Megatron LM
NVIDIA Megatron Core 0.9.0
Этот репозиторий состоит из двух основных компонентов: Megatron-LM и Megatron-Core . Megatron-LM служит исследовательско-ориентированной структурой, использующей Megatron-Core для обучения моделям большого языка (LLM). Megatron-Core, с другой стороны, представляет собой библиотеку методов обучения, оптимизированных для графических процессоров, которая поставляется с формальной поддержкой продукта, включая API с поддержкой версий и регулярные выпуски. Вы можете использовать Megatron-Core вместе с Megatron-LM или Nvidia NeMo Framework для создания комплексного облачного решения. Альтернативно вы можете интегрировать строительные блоки Megatron-Core в предпочитаемую вами систему обучения.
Впервые представленный в 2019 году, Megatron (1, 2 и 3) вызвал волну инноваций в сообществе искусственного интеллекта, позволив исследователям и разработчикам использовать основы этой библиотеки для дальнейшего развития LLM. Сегодня многие из самых популярных платформ для разработчиков LLM были созданы на основе библиотеки Megatron-LM с открытым исходным кодом, что вызвало волну фундаментальных моделей и стартапов в области искусственного интеллекта. Некоторые из самых популярных фреймворков LLM, созданных на базе Megatron-LM, включают Colossal-AI, HuggingFace Accelerate и NVIDIA NeMo Framework. Список проектов, в которых непосредственно использовался Мегатрон, можно найти здесь.
Megatron-Core — это библиотека с открытым исходным кодом на основе PyTorch, которая содержит методы оптимизации для графического процессора и передовые оптимизации на уровне системы. Он абстрагирует их в составные и модульные API, предоставляя разработчикам и исследователям моделей полную гибкость при обучении пользовательских преобразователей в масштабе в инфраструктуре ускоренных вычислений NVIDIA. Эта библиотека совместима со всеми графическими процессорами NVIDIA Tensor Core, включая поддержку ускорения FP8 для архитектур NVIDIA Hopper.
Megatron-Core предлагает основные строительные блоки, такие как механизмы внимания, блоки и слои преобразователей, уровни нормализации и методы внедрения. Дополнительные функции, такие как повторный расчет активации и распределенная контрольная точка, также встроены в библиотеку. Все строительные блоки и функциональные возможности оптимизированы для графического процессора и могут быть созданы с использованием передовых стратегий распараллеливания для оптимальной скорости и стабильности обучения в инфраструктуре ускоренных вычислений NVIDIA. Другой ключевой компонент библиотеки Megatron-Core включает в себя расширенные методы параллелизма моделей (тензорный, последовательный, конвейерный, контекстный и экспертный параллелизм MoE).
Megatron-Core можно использовать с NVIDIA NeMo, платформой искусственного интеллекта корпоративного уровня. Кроме того, вы можете изучить Megatron-Core с помощью встроенного цикла обучения PyTorch здесь. Чтобы узнать больше, посетите документацию Megatron-Core.
Наша кодовая база способна эффективно обучать большие языковые модели (т. е. модели с сотнями миллиардов параметров) с параллелизмом как моделей, так и данных. Чтобы продемонстрировать, как наше программное обеспечение масштабируется с несколькими графическими процессорами и размерами моделей, мы рассматриваем модели GPT в диапазоне от 2 миллиардов параметров до 462 миллиардов параметров. Все модели используют размер словаря 131 072 и длину последовательности 4096. Мы варьируем скрытый размер, количество головок внимания и количество слоев, чтобы достичь определенного размера модели. По мере увеличения размера модели мы также слегка увеличиваем размер партии. В наших экспериментах используется до 6144 графических процессоров H100. Мы выполняем детальное перекрытие параллельной передачи данных ( --overlap-grad-reduce --overlap-param-gather ), тензорно-параллельной ( --tp-comm-overlap ) и параллельной связи по конвейеру (включено по умолчанию) с помощью вычисления для улучшения масштабируемости. Сообщаемая пропускная способность измеряется для сквозного обучения и включает все операции, включая загрузку данных, шаги оптимизатора, связь и даже ведение журнала. Обратите внимание, что мы не обучали эти модели сходимости.
