metal flash attention
v1.0.1
Этот репозиторий переносит официальную реализацию FlashAttention на процессоры Apple. Это минимальный, поддерживаемый набор исходных файлов, воспроизводящий алгоритм FlashAttention.
Только однонаправленное внимание, чтобы сосредоточиться на основных узких местах различных алгоритмов внимания (давление регистров, параллелизм). Если базовый алгоритм выполнен правильно, добавление настроек, таких как разреженность блоков, должно быть сравнительно тривиальным.
Все JIT-компилируется во время выполнения. Это контрастирует с предыдущей реализацией, которая основывалась на исполняемом файле, встроенном в Xcode 14.2.
Обратный проход использует меньше памяти, чем Dao-AILab/flash-attention. Официальная реализация выделяет свободное пространство для атомов и частичных сумм. В аппаратном обеспечении Apple отсутствует встроенная атомика FP32 (эмулируется metal::atomic<float> ). При попытке обойти отсутствие аппаратной поддержки были обнаружены узкие места пропускной способности и распараллеливания в обратном ядре FlashAttention-2. Альтернативный обратный проход был разработан с более высокой стоимостью вычислений (7 GEMM вместо 5 GEMM). Он обеспечивает 100% эффективность распараллеливания как по строкам, так и по столбцам матрицы внимания. Самое главное, его легче кодировать и поддерживать.
Было сделано много сумасшедших вещей, чтобы преодолеть узкие места в регистровом давлении. При больших размерах головки (например, 256) ни один из блоков матрицы не помещается в регистры. Даже аккумулятор не может. Таким образом, преднамеренное сброс регистров выполняется, но более оптимизированным способом. К алгоритму внимания было добавлено третье блочное измерение, которое блокируется вдоль D Соотношение сторон блоков матрицы внимания было сильно искажено, чтобы минимизировать затраты полосы пропускания из-за утечки регистров. Например, 