Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript ?BrowserВеб-скрапинг большинства веб-сайтов может быть сравнительно простым. Эта тема уже подробно рассмотрена в этом уроке. Однако существует множество сайтов, которые нельзя очистить одним и тем же методом. Причина в том, что эти сайты динамически загружают контент с помощью JavaScript.
Этот метод также известен как AJAX (асинхронный JavaScript и XML). Исторически этот стандарт включал создание объекта XMLHttpRequest для получения XML с веб-сервера без перезагрузки всей страницы. В наши дни этот объект редко используется напрямую. Обычно для получения содержимого, например JSON, частичного HTML или даже изображений, используется оболочка, такая как jQuery.
Для парсинга обычной веб-страницы необходимы как минимум две библиотеки. Библиотека requests загружает страницу. Как только эта страница станет доступна в виде строки HTML, следующим шагом будет ее анализ как объекта BeautifulSoup. Этот объект BeautifulSoup затем можно использовать для поиска конкретных данных.
Вот простой пример скрипта, который печатает текст внутри элемента h1 с id , установленным в firstHeading .
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert EinsteinОбратите внимание, что мы работаем с 4-й версией библиотеки Beautiful Soup. Более ранние версии сняты с производства. Вы можете увидеть, что Beautiful Soup 4 пишется просто как Beautiful Soup, BeautifulSoup или даже bs4. Все они относятся к одной и той же прекрасной библиотеке супа 4.
Тот же код не будет работать, если сайт динамический. Например, тот же сайт имеет динамическую версию https://quotes.toscrape.com/js/ (обратите внимание на js в конце этого URL).
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output Причина в том, что второй сайт является динамическим, где данные генерируются с помощью JavaScript .
Есть два способа работы с такими сайтами.
Эти два подхода подробно рассматриваются в этом руководстве.
Однако сначала нам нужно понять, как определить, является ли сайт динамическим.
Вот самый простой способ определить, является ли веб-сайт динамическим, с помощью Chrome или Edge. (Оба этих браузера используют Chromium под капотом).
Откройте Инструменты разработчика, нажав клавишу F12 . Убедитесь, что фокус находится на инструментах разработчика, и нажмите комбинацию клавиш CTRL+SHIFT+P чтобы открыть командное меню.
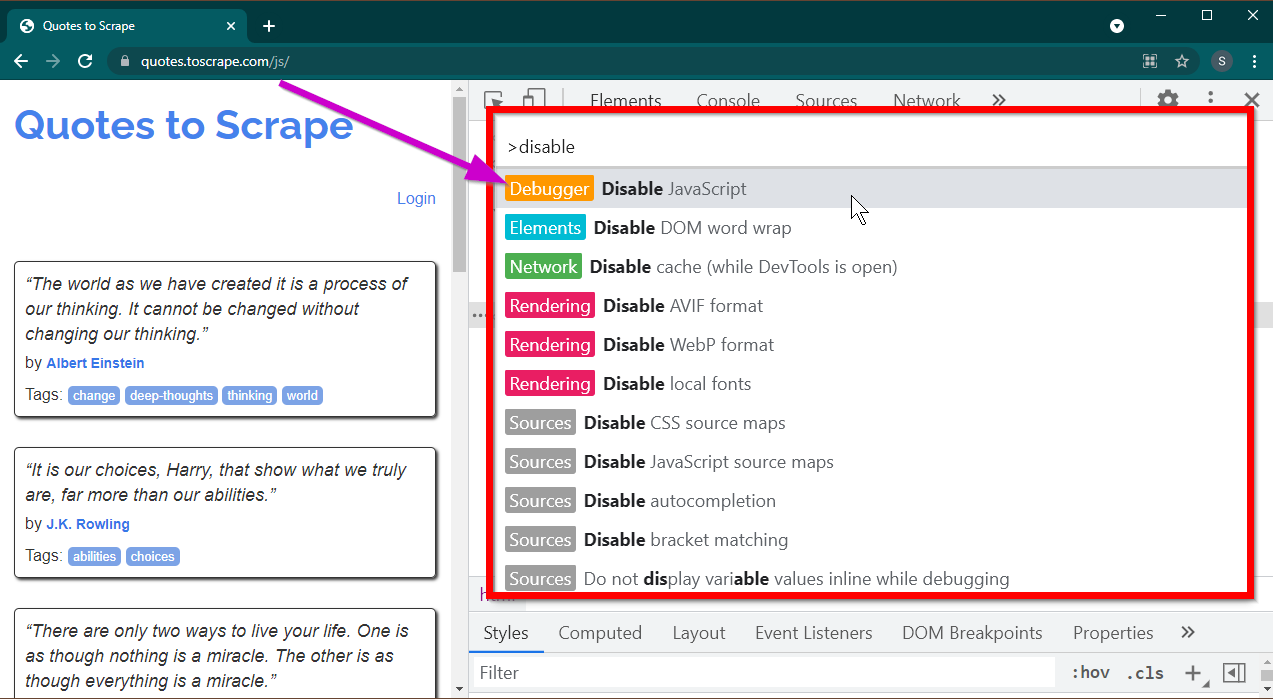
Он покажет много команд. Начните вводить disable , и команды будут отфильтрованы для отображения Disable JavaScript . Выберите эту опцию, чтобы отключить JavaScript .