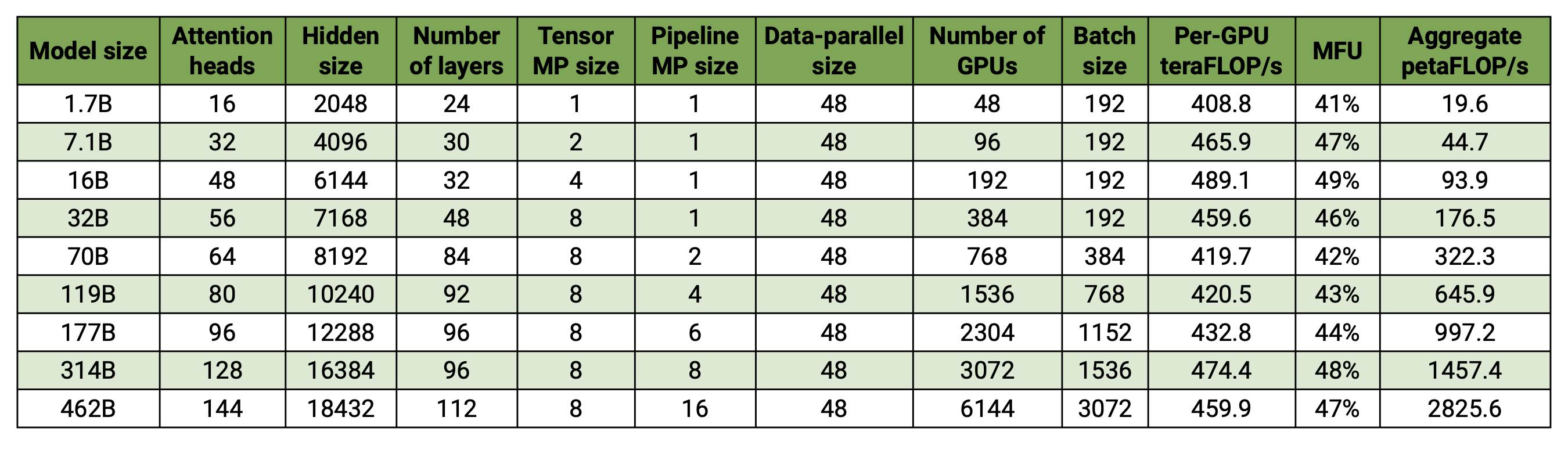
Наши результаты со слабым масштабированием показывают суперлинейное масштабирование (MFU увеличивается с 41% для самой маленькой рассматриваемой модели до 47-48% для самой большой модели); это связано с тем, что более крупные GEMM имеют более высокую арифметическую интенсивность и, следовательно, более эффективны в выполнении.
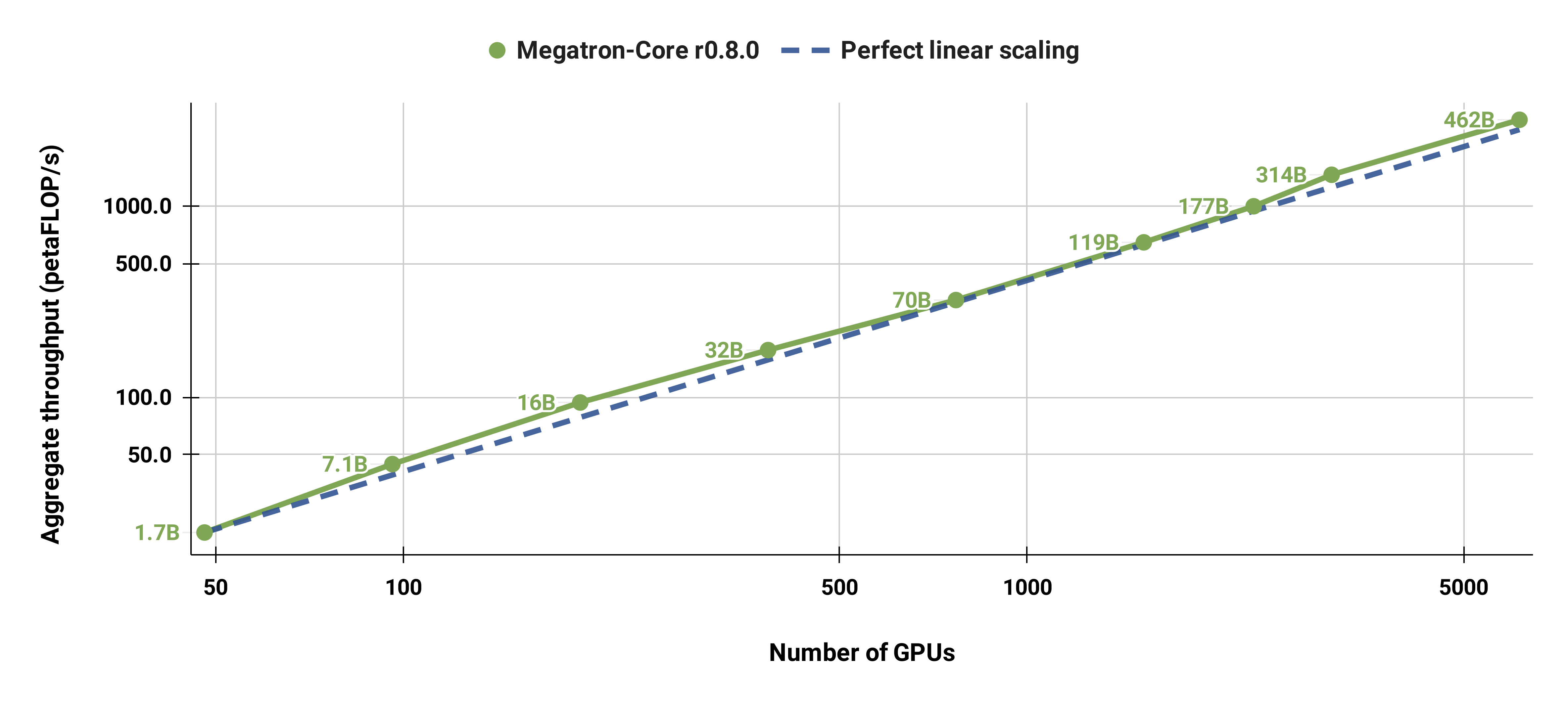
Мы также сильно масштабировали стандартную модель GPT-3 (наша версия имеет чуть более 175 миллиардов параметров из-за большего размера словаря) с 96 графических процессоров H100 до 4608 графических процессоров, используя одинаковый размер пакета в 1152 последовательностей. Коммуникация становится более открытой в больших масштабах, что приводит к сокращению MFU с 47% до 42%.
