disclosure backend static
1.0.0
disclosure-backend-static — это серверная часть Open Disclosure California.
Он был создан в спешке накануне выборов 2016 года и, таким образом, построен на основе философии «сделай это». На тот момент мы уже разработали API и построили (большую часть) интерфейс; этот репозиторий был создан для того, чтобы реализовать их как можно быстрее.
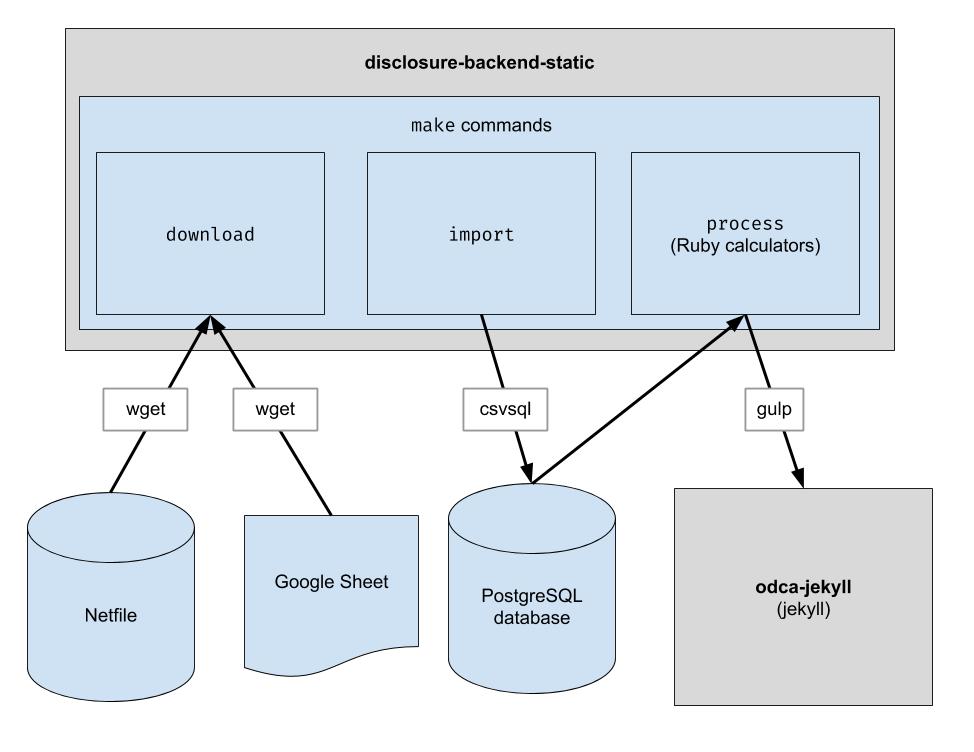
В этом проекте реализуется базовый конвейер ETL для загрузки данных сетевого файла Окленда, загрузки данных CSV, созданных человеком, для Окленда и их объединения. Результатом является каталог файлов JSON, которые имитируют существующую структуру API, поэтому никаких изменений клиентского кода не требуется.
.ruby-version ) Примечание. Вам не нужно запускать эти команды для разработки во внешнем интерфейсе. Все, что вам нужно сделать, это клонировать репозиторий рядом с репозиторием внешнего интерфейса.
Если вы планируете изменить внутренний код, выполните следующие действия, чтобы настроить все необходимые зависимости для разработки, включая новую базу данных PostgreSQL и Python 3:
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip вместо pip , чтобы гарантировать использование Python 3: python3 -m pip install ...
pip вашей системы указывает на Python 3, вы можете использовать pip напрямую: pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
Этот репозиторий настроен для работы в контейнере Codespaces. Другими словами, вы можете запустить уже настроенную среду без необходимости выполнять какие-либо шаги по установке, необходимые для настройки локальной среды. Это можно использовать как способ устранения неполадок кода перед его передачей в производственный конвейер. Следующая информация может быть полезна для начала использования Codespaces:
Code и выберите вкладку Codespaces в раскрывающемся списке./workspace , которое будет выглядеть знакомо, если вы раньше работали с VS Code.make downloadpsql в терминале для подключения к серверу.make import заполнит базу данных Postgres.git pushЭтот репозиторий также настроен для работы в контейнере Docker. Это похоже на Codespaces, за исключением того, что вы можете использовать любую IDE и локальную настройку по своему усмотрению. Вот как начать использовать Docker с VSCode:
Загрузите файлы необработанных данных. Вам нужно запускать это только время от времени, чтобы получать последние данные.
$ make download
Импортируйте данные в базу данных для упрощения обработки. Вам нужно запустить это только после загрузки новых данных.
$ make import
Запустите калькуляторы. Все выводится в папку «build».
$ make process
При желании переиндексируйте результаты сборки в Algolia. (Для переиндексации требуются переменные среды ALGOLIASEARCH_APPLICATION_ID и ALGOLIASEARCH_API_KEY).
$ make reindex
Если вы хотите передавать статические файлы JSON через локальный веб-сервер:
$ make run
При запуске make import создается несколько таблиц postgres для импорта загруженных данных. Схема этих таблиц явно определена в каталоге dbschema , и в будущем ее, возможно, придется обновить для размещения будущих данных. Столбцы, содержащие строковые данные, могут иметь недостаточный размер для будущих данных. Например, если столбец имени принимает имена длиной не более 20 символов и в будущем у нас появятся данные, в которых длина имени будет 21 символ, импорт данных завершится неудачно. В этом случае нам придется обновить соответствующий файл схемы в dbschema чтобы он поддерживал больше символов. Просто внесите изменения и повторно запустите make import чтобы убедиться, что все прошло успешно.
Этот репозиторий используется для создания файлов данных, которые используются веб-сайтом. После запуска make process создается каталог build , содержащий файлы данных. Этот каталог регистрируется в репозитории, а затем извлекается при создании веб-сайта. После внесения изменений в код важно сравнить созданный каталог build с каталогом build , созданным до изменения кода, и убедиться, что изменения в коде соответствуют ожиданиям.
Поскольку строгое сравнение всего содержимого каталога build всегда будет включать изменения, происходящие независимо от каких-либо изменений кода, каждый разработчик должен знать об этих ожидаемых изменениях, чтобы выполнить эту проверку. Чтобы устранить необходимость в этом, специальный файл bin/create-digests.py генерирует дайджесты для данных JSON в каталоге build после исключения этих ожидаемых изменений. Чтобы найти изменения, исключающие эти ожидаемые изменения, просто найдите изменение в файле build/digests.json .
На данный момент это ожидаемые изменения, которые происходят независимо от каких-либо изменений кода:
Ожидаемые изменения исключаются перед созданием дайджеста для данных в каталоге build . Логику этого можно найти в функции clean_data , которая находится в файле bin/create-digests.py . После того, как код изменен таким образом, что ожидаемое изменение больше не существует, исключение этого изменения можно удалить из clean_data . Например, округление чисел с плавающей запятой не всегда одинаково при каждом запуске make process из-за различий в среде. Когда код исправлен так, что округление чисел с плавающей запятой остается одинаковым до тех пор, пока данные не изменились, вызов round_float в clean_data можно удалить.
Создан дополнительный скрипт для формирования отчета, позволяющего сравнивать итоги по кандидатам. Сценарий bin/report-candidates.py генерирует build/candidates.csv и build/candidates.xlsx . Отчеты включают список всех кандидатов и итоговые суммы, рассчитанные несколькими способами, которые в сумме должны давать одно и то же число.
Чтобы гарантировать, что изменения схемы базы данных будут видны в запросах на включение, полная схема postgres также сохраняется в файле schema.sql в каталоге build . Поскольку каталог build автоматически перестраивается для каждой ветки PR и фиксируется в репозитории, любое изменение схемы, вызванное изменением кода, будет отражено в файле schema.sql при просмотре PR.
Каждая метрика о кандидате рассчитывается независимо. Показателем может быть что-то вроде «общая сумма полученных взносов» или что-то более сложное, например «процент взносов на сумму менее 100 долларов США».
При добавлении нового расчета лучше всего начать с официальной формы 460. Сообщаются ли в этой форме данные, которые вы ищете? Если да, то вы, вероятно, найдете его в своей базе данных после процесса импорта. Есть также пара других форм, которые мы импортируем, например, форма 496. (Это имена файлов во input каталоге. Ознакомьтесь с ними.)
Каждый график каждой формы импортируется в отдельную таблицу postgres. Например, Приложение A формы 460 импортируется в таблицу A-Contributions .
Теперь, когда у вас есть способ запроса данных, вам следует придумать SQL-запрос, который вычисляет значение, которое вы пытаетесь получить. Как только вы сможете выразить свои вычисления в виде SQL, поместите их в файл калькулятора следующим образом:
calculators/[your_thing]_calculator.rb # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID .candidate.save_calculation . Этот метод сериализует свой второй аргумент как JSON, поэтому он может хранить любые данные.candidate.calculation(:your_thing) . Вам нужно будет добавить это в ответ API в process.rb . Именно так данные проходят через серверную часть. Финансовые данные извлекаются из Netfile, который дополняется таблицей Google, сопоставляющей идентификаторы файлов с информацией для голосования, такой как имена кандидатов, должности, показатели голосования и т. д. После того, как данные фильтруются, агрегируются и преобразуются, внешний интерфейс использует их и создает статический HTML. внешний интерфейс.
Во время установки пакета
error: use of undeclared identifier 'LZMA_OK'
Пытаться:
brew unlink xz
bundle install
brew link xz
Во время make download
wget: command not found
Запустите brew install wget .
Во время make import
Похоже, возникла проблема в системах Macintosh, использующих чипы Apple.
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
Попробуйте следующее:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


