imagen pytorch
2.1.0
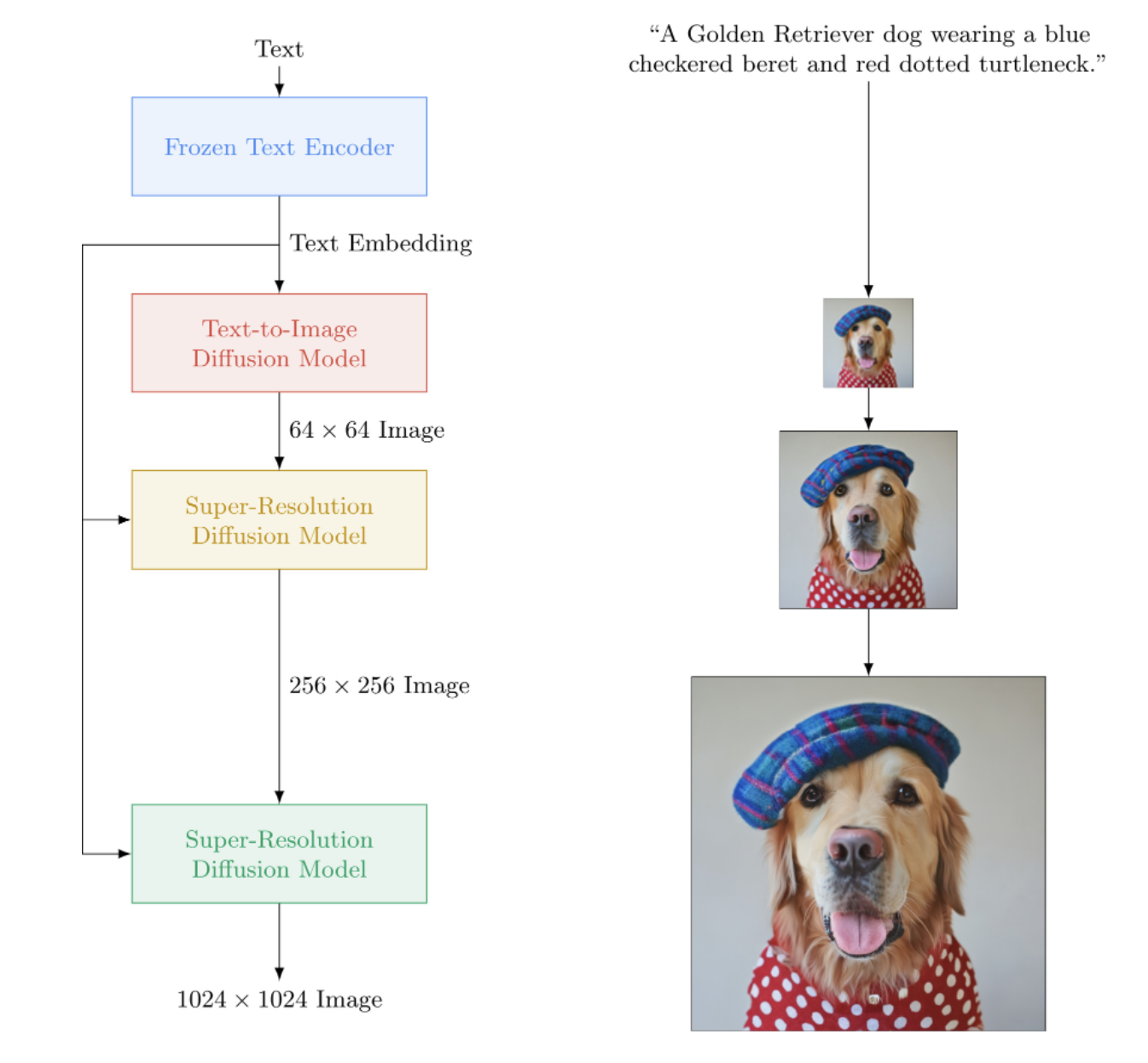
Реализация Imagen, нейронной сети Google для преобразования текста в изображение, превосходящей DALL-E2, в Pytorch. Это новый SOTA для синтеза текста в изображение.