Мы настоятельно рекомендуем использовать последнюю версию контейнера PyTorch от NGC с узлами DGX. Если по какой-то причине вы не можете использовать это, используйте последние версии pytorch, cuda, nccl и NVIDIA APEX. Для предварительной обработки данных требуется NLTK, хотя это не требуется для обучения, оценки или последующих задач.
Вы можете запустить экземпляр контейнера PyTorch и смонтировать Megatron, ваш набор данных и контрольные точки с помощью следующих команд Docker:
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
Мы предоставили предварительно обученные контрольные точки BERT-345M и GPT-345M для оценки или точной настройки последующих задач. Чтобы получить доступ к этим контрольным точкам, сначала зарегистрируйтесь и настройте интерфейс командной строки реестра NVIDIA GPU Cloud (NGC). Дополнительную документацию по загрузке моделей можно найти в документации NGC.
Кроме того, вы можете напрямую загрузить контрольные точки, используя:
BERT-345M-без корпуса: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip В корпусе BERT-345M: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
Для запуска моделей требуются файлы словаря. Файл словаря BERT WordPiece можно извлечь из предварительно обученных моделей BERT Google: без регистра, с регистром. Файл словаря GPT и таблицу слияния можно загрузить напрямую.
После установки существует несколько возможных рабочих процессов. Наиболее полным является:
Однако шаги 1 и 2 можно заменить, используя одну из предварительно обученных моделей, упомянутых выше.
В каталоге examples мы предоставили несколько сценариев для предварительного обучения как BERT, так и GPT, а также сценарии как для нулевых, так и для точно настроенных последующих задач, включая оценку MNLI, RACE, WikiText103 и LAMBADA. Также имеется скрипт для интерактивной генерации текста GPT.
Данные обучения требуют предварительной обработки. Во-первых, поместите данные обучения в свободный формат JSON, где один JSON будет содержать образец текста в каждой строке. Например:
{"src": "www.nvidia.com", "text": "Быстрая коричневая лисица", "type": "Eng", "id": "0", "title": "Первая часть"}
{"src": "Интернет", "text": "перепрыгивает через ленивую собаку", "type": "Eng", "id": "42", "title": "Вторая часть"}
Имя text поля json можно изменить с помощью флага --json-key в preprocess_data.py Остальные метаданные не являются обязательными и не используются при обучении.
Свободный json затем преобразуется в двоичный формат для обучения. Чтобы преобразовать json в формат mmap, используйте preprocess_data.py . Пример сценария для подготовки данных для обучения BERT:
инструменты Python/preprocess_data.py
--input my-corpus.json
--output-prefix мой-берт
--vocab-file bert-vocab.txt
--tokenizer-type BertWordPieceLowerCase
--split-sentences
Результатом будут два файла с именами, в данном случае my-bert_text_sentence.bin и my-bert_text_sentence.idx . --data-path указанный в более позднем обучении BERT, представляет собой полный путь и новое имя файла, но без расширения файла.
Для T5 используйте ту же предварительную обработку, что и BERT, возможно, переименовав ее в:
--output-prefix my-t5
Для предварительной обработки данных GPT необходимы некоторые незначительные изменения, а именно добавление таблицы слияния, токена конца документа, удаление разделения предложений и изменение типа токенизатора:
инструменты Python/preprocess_data.py
--input my-corpus.json
--output-prefix my-gpt2
--vocab-file gpt2-vocab.json
--tokenizer-type GPT2BPETokenizer
--merge-file gpt2-merges.txt
--append-eod
Здесь выходные файлы называются my-gpt2_text_document.bin и my-gpt2_text_document.idx . Как и раньше, при обучении GPT используйте более длинное имя без расширения --data-path .
Дальнейшие аргументы командной строки описаны в исходном файле preprocess_data.py .
Скрипт examples/bert/train_bert_340m_distributed.sh запускает предварительное обучение BERT для одного параметра GPU 345M. Отладка — это основное применение обучения с одним графическим процессором, поскольку база кода и аргументы командной строки оптимизированы для высокораспределенного обучения. Большинство аргументов достаточно очевидны. По умолчанию скорость обучения снижается линейно в течение итераций обучения, начиная с --lr до минимума, установленного --min-lr в течение итераций --lr-decay-iters . Доля обучающих итераций, используемых для разминки, задается параметром --lr-warmup-fraction . Хотя это обучение с одним графическим процессором, размер пакета, указанный --micro-batch-size , представляет собой один размер пакета вперед и назад, и код будет выполнять шаги накопления градиента, пока не достигнет global-batch-size , который является размером пакета. за итерацию. Данные разделены с соотношением 949:50:1 для наборов обучения/проверки/тестирования (по умолчанию — 969:30:1). Это разделение происходит на лету, но одинаково для всех запусков с одним и тем же случайным начальным числом (по умолчанию 1234 или указано вручную с помощью --seed ). Мы используем train-iters в качестве запрошенных обучающих итераций. В качестве альтернативы можно указать --train-samples — общее количество образцов для обучения. Если эта опция присутствует, то вместо предоставления --lr-decay-iters необходимо будет указать --lr-decay-samples .
