feathr
v1.0.0

Feathr — это платформа для разработки данных и искусственного интеллекта, которая на протяжении многих лет широко используется в LinkedIn и была открыта в 2022 году. В настоящее время это проект LF AI & Data Foundation.
Прочтите наше объявление об открытом исходном коде Feathr и Feathr на Azure, а также объявление от LF AI & Data Foundation.
Feathr позволяет вам:
Feathr особенно полезен при моделировании ИИ, где он автоматически вычисляет преобразования ваших функций и присоединяет их к вашим обучающим данным, используя семантику, корректную на определенный момент времени, чтобы избежать утечки данных, а также поддерживает материализацию и развертывание ваших функций для использования в режиме онлайн в производстве.
Самый простой способ опробовать Feathr — использовать Feathr Sandbox, который представляет собой автономный контейнер с большинством возможностей Feathr, и вы сможете продуктивно работать через 5 минут. Чтобы использовать его, просто запустите эту команду:
# 80: Feathr UI, 8888: Jupyter, 7080: Interpret
docker run -it --rm -p 8888:8888 -p 8081:80 -p 7080:7080 -e GRANT_SUDO=yes feathrfeaturestore/feathr-sandbox:releases-v1.0.0И вы можете просмотреть блокнот Jupyter с быстрым запуском Feathr:
http://localhost:8888/lab/workspaces/auto-w/tree/local_quickstart_notebook.ipynbПосле запуска блокнота все функции будут зарегистрированы в пользовательском интерфейсе, и вы сможете посетить пользовательский интерфейс Feathr по адресу:
http://localhost:8081Если вы хотите установить клиент Feathr в среде Python, используйте это:
pip install feathrИли используйте последний код с GitHub:
pip install git+https://github.com/feathr-ai/feathr.git#subdirectory=feathr_projectFeathr имеет встроенную интеграцию с Databricks и Azure Synapse:
Следуйте руководству по развертыванию Feathr ARM, чтобы запустить Feathr в Azure. Это позволит вам быстро приступить к автоматическому развертыванию с помощью шаблона Azure Resource Manager.
Если вы хотите настроить все вручную, вы можете ознакомиться с руководством по развертыванию Feathr CLI для запуска Feathr в Azure. Это позволяет понять, что происходит, и настроить один ресурс за раз.
| Имя | Описание | Платформа |
|---|---|---|
| Демонстрация такси Нью-Йорка | Блокнот для быстрого запуска, в котором показано, как определять, материализовать и регистрировать функции с помощью примеров данных прогнозирования стоимости такси в Нью-Йорке. | Azure Synapse, Databricks, Local Spark |
| Демонстрация Databricks Quickstart в такси Нью-Йорка | Блокнот Quickstart Databricks с примерами данных для прогнозирования стоимости проезда на такси в Нью-Йорке. | Блоки данных |
| Встраивание функций | Пример UDF Feathr, показывающий, как определить и использовать внедрение функций с помощью предварительно обученной модели Transformer и выборочных данных обзора отеля. | Блоки данных |
| Демонстрация обнаружения мошенничества | Пример демонстрации Feature Store с использованием нескольких источников данных, таких как учетная запись пользователя и данные транзакций. | Azure Synapse, Databricks, Local Spark |
| Демо-рекомендация продукта | Пример блокнота Feathr Feature Store со сценарием рекомендации продукта | Azure Synapse, Databricks, Local Spark |
Пожалуйста, прочтите «Полные возможности Feathr» для получения дополнительных примеров. Ниже приведены несколько избранных:
Feathr предоставляет интуитивно понятный пользовательский интерфейс, позволяющий искать и изучать все доступные функции и соответствующие им линии.