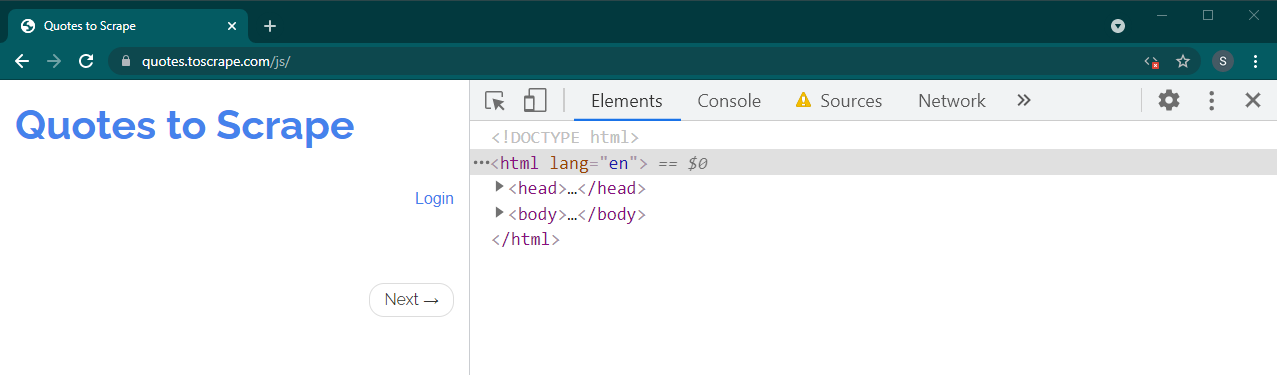
Теперь перезагрузите эту страницу, нажав Ctrl+R или F5 . Страница перезагрузится.
Если это динамический сайт, большая часть контента исчезнет:
В некоторых случаях сайты по-прежнему будут отображать данные, но вернутся к базовым функциям. Например, на этом сайте есть бесконечная прокрутка. Если JavaScript отключен, отображается обычная нумерация страниц.