Указываются параметры ведения журнала, сохранения контрольных точек и интервала оценки. Обратите внимание, что --data-path теперь включает дополнительный суффикс _text_sentence добавленный при предварительной обработке, но не включает расширения файлов.
Дальнейшие аргументы командной строки описаны в исходном файле arguments.py .
Чтобы запустить train_bert_340m_distributed.sh , внесите любые необходимые изменения, включая установку переменных среды для CHECKPOINT_PATH , VOCAB_FILE и DATA_PATH . Обязательно установите для этих переменных соответствующие пути в контейнере. Затем запустите контейнер с установленными Megatron и необходимыми путями (как описано в разделе «Настройка») и запустите пример сценария.
Скрипт examples/gpt3/train_gpt3_175b_distributed.sh запускает предварительное обучение GPT для одного параметра GPU 345M. Как упоминалось выше, обучение на одном графическом процессоре в первую очередь предназначено для целей отладки, поскольку код оптимизирован для распределенного обучения.
Он в основном соответствует тому же формату, что и предыдущий сценарий BERT, с некоторыми заметными отличиями: используется схема токенизации BPE (которая требует таблицы слияния и файла словаря json ) вместо WordPiece, архитектура модели допускает более длинные последовательности (обратите внимание, что максимальное внедрение позиции должно быть больше или равно максимальной длине последовательности), а для --lr-decay-style установлено косинусное затухание. Обратите внимание, что --data-path теперь включает дополнительный суффикс _text_document добавленный при предварительной обработке, но не включает расширения файлов.
Дальнейшие аргументы командной строки описаны в исходном файле arguments.py .
train_gpt3_175b_distributed.sh можно запустить так же, как описано для BERT. Установите переменные окружения и внесите любые другие изменения, запустите контейнер с соответствующими монтированиями и запустите скрипт. Подробнее в examples/gpt3/README.md
Очень похожий на BERT и GPT, сценарий examples/t5/train_t5_220m_distributed.sh запускает «базовое» (параметр ~220M) предварительное обучение T5 для одного графического процессора. Основное отличие от BERT и GPT — добавление следующих аргументов для соответствия архитектуре T5:
--kv-channels устанавливает внутреннюю размерность матриц «ключей» и «значений» всех механизмов внимания в модели. Для BERT и GPT по умолчанию это скрытый размер, разделенный на количество головок внимания, но его можно настроить для T5.
--ffn-hidden-size устанавливает скрытый размер в сетях прямой связи внутри слоя преобразователя. Для BERT и GPT по умолчанию это значение в 4 раза превышает скрытый размер трансформатора, но его можно настроить для T5.
--encoder-seq-length и --decoder-seq-length устанавливают длину последовательности для кодера и декодера отдельно.
Все остальные аргументы остаются такими же, как и в пользу предварительной подготовки BERT и GPT. Запустите этот пример, выполнив те же действия, которые описаны выше для других сценариев.
Подробнее в examples/t5/README.md
Скрипты pretrain_{bert,gpt,t5}_distributed.sh используют распределенную программу запуска PyTorch для распределенного обучения. Таким образом, обучение нескольких узлов может быть достигнуто путем правильной настройки переменных среды. Дополнительную информацию об этих переменных среды см. в официальной документации PyTorch. По умолчанию при многоузловом обучении используется распределенный бэкэнд nccl. Простой набор дополнительных аргументов и использование распределенного модуля PyTorch с эластичным средством запуска torchrun (эквивалентным python -m torch.distributed.run ) — единственные дополнительные требования для внедрения распределенного обучения. Дополнительную информацию см. в любом из файлов pretrain_{bert,gpt,t5}_distributed.sh .
Мы используем два типа параллелизма: параллелизм данных и параллелизм моделей. Наша реализация параллелизма данных находится в megatron/core/distributed и поддерживает перекрытие уменьшения градиента с обратным проходом, когда используется параметр командной строки --overlap-grad-reduce .
Во-вторых, мы разработали простой и эффективный подход, основанный на двумерных параллельных моделях. Чтобы использовать первое измерение, параллелизм тензорной модели (разделение выполнения одного модуля преобразователя на несколько графических процессоров, см. раздел 3 нашей статьи), добавьте флаг --tensor-model-parallel-size , чтобы указать количество графических процессоров, среди которых необходимо разделите модель вместе с аргументами, переданными в распределенную программу запуска, как указано выше. Чтобы использовать второе измерение, параллелизм последовательностей, укажите --sequence-parallel , который также требует включения параллелизма тензорной модели, поскольку он распределяется по одним и тем же графическим процессорам (подробнее см. в разделе 4.2.2 нашей статьи).