16–32 по измерению распараллеливания и 80–128 по измерению обхода. Существует большой файл параметров, который принимает размерность D и определяет, какие операнды могут помещаться в регистры. Затем он назначает размер блока, который уравновешивает множество конкурирующих узких мест.
Конечным результатом является постоянная скорость 4400 гигакоманд в секунду на M1 Max (загрузка ALU 83%) при бесконечной длине последовательности и бесконечном размере головки. При условии, что эмуляция BF16 используется для смешанной точности ( bfloat Metal имеет округление, совместимое с IEEE, что приводит к серьезным накладным расходам на старых чипах без аппаратного обеспечения BF16).
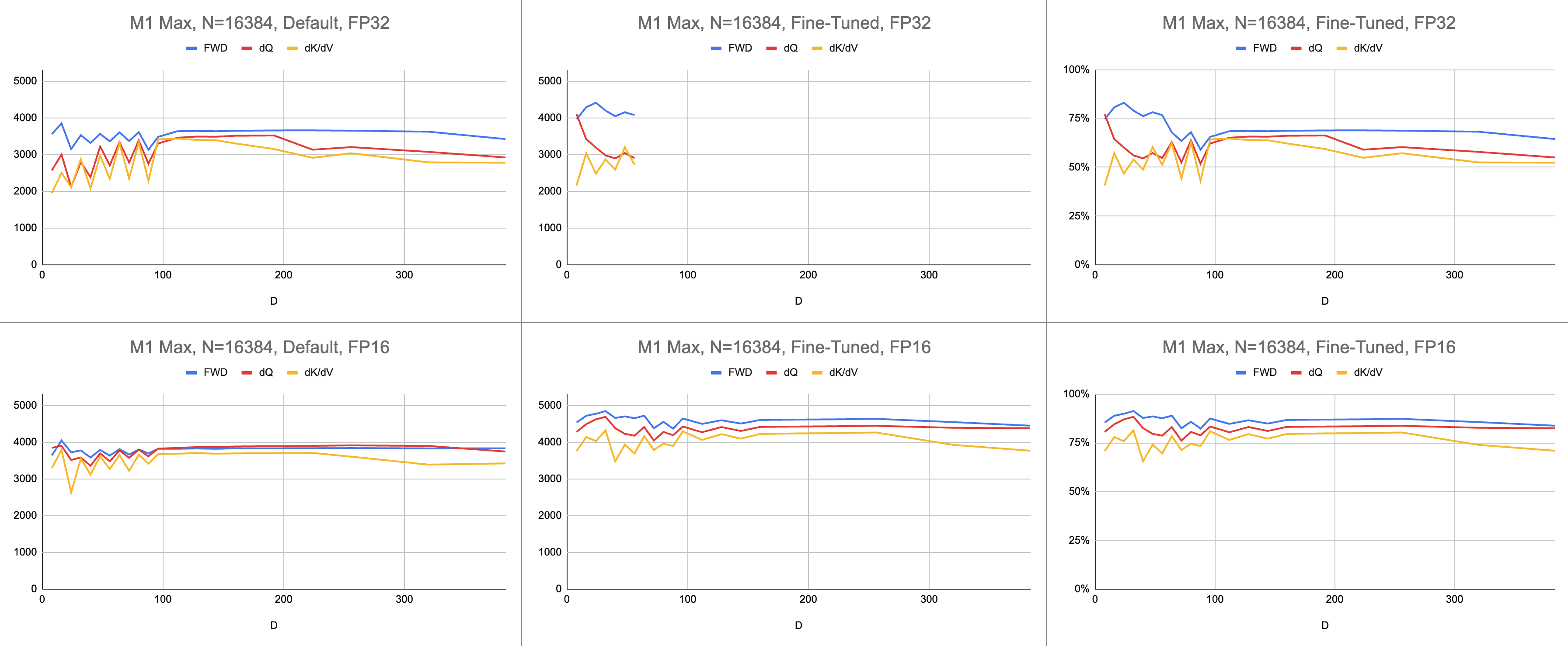
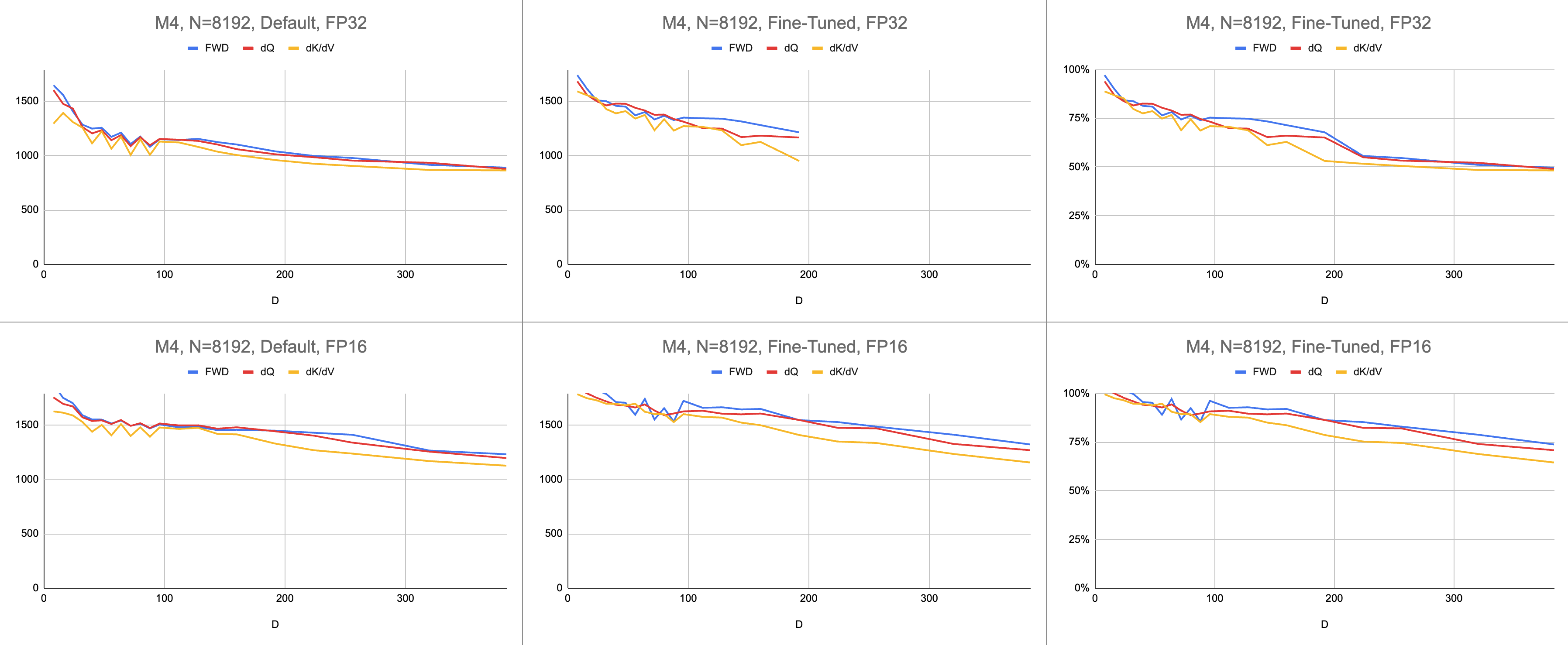
Необработанные данные: https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing.
В области искусственного интеллекта производительность чаще всего выражается в гига операциях с плавающей запятой в секунду (GFLOPS). Эта метрика отражает упрощенную модель производительности, согласно которой каждая инструкция выполняется в GEMM. По мере развития аппаратного обеспечения от ранних FPU до современных векторных процессоров наиболее распространенные операции с плавающей запятой были объединены в одну инструкцию. Слитое умножение-сложение (FMA). При умножении двух матриц размером 100x100 выдается 1 миллион инструкций FMA. Почему мы должны рассматривать эту FMA как две отдельные инструкции?
Этот вопрос актуален для внимания, поскольку не все операции с плавающей запятой одинаковы. Возведение в степень во время softmax происходит за один такт, при условии, что большая часть других инструкций поступает в модуль FMA. Некоторые умножения и сложения во время softmax не могут быть объединены с соседними сложениями или умножениями. Должны ли мы относиться к ним так же, как к FMA, и притворяться, что оборудование просто выполняет FMA в два раза медленнее? Неясно, как модель производительности GEMM может объяснить, эффективно ли мой шейдер использует аппаратное обеспечение ALU.
