tabled
1.0.0
Tabled — небольшая библиотека для обнаружения и извлечения таблиц. Он использует Surya для поиска всех таблиц в PDF-файле, идентифицирует строки/столбцы и форматирует ячейки в Markdown, CSV или html.
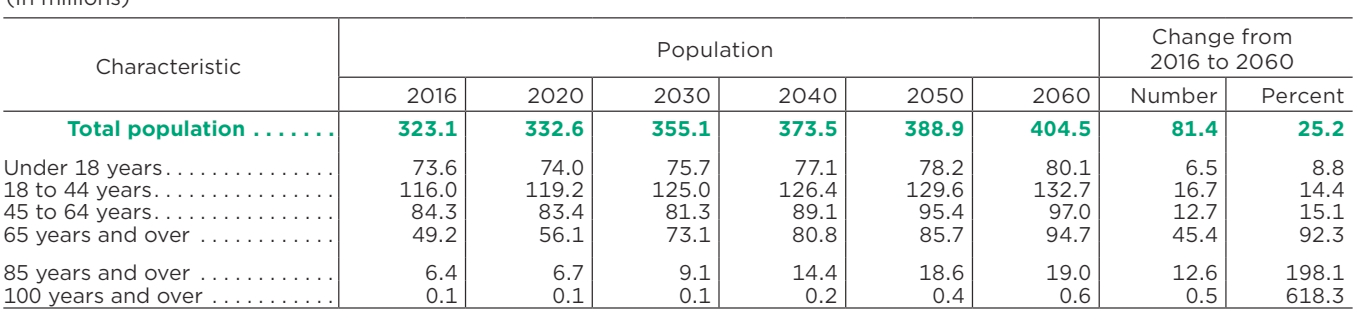
| Характеристика | Население | Изменение с 2016 на 2060 год | ||||||
|---|---|---|---|---|---|---|---|---|
| 2016 год | 2020 год | 2030 год | 2040 год | 2050 год | 2060 год | Число | Процент | |
| Общая численность населения | 323,1 | 332,6 | 355,1 | 373,5 | 388,9 | 404,5 | 81,4 | 25,2 |
| До 18 лет | 73,6 | 74,0 | 75,7 | 77,1 | 78,2 | 80,1 | 6,5 | 8,8 |
| от 18 до 44 лет | 116,0 | 119,2 | 125,0 | 126,4 | 129,6 | 132,7 | 16,7 | 14,4 |
| от 45 до 64 лет | 84,3 | 83,4 | 81,3 | 89,1 | 95,4 | 97,0 | 12,7 | 15.1 |
| 65 лет и старше | 49,2 | 56,1 | 73,1 | 80,8 | 85,7 | 94,7 | 45,4 | 92,3 |
| 85 лет и старше | 6.4 | 6,7 | 9.1 | 14,4 | 18,6 | 19,0 | 12,6 | 198,1 |
| 100 лет и более | 0,1 | 0,1 | 0,1 | 0,2 | 0,4 | 0,6 | 0,5 | 618,3 |
Discord — это место, где мы обсуждаем будущее развитие.
Здесь доступен размещенный API для таблиц:
Работает с PDF, изображениями, документами Word и PowerPoint.
Стабильная скорость без скачков задержки
Высокая надежность и время безотказной работы
Я хочу, чтобы tabled был как можно более широко доступен и при этом финансировал мои расходы на разработку/обучение. Исследования и личное использование всегда допустимы, но существуют некоторые ограничения на коммерческое использование.
Веса для моделей лицензируются cc-by-nc-sa-4.0 , но я откажусь от этого для любой организации с валовым доходом менее 5 миллионов долларов США за последний 12-месячный период И менее 5 миллионов долларов США в течение всей жизни с венчурным капиталом или ангельским финансированием. поднятый. Вы также не должны конкурировать с Datalab API. Если вы хотите отменить требования лицензии GPL (двойная лицензия) и/или использовать веса в коммерческих целях сверх предела дохода, ознакомьтесь с вариантами здесь.
Вам понадобится Python 3.10+ и PyTorch. Возможно, вам придется сначала установить версию torch для ЦП, если вы не используете Mac или компьютер с графическим процессором. Подробнее см. здесь.
Установить с помощью:
pip install в таблице-pdf
После установки:
Проверьте настройки в tabled/settings.py . Вы можете переопределить любые настройки с помощью переменных среды.
Ваш фонарик будет обнаружен автоматически, но вы можете это изменить. Например, TORCH_DEVICE=cuda .
Веса модели будут автоматически загружены при первом запуске таблицы.
внесен в таблицу DATA_PATH
DATA_PATH может быть изображением, PDF-файлом или папкой изображений/pdf-файлов.
--format указывает формат вывода для каждой таблицы ( markdown , html или csv )
--save_json сохраняет дополнительную информацию о строках и столбцах в файле json.
--save_debug_images сохраняет изображения, показывающие обнаруженные строки и столбцы.
--skip_detection означает, что все передаваемые вами изображения представляют собой обрезанные таблицы и не требуют никакого обнаружения таблиц.
--detect_cell_boxes по умолчанию, tabled попытается извлечь информацию о ячейке из PDF-файла. Если вместо этого вы хотите, чтобы ячейки обнаруживались с помощью модели обнаружения, укажите это (обычно это нужно только для PDF-файлов с плохим встроенным текстом).
--save_images указывает, что изображения обнаруженных строк/столбцов и ячеек должны быть сохранены.
После запуска сценария выходной каталог будет содержать папки с теми же базовыми именами, что и имена входных файлов. Внутри этих папок будут файлы уценки для каждой таблицы в исходных документах. Также по желанию будут изображения таблиц.
В корне выходного каталога также будет файл results.json . Файл будет содержать словарь json, где ключами являются имена входных файлов без расширений. Каждое значение будет списком словарей, по одному на каждую таблицу в документе. Каждый табличный словарь содержит:
cells — обнаруженный текст и ограничивающие рамки для каждой ячейки таблицы.
bbox — bbox ячейки внутри таблицы bbox
text - текст ячейки
row_ids — идентификаторы строк, которым принадлежит ячейка
col_ids — идентификаторы столбцов, которым принадлежит ячейка
order - порядок этой ячейки в назначенной ей ячейке строки/столбца. (сортировка по строке, затем по столбцу, затем по порядку)
rows - bbox обнаруженных строк
bbox - bbox строки в формате (x1, x2, y1, y2)
row_id — уникальный идентификатор строки
cols - bbox обнаруженных столбцов
bbox - bbox столбца в формате (x1, x2, y1, y2)
col_id — уникальный идентификатор столбца
image_bbox — bbox для изображения в формате (x1, y1, x2, y2). (x1, y1) — верхний левый угол, а (x2, y2) — нижний правый угол. Таблица bbox относится к этому.
bbox — ограничивающая рамка таблицы внутри изображения bbox.
pnum — номер страницы в документе
tnum — индекс таблицы на странице
Я включил приложение с потоковой подсветкой, которое позволяет вам в интерактивном режиме пробовать таблицы с изображениями или PDF-файлами. Запустите его с помощью:
pip installstreamlit tabled_gui
from tabled.extract import extract_tablesfrom tabled.fileinput import load_pdfs_imagesfrom tabled.inference.models import load_detection_models, load_recognition_modelsdet_models, Rec_models = load_detection_models(), load_recognition_models()images, highres_images, name, text_lines = load_pdfs_images(IN_PATH)page_results = extract_tables(images, highres_images, text_lines, det_models, Rec_models)
| Средний балл | Время за столом | Всего таблиц |
|---|---|---|
| 0,847 | 0,029 | 688 |
Получить достоверные данные для таблиц сложно, поскольку вы либо ограничены простыми макетами, которые можно эвристически проанализировать и отобразить, либо вам нужно использовать LLM, которые допускают ошибки. Я решил использовать предсказания таблицы GPT-4 в качестве псевдо-истины.
Tabled получает оценку выравнивания .847 по сравнению с GPT-4, что указывает на выравнивание текста в строках/ячейках таблицы. Некоторые несовпадения происходят из-за ошибок GPT-4 или небольших несоответствий в том, что GPT-4 считает границами таблицы. В целом качество экстракции достаточно высокое.
При работе на A10G с использованием 10 ГБ видеопамяти и размером пакета 64 обработка таблиц занимает .029 секунды на таблицу.
Запустите тест с помощью:
тесты Python/benchmark.py out.json
Спасибо Питеру Янсену за набор данных для сравнительного анализа и за обсуждение анализа таблиц.
Huggingface для кода вывода и хостинга моделей
PyTorch для обучения/вывода