Чтобы использовать параллелизм модели конвейера (разделение модулей-трансформеров на этапы с равным количеством модулей-трансформеров на каждом этапе, а затем конвейерное выполнение путем разбиения пакета на более мелкие микропакеты, см. раздел 2.2 нашей статьи), используйте --pipeline-model-parallel-size Флаг --pipeline-model-parallel-size чтобы указать количество этапов, на которые нужно разбить модель (например, разделение модели с 24 слоями преобразователей на 4 этапа будет означать, что каждый этап получит по 6 слоев преобразователя).
У нас есть примеры использования этих двух разных форм параллелизма моделей: примеры сценариев, заканчивающиеся на distributed_with_mp.sh .
За исключением этих незначительных изменений, распределенное обучение идентично обучению на одном графическом процессоре.
График чередующейся конвейерной обработки (подробнее см. в разделе 2.2.2 нашей статьи) можно включить с помощью аргумента --num-layers-per-virtual-pipeline-stage , который контролирует количество слоев преобразователя в виртуальной стадии (по умолчанию при нечередующемся расписании каждый графический процессор будет выполнять один виртуальный этап с NUM_LAYERS / PIPELINE_MP_SIZE слоями преобразователя). Общее количество слоев в модели трансформатора должно быть кратно значению этого аргумента. Кроме того, количество микропакетов в конвейере (вычисленное как GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) ) должно быть кратно PIPELINE_MP_SIZE при использовании этого расписания (это условие проверяется в утверждении в коде). Чередованное расписание не поддерживается для конвейеров с двумя этапами ( PIPELINE_MP_SIZE=2 ).
Чтобы уменьшить использование памяти графического процессора при обучении большой модели, мы поддерживаем различные формы контрольных точек активации и повторных вычислений. Вместо того, чтобы все активации сохранялись в памяти для использования во время обратного распространения, как это традиционно было в моделях глубокого обучения, в памяти сохраняются (или сохраняются) только активации в определенных «контрольных точках» модели, а остальные активации пересчитываются -Муха, когда это необходимо для обратной опоры. Обратите внимание, что этот тип контрольных точек, контрольных точек активации , сильно отличается от контрольных точек параметров модели и состояния оптимизатора, которые упоминаются в другом месте.
Мы поддерживаем два уровня детализации пересчета: selective и full . Выборочный перерасчет используется по умолчанию и рекомендуется практически во всех случаях. В этом режиме в памяти сохраняются активации, которые занимают меньше места в памяти и перевычисление которых обходится дороже, а также пересчитываются активации, которые занимают больше места в памяти, но перевычисление которых относительно недорого. Подробности смотрите в нашей статье. Вы обнаружите, что этот режим обеспечивает максимальную производительность при минимальном объеме памяти, необходимой для хранения активаций. Чтобы включить перерасчет выборочной активации, просто используйте --recompute-activations .
В случаях, когда память очень ограничена, full перерасчет сохраняет только входные данные в слой преобразователя, группу или блок слоев преобразователя и пересчитывает все остальное. Чтобы включить полную активацию перерасчета, используйте --recompute-granularity full . При использовании перевычисления full активации существует два метода: uniform и block , выбираемые с помощью аргумента --recompute-method .
uniform метод равномерно делит слои преобразователя на группы слоев (каждая группа размером --recompute-num-layers ) и сохраняет входные активации каждой группы в памяти. Размер базовой группы равен 1, и в этом случае сохраняется входная активация каждого слоя преобразователя. Когда памяти графического процессора недостаточно, увеличение количества слоев в группе снижает использование памяти, позволяя обучать более крупную модель. Например, если для --recompute-num-layers установлено значение 4, сохраняется только входная активация каждой группы из 4 слоев преобразователя.
block метод пересчитывает входные активации определенного числа (заданного --recompute-num-layers ) отдельных слоев преобразователя на каждом этапе конвейера и сохраняет входные активации остальных слоев на этапе конвейера. Уменьшение --recompute-num-layers приводит к сохранению входных активаций в большем количестве слоев преобразователя, что уменьшает необходимость повторного вычисления активации в обратном распространении, тем самым улучшая производительность обучения и одновременно увеличивая использование памяти. Например, когда мы указываем 5 слоев для пересчета по 8 слоев на каждом этапе конвейера, входные активации только первых 5 слоев преобразователя пересчитываются на этапе обратного распространения, в то время как входные активации для последних 3 слоев сохраняются. --recompute-num-layers можно постепенно увеличивать до тех пор, пока объем требуемого пространства памяти не станет достаточно мал, чтобы поместиться в доступную память, тем самым максимально используя память и максимизируя производительность.
Использование: --use-distributed-optimizer . Совместим со всеми моделями и типами данных.