Вместо гигафлопс я использую гигаинструкции, чтобы понять, насколько хорошо работает шейдер. Это более непосредственно соответствует алгоритму. Например, один GEMM — это N^3 инструкции FMA. Прямое внимание выполняет два умножения матриц или 2 * D * N^2 инструкции FMA. Обратное внимание (в соответствии с реализацией Dao-AILab/flash-attention) — это 5 * D * N^2 инструкций FMA. Попробуйте сравнить эту таблицу с моделями линий крыши в статьях Flash1, Flash2 или Flash3.
| Операция | Работа |
|---|---|
| Квадратный ГЕММ | N^3 |
| Вперед Внимание | (2D + 5) * N^2 |
| Обратное наивное внимание | 4D * N^2 |
| Обратная вспышкаВнимание | (5D + 5) * N^2 |
| Вперед + BWD в сочетании | (7D + 10) * N^2 |
Из-за сложности атомов FP32 MFA использовал другой подход для обратного прохода. У этого есть более высокая стоимость вычислений. Он разделяет обратный проход на два отдельных ядра: dQ и dK/dV . В раскрывающемся списке отображается псевдокод. Сравните это с одним из алгоритмов в статьях Flash1, Flash2 или Flash3.
| Операция | Работа |
|---|---|
| Вперед | (2D + 5) * N^2 |
| Назад dQ | (3D + 5) * N^2 |
| Назад dK/dV | (4D + 5) * N^2 |
| Вперед + BWD в сочетании | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }Производительность измеряется путем расчета объема вычислительной работы, а затем деления его на секунды. Конечным результатом является «гигаинструкций в секунду». Далее нам нужна модель линии крыши. В таблице ниже показаны линии крыши для GINSTRS, рассчитанные как половина GFLOPS. Использование ALU равно (фактическое количество гигаинструкций в секунду) / (ожидаемое количество гигаинструкций в секунду). Например, M1 Max обычно достигает 80% использования ALU со смешанной точностью.