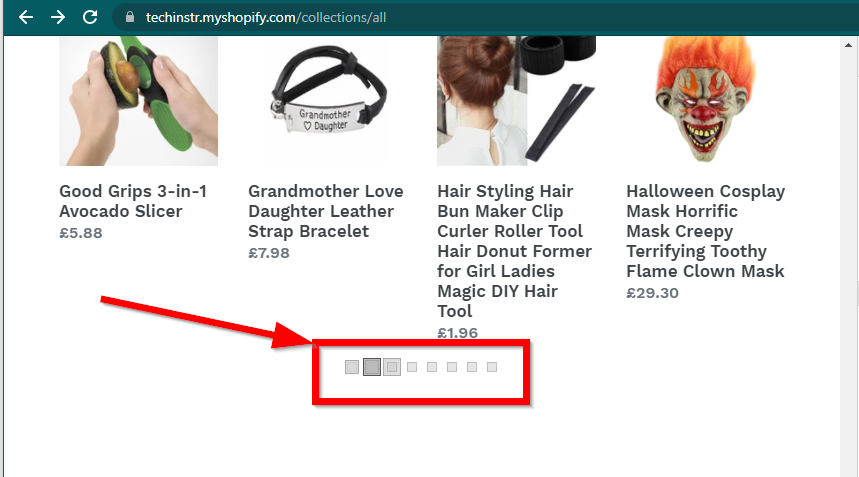 | 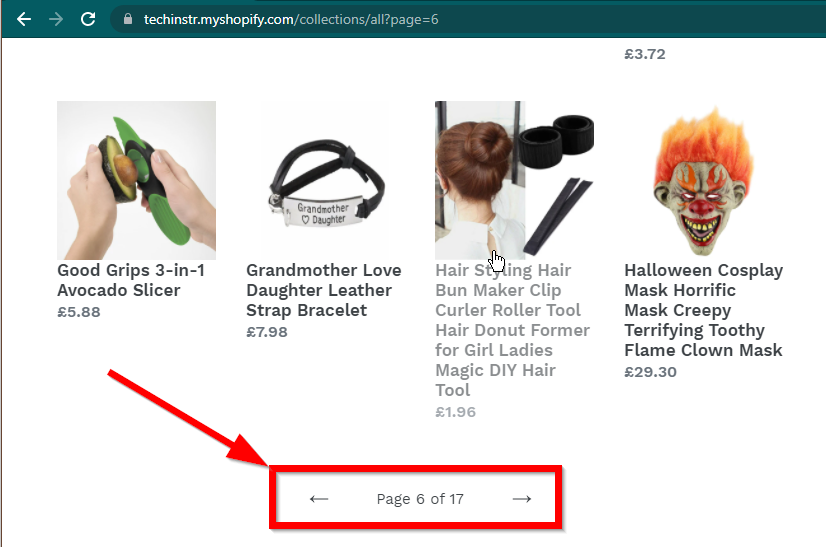 |
|---|---|
| JavaScript включен | JavaScript отключен |
Следующий вопрос, на который необходимо ответить, — это возможности BeautifulSoup.
JavaScript ?Короткий ответ: нет.
Важно понимать такие слова, как синтаксический анализ и рендеринг. Синтаксический анализ — это просто преобразование строкового представления объекта Python в реальный объект.
Так что же такое рендеринг? Рендеринг — это, по сути, интерпретация HTML, JavaScript, CSS и изображений во что-то, что мы видим в браузере.
Beautiful Soup — это библиотека Python для извлечения данных из файлов HTML. Это включает в себя анализ строки HTML в объект BeautifulSoup. Для синтаксического анализа нам сначала нужен HTML как строка. Динамические веб-сайты не содержат данных напрямую в HTML. Это означает, что BeautifulSoup не может работать с динамическими веб-сайтами.
Библиотека Selenium может автоматизировать загрузку и отображение веб-сайтов в браузере, таком как Chrome или Firefox. Несмотря на то, что Selenium поддерживает извлечение данных из HTML, можно извлечь полный HTML и вместо этого использовать Beautiful Soup для извлечения данных.
Давайте сначала начнем динамический парсинг веб-страниц с помощью Python, используя Selenium.
Установка Selenium включает в себя установку трёх вещей:
Браузер по вашему выбору (который у вас уже есть):
Драйвер для вашего браузера:
Пакет Python Selenium:
pip install seleniumconda-forge . conda install -c conda-forge selenium Базовый скелет скрипта Python для запуска браузера, загрузки страницы и последующего закрытия браузера прост:
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()Теперь, когда мы можем загрузить страницу в браузере, давайте рассмотрим извлечение конкретных элементов. Есть два способа извлечения элементов: селен и красивый суп.
Наша цель в этом примере — найти элемент автора.
