Авторы: Букянь Чжэн (buqianz) и Юнкан Хуан (yongkan1)
Плакат
Мы внедрили Corgy, среду глубокого обучения на Swift и Metal. Corgy можно встроить в приложения как для macOS, так и для iOS, а также использовать для создания обученных нейронных сетей и их простой оценки. Мы добились более чем 60-кратного ускорения на разных устройствах с разными графическими процессорами.

Платформа Metal 2 — это интерфейс, предоставляемый Apple, который обеспечивает практически прямой доступ к графическому процессору (GPU) на iPhone/iPad и Mac. Помимо графики, Metal 2 включает в себя множество библиотек, которые обеспечивают отличную поддержку распараллеливания необходимых операций линейной алгебры и функций обработки сигналов, которые могут работать на различных типах устройств Apple. Эти библиотеки позволили нам построить хорошо реализованные модели глубокого обучения с ускорением на графическом процессоре на устройствах iOS на основе обученной модели, предоставленной другими платформами. 1
Вообще говоря, этап вывода обученной нейронной сети очень интенсивен в вычислениях, особенно для тех моделей, которые имеют значительно большое количество слоев или применяются в сценариях, необходимых для обработки изображений высокого разрешения. Стоит отметить, что существует огромное количество матричных вычислений (например, сверточного слоя) , которые подходят для применения распараллеленных операций для оптимизации производительности.
Первая задача, с которой мы столкнулись, — это разработать хорошую абстракцию интерфейса прикладного программирования, который был бы выразительным, простым в использовании и не требующим особого обучения, который был бы удобен для наших пользователей.
В течение всего процесса разработки мы старались сделать публичный API максимально простым, сохраняя при этом все необходимые свойства для создания каждого требуемого компонента, используя механизм функционального программирования, предоставляемый Swift. Мы также намеренно скрыли ненужную аппаратную абстракцию, предоставляемую Metal, чтобы сгладить кривую обучения.
Хотя обученную модель различных сетей легко получить в Интернете, неоднородность между ними, вызванная разной реализацией с применением различных инструментов, побудила к созданию универсального импортера моделей.
Некоторые вычисления легко понять по своей концепции, но они требуют внимательного размышления, если вы хотите создать эффективную реализацию путем их абстрагирования. Свертка является показательным примером.
Внутреннее свойство операции свертки не имеет хорошей локальности, стандартная реализация сложна для понимания и неэффективна со сложными циклами for. Кроме того, нам необходимо учитывать абстракцию, предоставляемую Metal 2, и создать удобный способ обмена необходимой информацией и структурами данных между хостом и устройством с тщательным учетом представления данных и структуры памяти.
На этапе разработки мы добросовестно относимся к возможности нашего кода нормально работать на macOS и iOS без ущерба для производительности на обеих платформах. Мы старались изо всех сил поддерживать библиотеку кода, способную компилироваться и выполняться на обеих платформах. Мы стараемся максимизировать общий код для разных целей и максимально повторно использовать его.
Поскольку полностью реализованный компонент уровня нейронной сети должен обеспечивать поддержку разумного количества параметров, делающих компонент достаточно удобным для использования, сложность компонентов на самом деле весьма впечатляет. Например, сверточный слой должен поддерживать параметры, включающие заполнение, шаг расширения и т. д., и все их следует тщательно учитывать при выполнении распараллеливания, обеспечивающего разумную производительность. Мы построили несколько простых сетей для проведения регрессионного теста. Тестовые случаи создаются в других средах (в первую очередь PyTorch и Keras), чтобы убедиться, что вся реализация работает правильно.
Swift был впервые разработан в июле 2010 года, а опубликован и открыт в 2014 году. Хотя с момента публикации прошло почти 4 года, отсутствие эффективной библиотеки по-прежнему остается серьезной проблемой. Какая-то причина вызвала эту ситуацию, причиной этого явления могла быть доминирующая роль Apple и быстрая итеративность Swift. Некоторые библиотеки, которые имеют решающее значение для нас, либо недостаточно мощны или функциональны для наших нужд, либо плохо поддерживаются отдельными разработчиками, которые их изобрели. Мы потратили довольно много времени, чтобы реализовать хорошо функционирующий тензорный класс Variable для наших требований.