У этой модели есть ограничения. Он ломается с поколением М3 при небольших размерах головки. Различные вычислительные блоки могут использоваться одновременно, в результате чего кажущаяся загрузка превышает 100%. По большей части тест предоставляет точную модель того, сколько производительности осталось в таблице.
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| Аппаратное обеспечение | ГФЛОПС | ГИНСТРС |
|---|---|---|
| М1 Макс | 10616 | 5308 |
| М4 | 3580 | 1790 г. |
Насколько хорош порт Metal по сравнению с официальным репозиторием FlashAttention? Представьте, что я использовал алгоритм «атомного dQ» и достиг 100% производительности. Затем переключился на реальный репозиторий MFA и обнаружил, что обучение модели происходит в 4 раза медленнее. Это будет 25% линии крыши из официального репозитория. Чтобы получить этот процент, умножьте среднее использование ALU по всем трем ядрам на 7 / 9 . Для статистики по оборудованию Apple использовалась более тонкая модель, но суть такова.
Для расчета использования оборудования Nvidia я использовал GFLOPS для ALU FP16/BF16. Я разделил самые высокие GFLOPS из каждого графика в статье на 312 000 (A100 SXM), 989 000 (H100 SXM). Обратите внимание, что для ядер большего размера и с большим количеством регистров (обратный проход) не было зарегистрировано никаких тестов. Я подтвердил, что они не решили проблему давления в регистре при бесконечных размерах головки. Например, аккумулятор всегда хранится в регистрах. На момент написания я не видел конкретных доказательств выполнения обратного градиента D = 256 с правильными результатами.
| А100, Флэш2, ФП16 | Д = 64 | Д = 128 | Д = 256 |
|---|---|---|---|
| Вперед | 192000 | 223000 | 0 |
| Назад | 170000 | 196000 | 0 |
| Вперед + Назад | 176000 | 203000 | 0 |
| H100, Флэш3, ФП16 | Д = 64 | Д = 128 | Д = 256 |
|---|---|---|---|
| Вперед | 497000 | 648000 | 756000 |
| Назад | 474000 | 561000 | 0 |
| Вперед + Назад | 480000 | 585000 | 0 |
| H100, Флэш3, ФП8 | Д = 64 | Д = 128 | Д = 256 |
|---|---|---|---|
| Вперед | 613000 | 1008000 | 1171000 |
| Назад | 0 | 0 | 0 |
| Вперед + Назад | 0 | 0 | 0 |
| А100, Флэш2, ФП16 | Д = 64 | Д = 128 | Д = 256 |
|---|---|---|---|
| Вперед | 62% | 71% | 0% |
| Вперед + Назад | 56% | 65% | 0% |
| H100, Флэш3, ФП16 | Д = 64 | Д = 128 | Д = 256 |
|---|---|---|---|
| Вперед | 50% | 66% | 76% |
| Вперед + Назад | 48% | 59% | 0% |
| Архитектура М1, FP16 | Д = 64 | Д = 128 | Д = 256 |
|---|---|---|---|
| Вперед | 86% | 85% | 86% |
| Вперед + Назад | 62% | 63% | 64% |
| Архитектура М3, FP16 | Д = 64 | Д = 128 | Д = 256 |
|---|---|---|---|
| Вперед | 94% | 91% | 82% |
| Вперед + Назад | 71% | 69% | 61% |
| Аппаратное обеспечение 2020 года выпуска | Д = 64 | Д = 128 | Д = 256 |
|---|---|---|---|
| А100 | 56% | 65% | 0% |
| Архитектура М1—М2 | 62% | 63% | 64% |
| Аппаратное обеспечение 2023 года выпуска | Д = 64 | Д = 128 | Д = 256 |
|---|---|---|---|
| H100 (с использованием FP8 GFLOPS) | 24% | 30% | 0% |
| H100 (с использованием FP16 GFLOPS) | 48% | 59% | 0% |
| Архитектура М3—М4 | 71% | 69% | 61% |
Несмотря на большее количество вычислений, оборудование Apple обучает трансформаторы быстрее, чем оборудование Nvidia, выполняющее ту же работу . Нормализация разницы в размерах между разными графическими процессорами. Просто сосредоточьтесь на том, насколько эффективно используется графический процессор.