Архитектурно он на самом деле намного проще, чем DALL-E2. Он состоит из каскадной DDPM, обусловленной встраиванием текста из большой предварительно обученной модели T5 (сеть внимания). Он также содержит динамическое отсечение для улучшенного управления без классификатора, согласования уровня шума и эффективного использования памяти.
Похоже, что ни CLIP, ни предыдущая сеть в конце концов не нужны. И поэтому исследования продолжаются.
AI Кофе-брейк с Летицией | Сборка ИИ | Янник Килчер
Пожалуйста, присоединяйтесь, если вы заинтересованы в помощи в воспроизведении с сообществом LAION.
StabilityAI за щедрую спонсорскую поддержку, а также другим моим спонсорам
? Huggingface за потрясающую библиотеку трансформеров. Благодаря им о кодировщике текста в значительной степени позаботились.
Джонатану Хо за революцию в генеративном искусственном интеллекте благодаря своей основополагающей статье
Сильвен и Закари за библиотеку Accelerate, которую этот репозиторий использует для распределенного обучения.
Алекс для einops, незаменимый инструмент для манипуляций с тензорами
Хорхе Гомесу за помощь с кодом загрузки T5 и советы по выбору правильной версии T5.
Кэтрин Кроусон — за ее прекрасный код, который помог мне понять версию гауссовской диффузии с непрерывным временем.
Marunine и Netruk44 за проверку кода, обмен результатами экспериментов и помощь в отладке.
Марунину за предоставление потенциального решения проблемы смещения цвета в u-сетях с эффективным использованием памяти. Спасибо Джейкобу за то, что он поделился экспериментальными сравнениями между базовыми и экономичными по памяти модулями.
Марунину за обнаружение многочисленных ошибок, решение проблемы с правом изменения размера, а также за то, что поделился своими экспериментальными конфигурациями и результатами.
MalumaDev за предложение использовать повышающую дискретизацию Pixel Shuffle для исправления артефактов шахматной доски.
Валентину за указание на недостаточную пропускную связь в унете, а также конкретный метод тренировки внимания в базисе-унете в приложении.
BIGJUN для обнаружения большой ошибки с непрерывным определением уровня гауссовского диффузионного шума во время вывода
Bingbing для выявления ошибки с выборкой и порядком нормализации и зашумления с кондиционированием изображения низкого разрешения.
Кей за участие в обучении командной строке Imagen!
Адриану Рейно за тестирование преобразования текста в видео на наборе медицинских данных, обмен результатами и выявление проблем!
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)Для упрощения обучения вы можете напрямую предоставлять текстовые строки вместо предварительного вычисления кодировок текста. (Хотя в целях масштабирования вам обязательно понадобится предварительно вычислить текстовые вложения + маску)
Если вы пойдете по этому пути, количество текстовых подписей должно соответствовать размеру пакета изображений.
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () С помощью класса-оболочки ImagenTrainer экспоненциальные скользящие средние для всех U-сетей в каскадном DDPM будут автоматически учитываться при вызове update
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)Вы также можете обучать Imagen без текста (безусловная генерация изображения) следующим образом:
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)Или тренируйте только суперразрешающие юнцы
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) В любой момент вы можете сохранить и загрузить трейнер и все связанные с ним состояния с помощью методов save и load . Рекомендуется использовать эти методы вместо ручного сохранения с помощью вызова state_dict , так как некоторые функции управления памятью устройства выполняются внутри трейнера.
бывший.
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 Вы также можете положиться на ImagenTrainer для автоматического обучения экземпляров DataLoader . Вам просто нужно создать свой DataLoader так, чтобы он возвращал либо images (для безусловного случая), либо ('images', 'text_embeds') для генерации с помощью текста.
бывший. безусловное обучение
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )Благодаря? Ускорьтесь: вы можете легко провести обучение на нескольких графических процессорах, выполнив два шага.
Сначала вам нужно вызвать accelerate config в том же каталоге, что и ваш обучающий скрипт (скажем, он называется train.py ).
$ accelerate config Далее, вместо вызова python train.py , как для одного графического процессора, вы должны использовать ускоренный CLI следующим образом.
$ accelerate launch train.pyВот и все!
Imagen также можно использовать напрямую через CLI.