Вы можете использовать Feathr UI для поиска объектов, определения источников данных, отслеживания происхождения объектов и управления контролем доступа. Посмотрите последнюю демо-версию здесь, чтобы узнать, чем Feathr UI может вам помочь. Когда вам будет предложено войти в систему, используйте одну из следующих учетных записей:
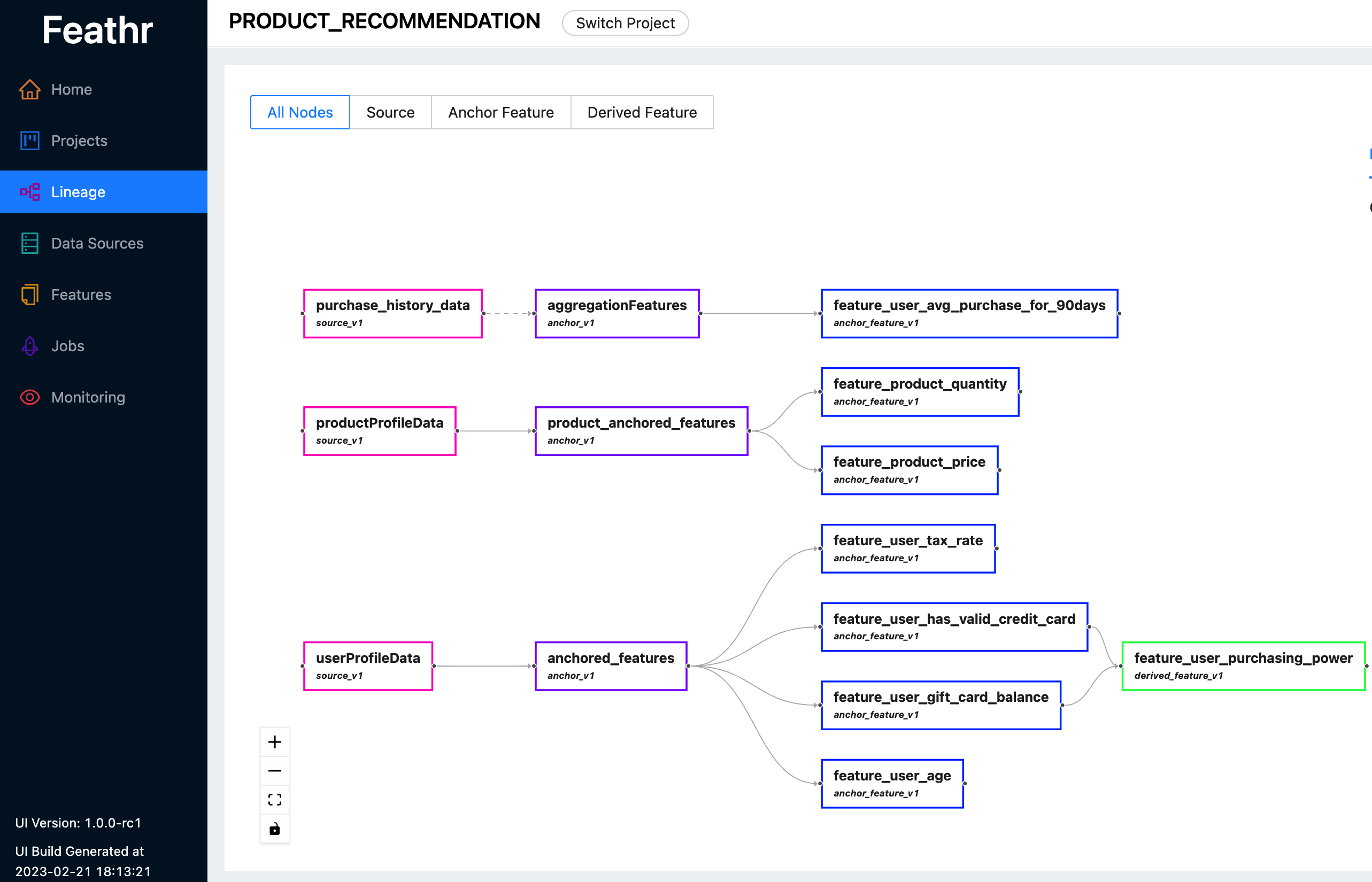
Для получения дополнительной информации о пользовательском интерфейсе Feathr и реестре, лежащем в его основе, обратитесь к реестру функций Feathr.