Загрузите сайт https://quotes.toscrape.com/js/ в Chrome, щелкните правой кнопкой мыши имя автора и выберите «Проверить». Это должно загрузить инструменты разработчика с выделенным элементом автора следующим образом:
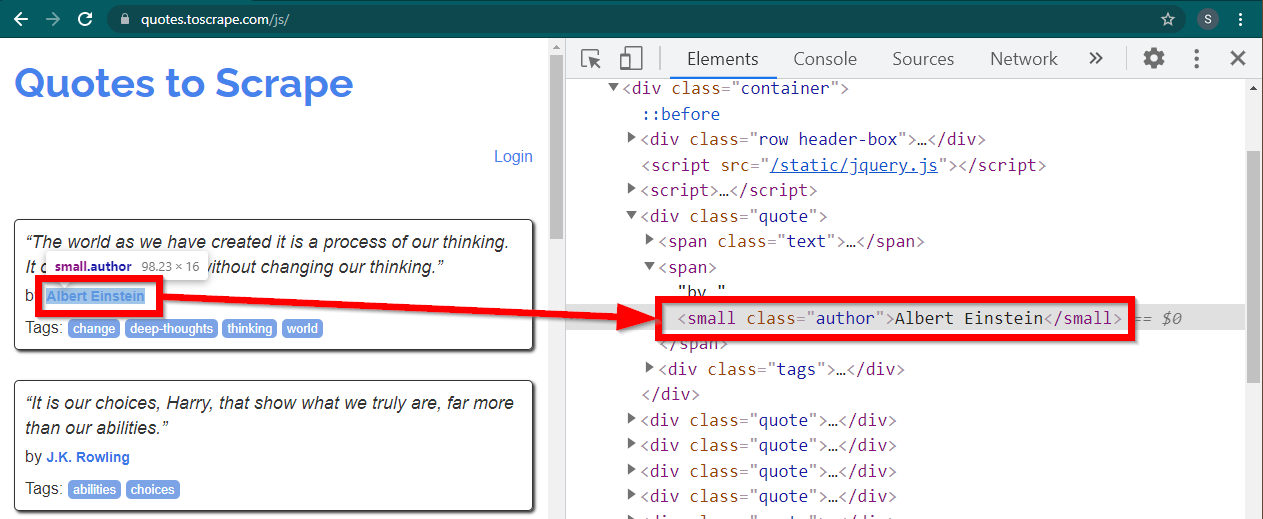
Это small элемент с атрибутом class установленным на author .
< small class =" author " > Albert Einstein </ small >Selenium позволяет использовать различные методы для поиска элементов HTML. Эти методы являются частью объекта драйвера. Некоторые из методов, которые могут быть здесь полезны, следующие:
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )Есть несколько других методов, которые могут быть полезны для других сценариев. Эти методы заключаются в следующем:
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" ) Возможно, наиболее полезными методами являются find_element(By.CSS_SELECTOR) и find_element(By.XPATH) . Любой из этих двух методов должен позволять выбирать большинство сценариев.
Давайте изменим код так, чтобы можно было вывести первого автора.
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()Что делать, если вы хотите напечатать всех авторов?
У всех методов find_element есть аналог — find_elements . Обратите внимание на множественное число. Чтобы найти всех авторов, просто измените одну строку:
elements = driver . find_elements ( By . CLASS_NAME , "author" )Это возвращает список элементов. Мы можем просто запустить цикл, чтобы напечатать всех авторов:
for element in elements :
print ( element . text )Примечание. Полный код находится в файле кода selenium_example.py.
Однако, если вы уже знакомы с BeautifulSoup, вы можете создать объект Beautiful Soup.
Как мы видели в первом примере, объекту Beautiful Soup нужен HTML. Для очистки статических сайтов HTML можно получить с помощью библиотеки requests . Следующий шаг — синтаксический анализ этой HTML-строки в объект BeautifulSoup.
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )Давайте узнаем, как очистить динамический веб-сайт с помощью BeautifulSoup.
Следующая часть остается неизменной по сравнению с предыдущим примером.
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' ) Отрисованный HTML-код страницы доступен в атрибуте page_source .
soup = BeautifulSoup ( driver . page_source , "lxml" )Как только объект супа станет доступен, все методы Beautiful Soup можно будет использовать как обычно.
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )Примечание. Полный исходный код находится в selenium_bs4.py.
BrowserКогда сценарий готов, нет необходимости, чтобы браузер был виден во время выполнения сценария. Браузер можно скрыть, а скрипт все равно будет работать нормально. Такое поведение браузера также известно как «безголовый» браузер.