Кроме того, это еще одна причина, препятствующая разработке универсального анализатора модели, заключается в том, что функция обработки файлов и строк имеет очень ограниченные возможности.
Кроме того, инструменты разработки и отладки в основном ограничены Xcode, хотя есть и другие варианты, более общие для нас, Xcode по-прежнему остается де-факто стандартным инструментом для нашей разработки.
Что касается настройки производительности мобильных устройств, Apple не предоставляет подробную спецификацию оборудования для своей SoC, маркетинговое название широко используется в средствах массовой информации, и трудно сделать вывод о том, каково точное влияние конкретной аппаратной функции и точной настройки производительности реализации. .
Мы используем язык программирования Swift, в частности Swift 4.2, который на данный момент является последней версией; Платформа Metal 2 и некоторые библиотечные функции, предоставляемые Metal Performance Shader (в основном функции линейной алгебры). Хотя Apple выпустила CoreML SDK весной 2017 года, который включает некоторую поддержку сверточной нейронной сети, мы не используем их в Corgy, чтобы получить бесценный опыт разработки параллельной реализации сетевых уровней и предоставить краткие и интуитивно понятные API с хорошим удобством использования и плавной кривой обучения. чтобы пользователи могли легко перенести модель из других платформ.
Наши целевые машины — это все устройства под управлением macOS и iOS, такие как iMac, MacBook, iPhone и iPad. В частности, устройство с платформой, поддерживающей библиотеку линейной алгебры MPS (т. е. после iOS 10.0 и macOS 10.13), что означает, что iPhone выпущен после iPhone 5, iPad выпущен после iPad (4-го поколения) и iPod Touch (6-го поколения). поддерживаются как платформа iOS. Линейка продуктов Mac получает еще более широкий охват, включая iMac, выпущенный после конца 2009 года или позже, все серии MacBook, выпущенные после середины 2010 года, и iMac Pro.
Параллельная абстракция Metal 2 очень похожа на CUDA: при отправке передачи компьютера на графический процессор программисты сначала пишут функции ядра, которые будут выполняться каждым потоком, затем указывают количество групп потоков (также известных как блок в CUDA) в сетке и количество потоков в каждой группе потоков, Metal будет выполнять ядра в этой сетке, ядро реализовано на диалекте C++ 14, называемом языком шейдинга Metal. Внутри каждой группы потоков есть меньшая единица, называемая группой SIMD, которая означает группу потоков, которые используют одни и те же инструкции SIMD. Но при нашей реализации нет необходимости это учитывать.
Metal предоставляет API под названием MTLCommandBuffer, который хранит закодированные команды, которые фиксируются и выполняются графическим процессором. Каждый раз, когда мы хотим запустить задачу, которую должен выполнить графический процессор, предварительно скомпилированные функции ядра будут закодированы в инструкции графического процессора, встроены в конвейер металлического затенения и отправлены в MTLCommandBuffer. На этом этапе также задается металлический буфер, используемый для хранения вычислительного параметра, который необходимо передать устройству. Затем при указанном количестве групп потоков и потоков на группу команда, обрабатываемая буфером команд, будет полностью закодирована и настроена для фиксации на устройстве. Графический процессор запланирует задачу и уведомит поток ЦП, который отправляет работу после завершения выполнения.
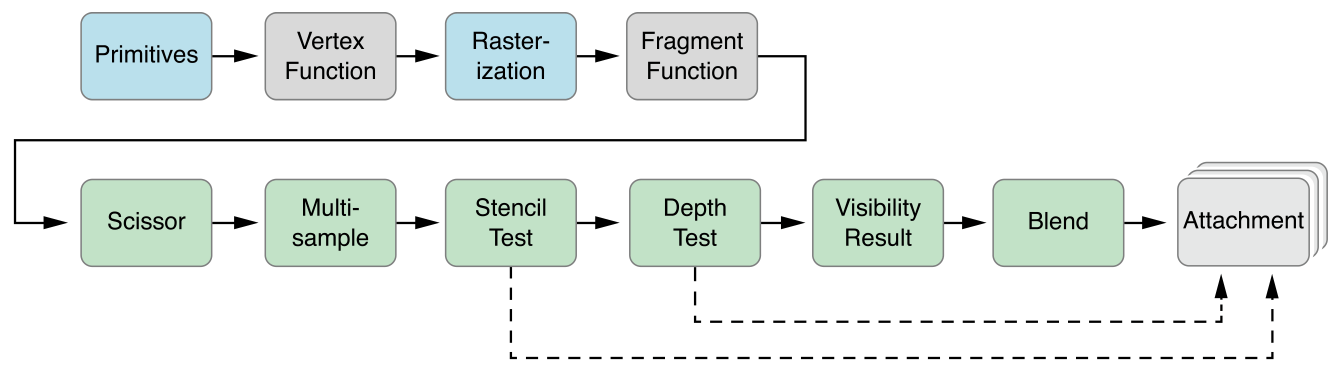
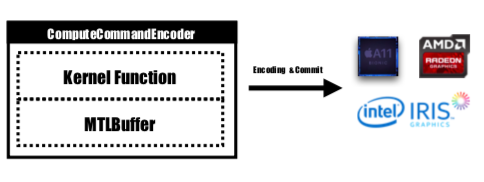
Функция ядра будет закодирована MTLComputeCommandEncoder , и задача будет создана для всех поддерживаемых платформ.
В нашей реализации мы широко использовали интуитивный способ сопоставления элемента с потоками графического процессора: сопоставляем каждый элемент выходного тензора текущего слоя с одним потоком графического процессора: каждый поток вычисляет и обновляет ровно один элемент выходных данных, а входные данные будут только для чтения, поэтому нам не нужно беспокоиться о синхронизации между потоками. При таком сопоставлении потоки с непрерывными идентификаторами могут считывать входные данные из разных ячеек памяти, но всегда будут записывать в непрерывные ячейки памяти. Таким образом, при записи SIMD-группы в память не будет операций разброса.
Мы разработали тензорный класс Variable в качестве основы всей реализации. Мы использовали и инкапсулировали операцию линейной алгебры в класс Variable вместо написания дополнительного ядра для глубокого погружения в операцию, которая не является нашей основной целью, чтобы уменьшить сложность реализации. и экономим время, чтобы сосредоточиться на ускорении сетевых уровней.
1. Замените свертку на умножение гигантских матриц.
Мы собираем входные данные параллельным образом, чтобы сформировать гигантскую матрицу как входной переменной, так и веса. Мы кэшируем вес каждого сверточного слоя, чтобы избежать перерасчета. Заполнение сверточного слоя будет генерироваться во время преобразования распараллеливания во время расчета, затем мы вызываем MPSMatrixMultiply к гигантской матрице и преобразуем данные из гигантской матрицы обратно в созданный нами обычный тензорный класс. Метод описан на слайдах занятий.
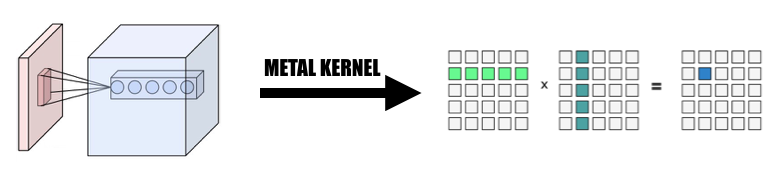
2. Проектирование и реализация класса Variable.
Класс переменных является основой нашей реализации в качестве тензорного представления. Мы инкапсулировали MPSMatrixMultiplication для переменной (определите знак умножения Юникода (×) как инфиксный оператор, чтобы представить его элегантно :-)).
Базовой структурой данных переменной является UnsafemutableBufferPointer , указывающий на тип данных. Для простоты мы выбрали 32-битное число с плавающей запятой. Класс Variable поддерживает два размера данных: count содержит номер элемента, который фактически сохранен, actualCount — это размер всех элементов, округленный до размера страницы платформы, полученный с помощью getpagesize() .
Мы сохраняем эти два значения, чтобы гарантировать, что makeBuffer(bytesNoCopy:) создаст буфер непосредственно в указанном регионе виртуальной машины и избежит избыточного перераспределения, которое снижает накладные расходы. Если память, передаваемая в Metal, не выровнена по страницам, то Metal не сможет использовать эту память в качестве входного или выходного буфера. Нам придется использовать метод makeBuffer(bytes:) , который создаст новый буфер и скопирует данные из входной ячейки памяти. Поэтому нам всегда нужно выделять больше памяти, чем необходимо, чтобы убедиться, что все воспоминания в Variable выровнены по страницам. Поэтому нам нужны два значения, чтобы отслеживать, насколько велик этот фрагмент памяти и какой размер мы должны использовать.