Feathr имеет гибко настраиваемые пользовательские функции с встроенной интеграцией PySpark и Spark SQL, что позволяет сократить время обучения специалистов по данным:
def add_new_dropoff_and_fare_amount_column ( df : DataFrame ):
df = df . withColumn ( "f_day_of_week" , dayofweek ( "lpep_dropoff_datetime" ))
df = df . withColumn ( "fare_amount_cents" , df . fare_amount . cast ( 'double' ) * 100 )
return df
batch_source = HdfsSource ( name = "nycTaxiBatchSource" ,
path = "abfss://[email protected]/demo_data/green_tripdata_2020-04.csv" ,
preprocessing = add_new_dropoff_and_fare_amount_column ,
event_timestamp_column = "new_lpep_dropoff_datetime" ,
timestamp_format = "yyyy-MM-dd HH:mm:ss" ) agg_features = [ Feature ( name = "f_location_avg_fare" ,
key = location_id , # Query/join key of the feature(group)
feature_type = FLOAT ,
transform = WindowAggTransformation ( # Window Aggregation transformation
agg_expr = "cast_float(fare_amount)" ,
agg_func = "AVG" , # Apply average aggregation over the window
window = "90d" )), # Over a 90-day window
]
agg_anchor = FeatureAnchor ( name = "aggregationFeatures" ,
source = batch_source ,
features = agg_features ) # Compute a new feature(a.k.a. derived feature) on top of an existing feature
derived_feature = DerivedFeature ( name = "f_trip_time_distance" ,
feature_type = FLOAT ,
key = trip_key ,
input_features = [ f_trip_distance , f_trip_time_duration ],
transform = "f_trip_distance * f_trip_time_duration" )
# Another example to compute embedding similarity
user_embedding = Feature ( name = "user_embedding" , feature_type = DENSE_VECTOR , key = user_key )
item_embedding = Feature ( name = "item_embedding" , feature_type = DENSE_VECTOR , key = item_key )
user_item_similarity = DerivedFeature ( name = "user_item_similarity" ,
feature_type = FLOAT ,
key = [ user_key , item_key ],
input_features = [ user_embedding , item_embedding ],
transform = "cosine_similarity(user_embedding, item_embedding)" )Для получения более подробной информации прочтите Руководство по приему потокового источника.
Прочтите «Корректность на момент времени» и «Присоединение к моменту времени» в Feathr для получения более подробной информации.
Следуйте инструкциям по быстрому запуску Jupyter Notebook, чтобы опробовать его. В блокноте также имеется сопутствующее краткое руководство, содержащее дополнительные пояснения.
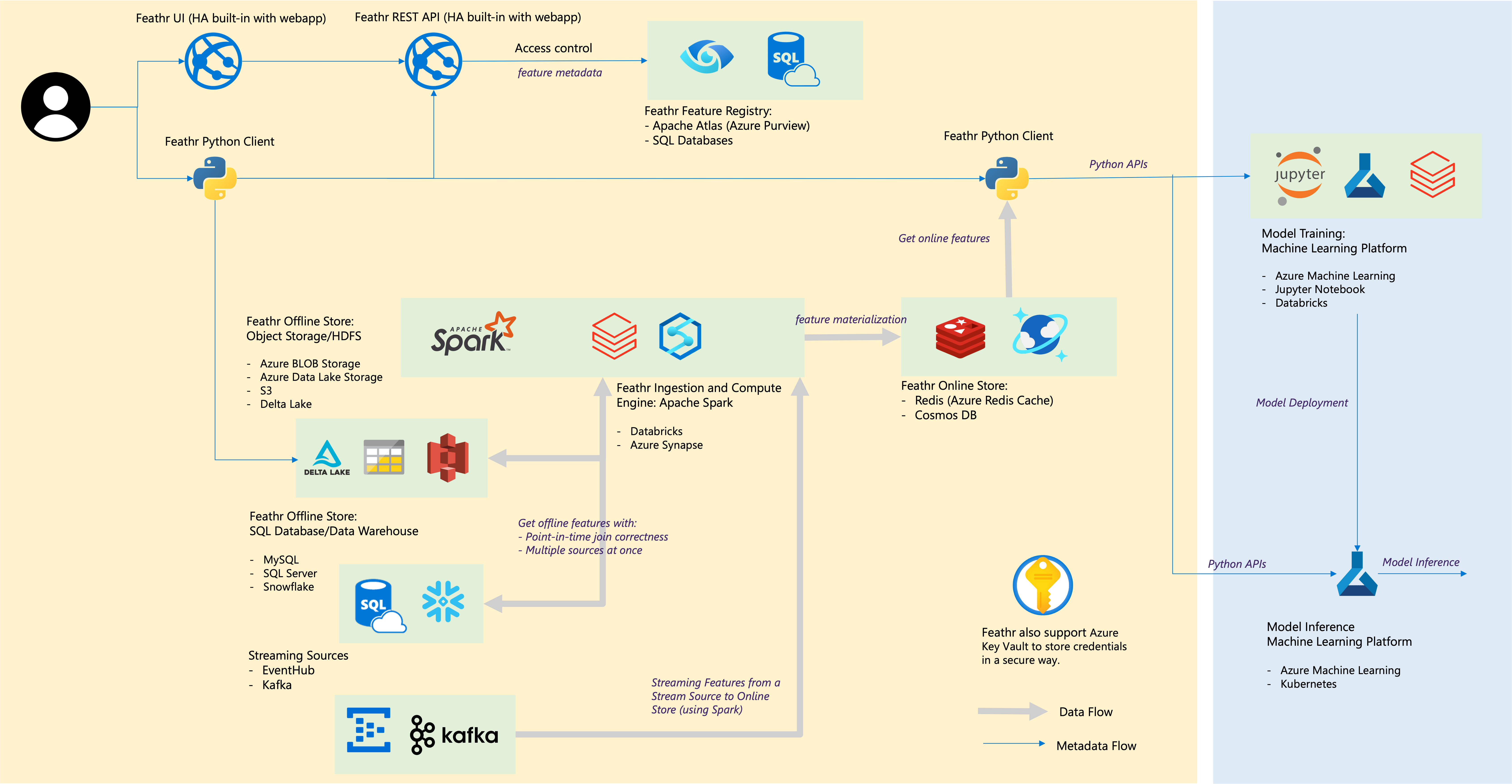
| Компонент пера | Облачная интеграция |
|---|---|
| Офлайн-магазин – Магазин объектов | Хранилище BLOB-объектов Azure, Azure ADLS 2-го поколения, AWS S3 |
| Офлайн-магазин – SQL | База данных SQL Azure, выделенные пулы SQL Azure Synapse, SQL Azure в виртуальной машине, Snowflake |
| Потоковый источник | Кафка, EventHub |
| Интернет-магазин | Redis, Azure CosmoDB. |
| Реестр функций и управление | Azure Purview, ANSI SQL, например Azure SQL Server. |
| Вычислительный двигатель | Пулы Azure Synapse Spark, блоки данных |
| Платформа машинного обучения | Машинное обучение Azure, блокнот Jupyter, блокнот Databricks |
| Формат файла | Паркет, ORC, Avro, JSON, Delta Lake, CSV |
| Реквизиты для входа | Хранилище ключей Azure |
Стройте для сообщества и стройте сообществом. Ознакомьтесь с принципами сообщества.
Присоединяйтесь к нашему каналу Slack, чтобы задать вопросы и обсудить (или нажмите ссылку-приглашение).