Распределенный оптимизатор — это метод экономии памяти, при котором состояние оптимизатора равномерно распределяется по рангам параллельных данных (по сравнению с традиционным методом репликации состояния оптимизатора по рангам параллельных данных). Как описано в ZeRO: оптимизация памяти для обучения моделей с триллионом параметров, наша реализация распределяет все состояния оптимизатора, которые не пересекаются с состоянием модели. Например, при использовании параметров модели fp16 распределенный оптимизатор поддерживает свою собственную отдельную копию основных параметров и оценок fp32, которые распределяются по рангам DP. Однако при использовании параметров модели bf16 основные оценки fp32 распределенного оптимизатора такие же, как оценки fp32 модели, и поэтому оценки в этом случае не распределяются (хотя основные параметры fp32 все еще распределяются, поскольку они отделены от параметров bf16). параметры модели).
Теоретическая экономия памяти варьируется в зависимости от комбинации параметра dtype и grad dtype модели. В нашей реализации теоретическое количество байтов на параметр равно (где «d» — размер параллелизма данных):
| Нераспределенный оптим | Распределенная оптимизация | |
|---|---|---|
| Параметр fp16, градация fp16 | 20 | 4 + 16/д |
| параметр bf16, градация fp32 | 18 | 6 + 12/д |
| Параметр fp32, градация fp32 | 16 | 8 + 8/д |
Как и в случае обычного параллелизма данных, перекрытие уменьшения градиента (в данном случае, сокращения-разброса) с обратным проходом можно облегчить с помощью флага --overlap-grad-reduce . Кроме того, перекрытие параметра all-gather может перекрываться с прямым проходом с помощью --overlap-param-gather .
Использование: --use-flash-attn . Поддержите размеры головы внимания не более 128.
FlashAttention — это быстрый и эффективно использующий память алгоритм для точного расчета внимания. Это ускоряет обучение модели и снижает требования к памяти.
Чтобы установить FlashAttention:
pip install flash-attn В examples/gpt3/train_gpt3_175b_distributed.sh мы привели пример того, как настроить Megatron для обучения GPT-3 со 175 миллиардами параметров на 1024 графических процессорах. Скрипт предназначен для работы с плагином pyxis, но его можно легко адаптировать к любому другому планировщику. Он использует 8-канальный тензорный параллелизм и 16-канальный конвейерный параллелизм. При использовании опций global-batch-size 1536 и rampup-batch-size 16 16 5859375 обучение начнется с глобального размера пакета 16 и линейно увеличит размер глобального пакета до 1536 по 5 859 375 выборок с пошаговыми шагами 16. Набор обучающих данных может быть любым: один набор или несколько наборов данных в сочетании с набором весов.
При полном глобальном размере пакета 1536 на 1024 графических процессорах A100 каждая итерация занимает около 32 секунд, что дает 138 терафлопс на один графический процессор, что составляет 44% от теоретического пикового значения флопс.
Retro (Borgeaud et al., 2022) представляет собой авторегрессионную языковую модель только для декодера (LM), предварительно обученную с помощью поискового расширения. Retro обладает практической масштабируемостью для поддержки крупномасштабного предварительного обучения с нуля путем извлечения триллионов токенов. Предварительное обучение с поиском обеспечивает более эффективный механизм хранения фактических знаний по сравнению с неявным хранением фактических знаний в параметрах сети, что значительно снижает параметры модели и одновременно обеспечивает меньшую запутанность, чем стандартный GPT. Retro также обеспечивает гибкость обновления знаний, хранящихся в LM (Wang et al., 2023a), путем обновления базы данных поиска без повторного обучения LM.
InstructRetro (Wang et al., 2023b) дополнительно увеличивает размер Retro до 48B, показывая самый большой LLM, предварительно обученный с помощью извлечения (по состоянию на декабрь 2023 г.). Полученная модель фундамента Retro 48B во многом превосходит GPT-аналог по степени запутанности. Благодаря настройке инструкций Retro InstructRetro демонстрирует значительное улучшение по сравнению с GPT, настроенным на инструкции, для последующих задач в настройке нулевого выстрела. В частности, среднее улучшение InstructRetro составляет 7 % по сравнению с его аналогом GPT при выполнении 8 коротких задач контроля качества и на 10 % по сравнению с GPT при выполнении 4 сложных длинных задач контроля качества. Мы также обнаружили, что можно удалить кодировщик из архитектуры InstructRetro и напрямую использовать магистраль декодера InstructRetro в качестве GPT, достигая при этом сопоставимых результатов.
В этом репозитории мы предоставляем комплексное руководство по воспроизведению Retro и InstructRetro, охватывающее
Подробный обзор см. в Tools/retro/README.md.
Подробнее см. в разделе «Примеры/мамба».
Мы предоставляем несколько аргументов командной строки, подробно описанных в сценариях, перечисленных ниже, для обработки различных нулевых и точно настроенных последующих задач. Однако при желании вы также можете точно настроить свою модель на основе предварительно обученной контрольной точки на других корпусах. Для этого просто добавьте флаг --finetune и настройте входные файлы и параметры обучения в исходном сценарии обучения. Счетчик итераций будет сброшен до нуля, а оптимизатор и внутреннее состояние будут повторно инициализированы. Если точная настройка по какой-либо причине прервана, обязательно снимите флаг --finetune перед продолжением, иначе обучение начнется снова с начала.