Чтобы сделать браузер безгласным, импортируйте ChromeOptions . Для других браузеров доступны собственные классы параметров.
from selenium . webdriver import ChromeOptions Теперь создайте объект этого класса и установите для атрибута headless значение True.
options = ChromeOptions ()
options . headless = TrueНаконец, отправьте этот объект при создании экземпляра Chrome.
driver = Chrome ( ChromeDriverManager (). install (), options = options )Теперь при запуске скрипта браузер не будет виден. Полную реализацию смотрите в файле selenium_bs4_headless.py.
Загрузка браузера обходится дорого — она отнимает ресурсы ЦП, ОЗУ и пропускную способность, которые на самом деле не нужны. Когда веб-сайт парсится, важны именно данные. Все эти CSS, изображения и рендеринг на самом деле не нужны.
Самый быстрый и эффективный способ очистки динамических веб-страниц с помощью Python — найти фактическое место, где находятся данные.
Есть два места, где эти данные могут быть расположены:
<script> .Давайте рассмотрим несколько примеров.
Откройте https://quotes.toscrape.com/js в Chrome. После загрузки страницы нажмите Ctrl+U, чтобы просмотреть исходный код. Нажмите Ctrl+F, чтобы открыть окно поиска, найдите Альберта.
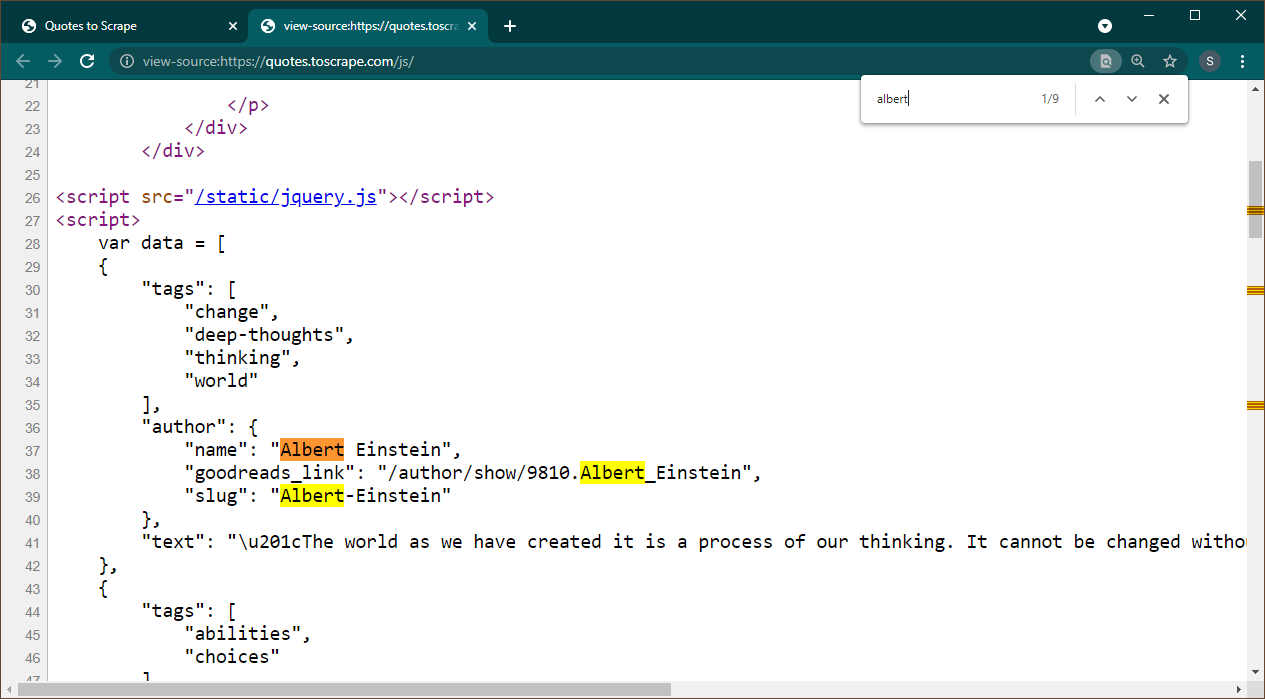
Мы сразу видим, что данные внедрены на страницу в виде объекта JSON. Также обратите внимание, что это часть сценария, в котором эти данные присваиваются переменной data .