Возможно, основному репозиторию следует попробовать алгоритм, который избегает атомарности FP32 и намеренно сбрасывает регистры, когда они не могут поместиться в ядре графического процессора. Это кажется маловероятным, поскольку у них есть жестко запрограммированная поддержка небольшого подмножества возможных размеров проблем. Мотивация, по-видимому, заключается в поддержке наиболее распространенных моделей, где D представляет собой степень 2 и меньше 128. Во всем остальном пользователям приходится полагаться на альтернативные резервные реализации (например, репозиторий MFA), которые могут использовать совершенно другую базовую основу. алгоритм.
В macOS загрузите пакет Swift и скомпилируйте его с помощью -Xswiftc -Ounchecked . Этот параметр компилятора необходим для кода ЦП, чувствительного к производительности. Режим выпуска использовать нельзя, поскольку он заставляет перекомпилировать всю кодовую базу с нуля каждый раз, когда происходит одно изменение. Перейдите к репозиторию Git в Finder и дважды щелкните Package.swift . Должно появиться окно Xcode. Слева должна быть иерархия файлов. Если вы не можете разгадать иерархию, значит что-то пошло не так.
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
Альтернативно создайте новый проект Xcode с шаблоном SwiftUI. Переопределить "Hello, world!" string с вызовом функции, которая возвращает String . Эта функция выполнит выбранный вами сценарий, а затем вызовет exit(0) , поэтому приложение аварийно завершает работу, прежде чем что-либо отобразить на экране. Вы будете использовать вывод консоли Xcode в качестве отзыва о своем коде. Этот рабочий процесс совместим как с macOS, так и с iOS.
Добавьте параметр -Xswiftc -Ounchecked через Project > имя вашего проекта > Настройки сборки > Swift Compiler - Генерация кода > Уровень оптимизации . Во втором столбце таблицы указано название вашего проекта. Нажмите «Другое» в раскрывающемся списке и на появившейся панели введите -Ounchecked . Затем добавьте этот репозиторий в качестве зависимости пакета Swift. Просмотрите некоторые тесты в разделе Tests/FlashAttention . Скопируйте исходный код одного из этих тестов в свой проект. Вызовите тест из функции из предыдущего абзаца. Посмотрите, что отображается на консоли.
Чтобы изменить генерацию кода Metal (например, добавить поддержку нескольких головок или масок), скопируйте необработанный код Swift в свой проект Xcode. Либо используйте git clone в отдельной папке, либо загрузите необработанные файлы на GitHub в виде ZIP. Также есть способ подключиться к вашему форку metal-flash-attention и автоматически сохранить изменения в облаке, но его сложнее настроить. Удалите зависимость пакета Swift из предыдущего абзаца. Повторно запустите тест по вашему выбору. Он что-то компилирует и отображает в консоли?
Найдите один из многострочных строковых литералов в любой из этих папок:
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
Добавьте случайный текст в один из них. Скомпилируйте и запустите проект еще раз. Что-то должно пойти не так. Например, компилятор Metal может выдать ошибку. Если этого не произошло, попробуйте испортить другую строку кода где-нибудь еще. Если тест по-прежнему проходит успешно, Xcode не регистрирует ваши изменения.
Продолжайте кодировать разреженность блоков или что-то в этом роде. Получите обратную связь о том, работает ли код вообще, работает ли он быстро, работает ли он быстро при каждом размере задачи. Интегрируйте исходный код в свое приложение или переведите его на другой язык программирования.