Поскольку для оценки требуется значительно меньше памяти, чем для обучения, может быть выгодно объединить модель, обученную параллельно, для использования на меньшем количестве графических процессоров в последующих задачах. Следующий скрипт выполняет это. В этом примере считывается модель GPT с параллелизмом модели 4-стороннего тензора и модели 4-стороннего конвейера и записывается модель с параллелизмом модели 2-стороннего тензора и модели 2-стороннего конвейера.
инструменты Python/контрольная точка/convert.py
--model-type GPT
--load-dir контрольные точки/gpt3_tp4_pp4
--save-dir контрольные точки/gpt3_tp2_pp2
--target-tensor-parallel-size 2
--target-pipeline-parallel-size 2
Ниже описаны несколько последующих задач для моделей GPT и BERT. Их можно запускать в распределенном и моделирующем параллельном режимах с теми же изменениями, что и в сценариях обучения.
Мы включили простой REST-сервер, который можно использовать для генерации текста, в tools/run_text_generation_server.py . Вы запускаете его так же, как если бы вы запускали задание по предварительному обучению, указывая соответствующую предварительно обученную контрольную точку. Есть также несколько дополнительных параметров: temperature , top-k и top-p . См. --help или исходный файл для получения дополнительной информации. См. example/inference/run_text_generation_server_345M.sh для примера того, как запустить сервер.
После запуска сервера вы можете использовать tools/text_generation_cli.py для запроса. Он принимает один аргумент, указывающий хост, на котором работает сервер.
инструменты/text_generation_cli.py локальный хост: 5000
Вы также можете использовать CURL или любые другие инструменты для прямого запроса к серверу:
локон 'http://localhost:5000/api' -X 'PUT' -H 'Тип контента: application/json; charset=UTF-8' -d '{"prompts":["Привет, мир"], "tokens_to_generate":1}'
См. megatron/inference/text_generation_server.py для получения дополнительных опций API.
Мы включаем пример в examples/academic_paper_scripts/detxoify_lm/ для детоксикации языковых моделей за счет использования порождающей силы языковых моделей.
См. example/academic_paper_scripts/detxoify_lm/README.md для получения пошаговых руководств о том, как выполнить адаптивное к предметной области обучение и провести детоксикацию LM с использованием самостоятельно созданного корпуса.
Мы включаем примеры сценариев для оценки GPT при оценке запутанности WikiText и точности LAMBADA Cloze.
Для равномерного сравнения с предыдущими работами мы оцениваем недоумение в тестовом наборе данных WikiText-103 на уровне слов и соответствующим образом вычисляем недоумение с учетом изменения токенов при использовании нашего токенизатора подслов.
Мы используем следующую команду для запуска оценки WikiText-103 для модели параметров 345M.
ЗАДАЧА="ВИКИТЕКСТ103"
VALID_DATA=<путь к викитексту>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=контрольные точки/gpt2_345m
COMMON_TASK_ARGS="--количество слоев 24
--hidden-size 1024
--num-attention-heads 16
--seq-длина 1024
--max-position-embeddings 1024
--fp16
--vocab-файл $VOCAB_FILE"
задачи Python/main.py
--task $TASK
$COMMON_TASK_ARGS
--valid-data $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--merge-файл $MERGE_FILE
--загрузить $CHECKPOINT_PATH
--micro-batch-size 8
--log-интервал 10
--no-load-optim
--no-load-rng
Чтобы вычислить точность замыкания LAMBADA (точность прогнозирования последнего токена с учетом предыдущих токенов) мы используем детокенизированную, обработанную версию набора данных LAMBADA.
Мы используем следующую команду для запуска оценки LAMBADA для модели параметров 345M. Обратите внимание, что флаг --strict-lambada следует использовать, чтобы требовать сопоставления всего слова. Убедитесь, что lambada является частью пути к файлу.
ЗАДАЧА="ЛАМБАДА"
VALID_DATA=<путь лямбада>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=контрольные точки/gpt2_345m
COMMON_TASK_ARGS=<то же самое, что и в «Оценке недоумения WikiText» выше>
задачи Python/main.py
--task $TASK
$COMMON_TASK_ARGS
--valid-data $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--strict-lambada
--merge-файл $MERGE_FILE
--загрузить $CHECKPOINT_PATH
--micro-batch-size 8
--log-интервал 10
--no-load-optim
--no-load-rng
Дальнейшие аргументы командной строки описаны в исходном файле main.py
Следующий скрипт настраивает модель BERT для оценки набора данных RACE. Каталог TRAIN_DATA и VALID_DATA содержит набор данных RACE в виде отдельных файлов .txt . Обратите внимание, что для RACE размер пакета — это количество запросов RACE, которые необходимо оценить. Поскольку каждый запрос RACE содержит четыре выборки, эффективный размер пакета, передаваемый через модель, будет в четыре раза превышать размер пакета, указанный в командной строке.