В этом случае мы можем использовать библиотеку Requests для получения страницы и использовать Beautiful Soup для анализа страницы и получения элемента сценария.
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" ) Обратите внимание, что существует несколько элементов <script> . Тот, который содержит нужные нам данные, не имеет атрибута src . Давайте используем это для извлечения элемента сценария.
script_tag = soup . find ( "script" , src = None )Помните, что этот скрипт содержит другой код JavaScript, помимо интересующих нас данных. По этой причине мы собираемся использовать регулярное выражение для извлечения этих данных.
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )Переменная данных представляет собой список, содержащий один элемент. Теперь мы можем использовать библиотеку JSON для преобразования этих строковых данных в объект Python.
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )Результатом будет объект Python:
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................Этот список невозможно преобразовать в любой требуемый формат. Также обратите внимание, что каждый элемент содержит ссылку на страницу автора. Это означает, что вы можете прочитать эти ссылки и создать паука, который будет получать данные со всех этих страниц.
Этот полный код включен в data_in_same_page.py.
Парсинг динамических сайтов может пойти совершенно другим путем. Иногда данные загружаются вообще на отдельной странице. Одним из таких примеров является Либривокс.
Откройте Инструменты разработчика, перейдите на вкладку «Сеть» и отфильтруйте по XHR. Теперь откройте эту ссылку или найдите любую книгу. Вы увидите, что данные представляют собой HTML-код, встроенный в JSON.
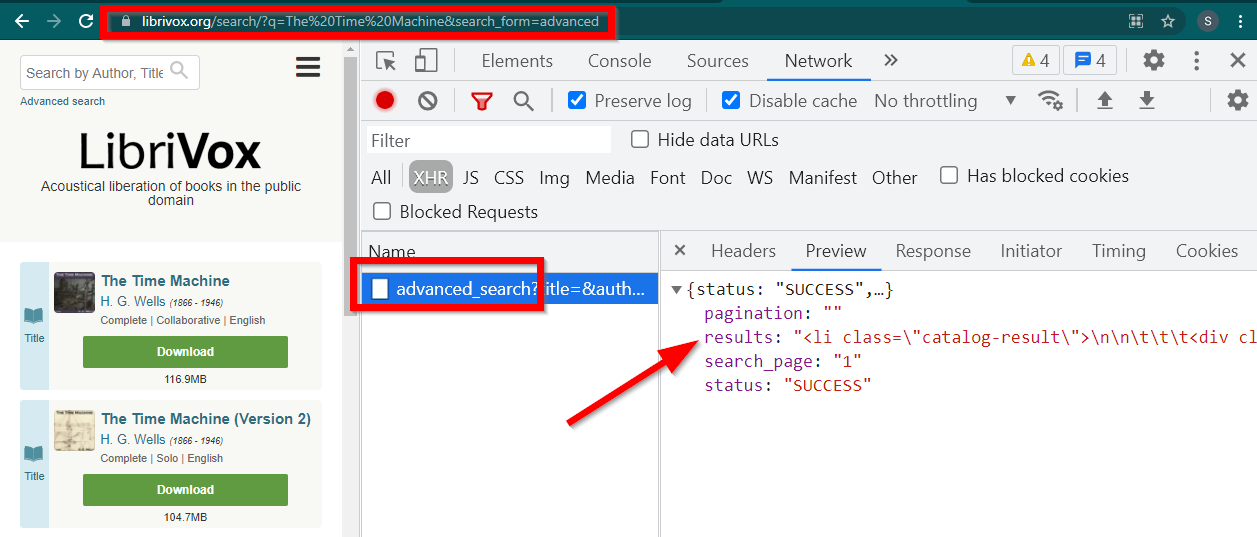
Обратите внимание на несколько вещей:
URL-адрес, отображаемый браузером https://librivox.org/search/?q=...
Данные находятся в https://librivox.org/advanced_search?....
Если вы посмотрите на заголовки, то обнаружите, что странице Advanced_search отправляется специальный заголовок X-Requested-With: XMLHttpRequest
Вот фрагмент для извлечения этих данных:
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )Полный код включен в файл librivox.py.