3. Количество элементов, обработанных одним потоком.
Мы попробовали сопоставить один поток с несколькими элементами, от 2 до 16 элементов на поток, производительность почти такая же, но нашему проекту добавляется большая сложность, поэтому мы отказались от этого подхода.
Все упомянутые ниже версии ЦП представляют собой простой однопоточный код ЦП без оптимизации SIMD. Применена оптимизация компилятора на уровне -Ofast .
Производительность нашей реализации хорошая, но не недостаточно хорошая.
В качестве тестовой платформы мы использовали iPhone 6s и 15-дюймовый MacBook Pro. Аппаратное обеспечение указано ниже:
MacBook Pro (15 дюймов Retina, середина 2015 г.)
айфон 6С
По сравнению с простой реализацией версии ЦП без параллелизма наша версия с графическим процессором более чем в 60 раз быстрее .
Поскольку модель MNIST слишком мала, ее результат может не отражать точное ускорение. И у нас нет хорошо реализованной однопоточной версии, мы не можем назвать точные цифры ускорения. Поскольку версия ЦП слишком медленная, ускорение Tiny YOLO слишком велико, чтобы в это поверить.
Атрибут сети эксперимента:
МНИСТ:
ЙОЛО:
Результат измерения:
| айфон 6с | МНИСТ | Крошечный ЙОЛО |
|---|---|---|
| Процессор | 1500 мс | 753-е |
| графический процессор | 0,025 с | 0,5 с |
| ускориться | ~60x | ~1500x |
| Макбук про | МНИСТ | Крошечный ЙОЛО |
|---|---|---|
| Процессор | 650 мс | 729-е |
| графический процессор | 10 мс | 0,028 с |
| ускориться | ~65x | ~26000x |
Основываясь на приведенном выше тесте, мы видим, что по мере увеличения размера проблемы
Почему мы говорим, что наше ускорение недостаточно хорошее? Потому что по сравнению с официальной реализацией MPSCNNConvolution от Apple наша скорость составляет всего лишь около трети, а это означает, что еще есть много возможностей для оптимизации. Это сравнение основано на реализации YOLO с открытым исходным кодом на iPhone с использованием официального MPSCNNConvolution , который может распознавать ~5 изображений в секунду, тогда как наша реализация может достигать только ~2 изображений в секунду.
И из-за ограниченного времени мы не смогли создать лучшую базовую версию и версию с параллельным процессором для проведения теста, что делает число ускорений слишком большим.
Также стоит сообщить о приросте производительности при различных размерах задач. Как мы видим, у MNIST всего 0,1 миллиона весов, а у Tiny YOLO — 17 миллионов. Tiny YOLO намного сложнее, чем MNIST, но время работы версии с графическим процессором не сильно масштабировалось. Это опять же из-за закона Амдала. При каждом запуске задачи графического процессора соответствующие команды графического процессора необходимо закодировать в буфер команд. Этот процесс по своей сути серийный. Когда размер задачи невелик, этот процесс вносит большой вклад в общее время выполнения, поэтому за счет распараллеливания этапа вывода нейронной сети в MINST можно не получить такого же ускорения, как в Tiny YOLO, где накладные расходы на время выполнения незначительны.
Что ограничивало ваше ускорение?
if и for , которые могут вызвать расхождение, что приводит к плохому использованию SIMD.Более глубокий анализ: разбивка времени выполнения различных этапов.
Возьмем, к примеру, Tiny YOLO: в примере запуска с общим временем работы 227 мс на Macbook сверточные слои использовали 207 мс, что составляет 92% от общего времени работы. Слои объединения использовали 14 мс (6%), а ReLU — 6 мс (2%). Согласно закону Амдала, если мы хотим еще больше улучшить производительность, нам обязательно следует продолжать работу над сверточным слоем.
В целом, мы считаем, что наш выбор платформы Metal для ускорения нейронных сетей на устройствах iOS и macOS является правильным, особенно для устройств iOS. Поскольку у него меньше ядер, даже с инструкциями SIMD, хорошо настроенная версия ЦП с меньшей вероятностью будет иметь такую же производительность, как версия графического процессора.
Оба члена команды выполняют одинаковую работу.
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