TRAIN_DATA="данные/ГОНКА/поезд/средний"
VALID_DATA="данные/RACE/dev/middle
данные/RACE/dev/высокий"
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=контрольные точки/bert_345m
CHECKPOINT_PATH=контрольные точки/bert_345m_race
COMMON_TASK_ARGS="--количество слоев 24
--hidden-size 1024
--num-attention-heads 16
--seq-длина 512
--max-position-embeddings 512
--fp16
--vocab-файл $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--train-data $TRAIN_DATA
--valid-data $VALID_DATA
--pretrained-checkpoint $PRETRAINED_CHECKPOINT
--save-interval 10000
--save $CHECKPOINT_PATH
--log-интервал 100
--eval-интервал 1000
--eval-iters 10
--weight-decay 1.0e-1"
задачи Python/main.py
--task ГОНКА
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer-type BertWordPieceLowerCase
--эпохи 3
--micro-batch-size 4
--lr 1.0e-5
--lr-warmup-fraction 0,06
Следующий скрипт настраивает модель BERT для оценки с помощью корпуса пар предложений MultiNLI. Поскольку задачи сопоставления очень похожи, сценарий можно быстро настроить для работы с набором данных Quora Вопросительные пары (QQP).
Train_data = "data/glue_data/mnli/train.tsv"
Valid_data = "data/glue_data/mnli/dev_matched.tsv
DATA/GLUE_DATA/MNLI/DEV_MISMATHED.TSV "
Pretried_checkpoint = контрольные точки/bert_345m
Vocab_file = bert-vocab.txt
CheckPoint_Path = CheckPoints/BERT_345M_MNLI
Common_task_args = <то же самое, что и в оценке расы выше>
Common_task_args_ext = <то же самое, что и в оценке расы выше>
Python Tasks/main.py
-задать mnli
$ Common_task_args
$ Common_task_args_ext
-tokenizer-type bertpieceecelowercase
-Эпоч 5
-Micro-Batch размер 8
--lr 5.0e-5
-LR-Warmup-Fraction 0,065
Семейство моделей Llama-2 представляет собой набор моделей с открытым исходным кодом, предварительно проведенными и созданными (для чата), которые достигли сильных результатов по широкому набору критериев. Во время выпуска модели LLAMA-2, достигнутые среди наилучших результатов для моделей с открытым исходным кодом, и были конкурентоспособны с моделью с закрытым источником GPT-3.5 (см. Https://arxiv.org/pdf/2307.09288.pdf).
Контрольные точки Llama-2 могут быть загружены в Megatron для вывода и создания. Смотрите документацию здесь.
Семейство Megatron-Core (MCORE) GPTModel поддерживает передовые алгоритмы квантования и высокопроизводительный вывод через Tensorrt-LLM.
Посмотрите на оптимизацию и развертывание модели Megatron для примеров llama2 и nemotron3 .
Мы не размещаем какие -либо наборы данных для обучения GPT или BERT, однако мы подробно описываем их коллекцию, чтобы наши результаты могли быть воспроизведены.
Мы рекомендуем следить за процессом извлечения данных в Википедии, указанном в Google Research: «Рекомендуемая предварительная обработка заключается в загрузке последней дампы, извлечь текст с помощью wikiextractor.py, а затем применить любую необходимую очистку для преобразования в простой текст».
Мы рекомендуем использовать аргумент --json при использовании WikiexTractor, который будет выбросить данные Wikipedia в свободный формат JSON (один объект JSON на строку), что делает их более управляемым в файловой системе, а также легко потребляется нашей кодовой базой. Мы рекомендуем дальнейшую предварительную обработку этого набора данных JSON с стандартизацией пунктуации NLTK. Для обучения BERT используйте флаг --split-sentences для preprocess_data.py , как описано выше, чтобы включить разрывы предложений в произведенном индексе. Если вы хотите использовать данные Wikipedia для обучения GPT, вы все равно должны очистить их с помощью NLTK/Spacy/ftfy, но не используйте флаг --split-sentences .
Мы используем общедоступную библиотеку OpenWebText из работы Jcpeterson и Eukaryote31 по загрузке URL. Затем мы отфильтровали, очищаем и дедупликайте все загруженные контенты в соответствии с процедурой, описанной в нашем каталоге OpenWebText. Для URL -адресов Reddit, соответствующих контенту до октября 2018 года, мы достигли приблизительно 37 ГБ контента.
Обучение мегатрона может быть повторно воспроизводимо; Чтобы включить этот режим использования --deterministic-mode . Это означает, что один и тот же тренировочный конфигуратор дважды работает в одной и той же среде HW и SW должен создавать идентичные контрольные точки модели, потери и значения метрики точности (метрики времени итерации могут варьироваться).
В настоящее время существуют три известных оптимизации мегатрона, которые нарушают воспроизводимость, все еще производящие почти идентичные тренировочные прогоны:
NCCL_ALGO ). Мы проверили следующее: ^NVLS , Tree , Ring , CollnetDirect , CollnetChain . Код допускает использование ^NVLS , что позволяет NCCL выбор алгоритмов не-NVLS; Его выбор кажется стабильным.--use-flash-attn .NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 .Кроме того, детерминизим был подтвержден только в контейнерах NGC Pytorch до и новым, чем 23,12. Если вы соблюдаете недерминизм в обучении Мегатрона при других обстоятельствах, пожалуйста, откройте проблему.
Ниже приведены некоторые из проектов, где мы напрямую использовали Megatron:


