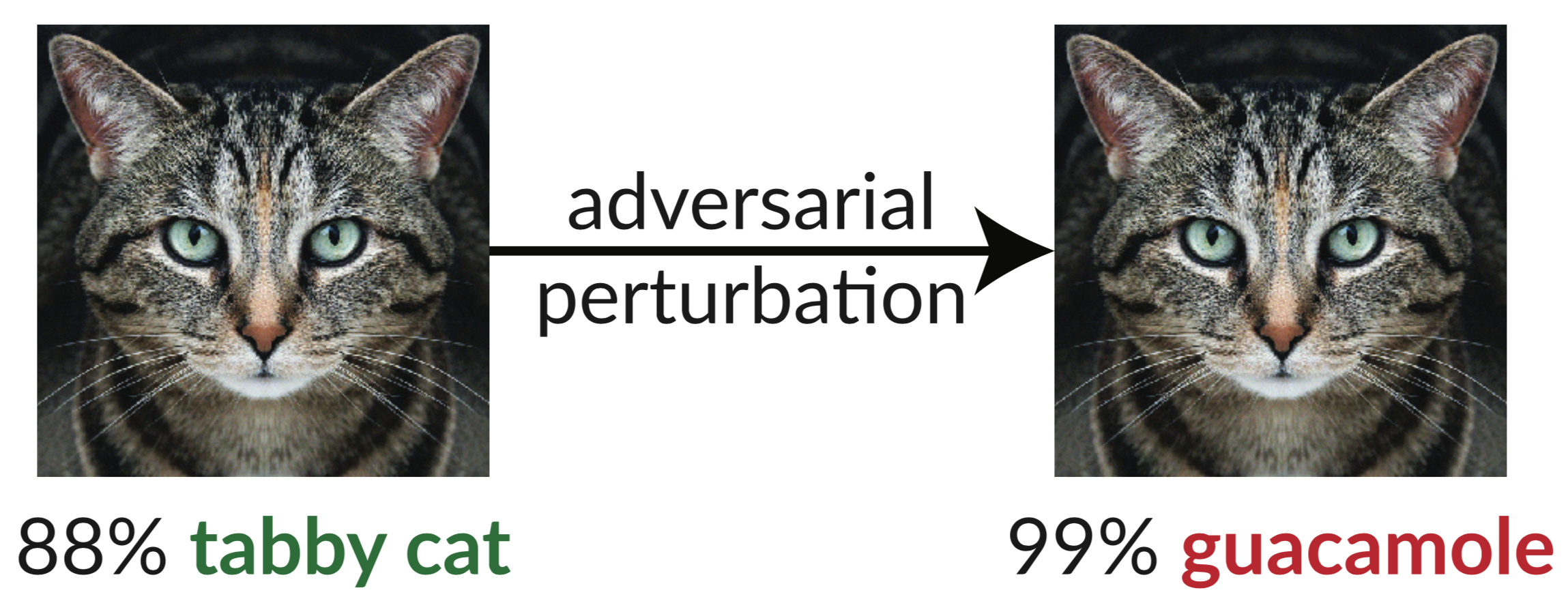
Выше приведен состязательный пример: слегка искаженное изображение кошки обманывает классификатор InceptionV3, заставляя его классифицировать его как «гуакамоле». Такие «обманчивые изображения» легко синтезировать с помощью градиентного спуска (Szegedy et al., 2013).
В нашей недавней статье мы оцениваем надежность девяти документов, принятых на ICLR 2018, в качестве несертифицированных средств защиты «белого ящика» от состязательных примеров. Мы обнаружили, что семь из девяти защит обеспечивают ограниченное увеличение устойчивости и могут быть взломаны с помощью усовершенствованных методов атаки, которые мы разрабатываем.
Ниже представлена таблица 1 из нашей статьи, где мы показываем устойчивость каждой принятой защиты к состязательным примерам, которые мы можем построить:
| Оборона | Набор данных | Расстояние | Точность |
|---|---|---|---|
| Бакман и др. (2018) | СИФАР | 0,031 (линф) | 0%* |
| Ма и др. (2018) | СИФАР | 0,031 (линф) | 5% |
| Го и др. (2018) | ImageNet | 0,05 (л2) | 0%* |
| Диллон и др. (2018) | СИФАР | 0,031 (линф) | 0% |
| Се и др. (2018) | ImageNet | 0,031 (линф) | 0%* |
| Сонг и др. (2018) | СИФАР | 0,031 (линф) | 9%* |
| Самангуэй и др. (2018) | МНИСТ | 0,005 (л2) | 55%** |
| Мэдри и др. (2018) | СИФАР | 0,031 (линф) | 47% |
| На и др. (2018) | СИФАР | 0,015 (линф) | 15% |
(Защиты, обозначенные *, также предполагают комбинирование состязательных тренировок; мы сообщаем здесь только о защите. Полные цифры см. в нашей статье, раздел 5. Фундаментальный принцип защиты, обозначенный **, имеет точность 0%; на практике несовершенства защиты вызывают теоретически оптимальная атака для провала, подробности см. в разделе 5.4.2.)
Единственная защита, которую мы наблюдаем, которая значительно повышает устойчивость к состязательным примерам в рамках предложенной модели угроз, — это «На пути к моделям глубокого обучения, устойчивым к состязательным атакам» (Мадри и др., 2018), и мы не смогли преодолеть эту защиту, не выйдя за пределы модели угроз. . Даже тогда было показано, что этот метод трудно масштабировать до масштаба ImageNet (Куракин и др., 2016). Остальные статьи (кроме статьи На и др., которая обеспечивает ограниченную надежность) либо непреднамеренно, либо намеренно полагаются на то, что мы называем запутанными градиентами . Стандартные атаки применяют градиентный спуск, чтобы максимизировать потери сети на данном изображении для создания состязательного примера в нейронной сети. Для успеха таких методов оптимизации требуется полезный градиентный сигнал. Когда защита запутывает градиенты, она нарушает этот сигнал градиента и приводит к сбою методов, основанных на оптимизации.
Мы определяем три способа, с помощью которых средства защиты вызывают запутанные градиенты, и конструируем атаки для обхода каждого из этих случаев. Наши атаки обычно применимы к любой защите, которая намеренно или непреднамеренно включает недифференцируемую операцию или иным образом предотвращает прохождение градиентного сигнала через сеть. Мы надеемся, что в будущем мы сможем использовать наши подходы для более тщательной оценки безопасности.
Абстрактный:
Мы определяем запутанные градиенты, своего рода маскировку градиента, как явление, которое приводит к ложному чувству безопасности при защите от состязательных примеров. Хотя защита, вызывающая запутанные градиенты, по-видимому, отбивает итеративные атаки, основанные на оптимизации, мы обнаружили, что защиту, основанную на этом эффекте, можно обойти. Мы описываем характерное поведение защит, проявляющих этот эффект, и для каждого из трех обнаруженных нами типов запутанных градиентов разрабатываем методы атаки для его преодоления. В тематическом исследовании, посвященном изучению несертифицированных средств защиты «белого ящика» на ICLR 2018, мы обнаружили, что запутанные градиенты являются обычным явлением: 7 из 9 защит полагаются на запутанные градиенты. Наши новые атаки успешно обходят 6 полностью и 1 частично из исходной модели угроз, рассматриваемой в каждой статье.
Подробности читайте в нашей статье.
В этом репозитории содержатся примеры общих техник атак, описанных в нашей статье, которые взламывают семь защит ICLR 2018. Некоторые средства защиты не опубликовали исходный код (на тот момент, когда мы проводили эту работу), поэтому нам пришлось их переопределить.
@inproceedings{obfuscated-gradients,author = {Аниш Атали, Николас Карлини и Дэвид Вагнер}, title = {Запутанные градиенты дают ложное чувство безопасности: обход защиты от состязательных примеров}, booktitle = {Материалы 35-й Международной конференции по машинам Обучение, {ICML} 2018}, год = {2018}, месяц = июль, URL = {https://arxiv.org/abs/1802.00420},
} 