бывший.
$ imagen configили
$ imagen config --path ./configs/config.jsonВ конфигурации вы можете изменить настройки тренера, набора данных и конфигурации изображения.
Параметры конфигурации Imagen можно найти здесь.
Параметры конфигурации Elucidated Imagen можно найти здесь.
Параметры конфигурации Imagen Trainer можно найти здесь.
В качестве параметров набора данных можно использовать все параметры загрузчика данных.
Эта команда позволяет вам обучить или возобновить обучение вашей модели.
бывший.
$ imagen trainили
$ imagen train --unet 2 --epoches 10Вы можете передать следующие аргументы команде обучения.
--config указать файл конфигурации, который будет использоваться для обучения [по умолчанию: ./imagen_config.json]--unet индекс unet для обучения [по умолчанию: 1]--epoches сколько эпох нужно тренировать [по умолчанию: 50]Имейте в виду, что при отборе проб ваша контрольная точка должна была обучить всех участников, чтобы получить полезный результат.
бывший.
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.pngВы можете передать следующие аргументы в пример команды.
--model указать файл модели, который будет использоваться для выборки--cond_scale условная шкала (бесплатное руководство по классификатору) в декодере--load_ema загрузить EMA-версию unets, если она доступна Чтобы использовать сохраненную контрольную точку с этой функцией, вам необходимо либо создать экземпляр вашего экземпляра Imagen, используя классы конфигурации ImagenConfig и ElucidatedImagenConfig , либо создать контрольную точку напрямую через CLI.
Для правильного обучения вам, вероятно, в любом случае захочется настроить обучение на основе конфигурации.
бывший.
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminalЭто действительно должно быть так просто
Вы также можете передать этот файл контрольных точек, и каждый сможет продолжить точную настройку своих собственных данных.
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning Inpainting следует формулировке, изложенной в недавней статье Repaint. Просто передайте inpaint_images и inpaint_masks в функцию- sample Imagen или ElucidatedImagen
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512) Для видео аналогичным образом передайте свои видео ключевому слову inpaint_videos в .sample . Маска отрисовки может быть одинаковой для всех кадров (batch, height, width) или разной (batch, frames, height, width)
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) Теро Каррас из StyleGAN написал новую статью, результаты которой были подтверждены рядом независимых исследователей, а также на моей собственной машине. Я решил создать версию Imagen , ElucidatedImagen , чтобы можно было использовать новый разъясненный DDPM для каскадной генерации с текстовым управлением.
Просто импортируйте ElucidatedImagen , а затем создайте экземпляр экземпляра, как вы это делали раньше. Гиперпараметры отличаются от обычных для дискретной и непрерывной гауссовской диффузии и могут быть индивидуализированы для каждой сети в каскаде.
Бывший.
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above В этом репозитории также начнут накапливаться новые исследования в области синтеза видео с текстовым сопровождением. Для начала он будет использовать 3D-архитектуру unet, описанную Джонатаном Хо в разделе «Модели распространения видео».
Обновление: проверено, работает Адриан Рейно!
Бывший.
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32) Вы также можете сначала потренироваться на парах текст-изображение. Unet3D автоматически преобразует его в однокадровое видео и обучается без временных компонентов (автоматически устанавливая ignore_time = True ), будь то одномерные извилины или причинное внимание во времени.
Это текущий подход, используемый всеми крупными лабораториями искусственного интеллекта (Brain, MetaAI, Bytedance).
Imagen использует алгоритм под названием Classifier Free Guidance. При выборке вы применяете шкалу к обусловленности (в данном случае тексту) более 1.0 .
Исследователь Нетрук44 сообщил, что оптимальное значение — 5-10 , но все, что больше 10 — нарушение.
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than averageНа данный момент нет, но, скорее всего, один из них будет обучен и открыт в течение года, если не раньше. Если вы хотите принять участие, вы можете присоединиться к сообществу инструкторов искусственных нейронных сетей в Laion (ссылка на дискорд находится в файле Readme выше) и начать сотрудничество.
Это еще одна причина, по которой вам следует начать тренировать свою собственную модель, начиная с сегодняшнего дня! Меньше всего нам нужно, чтобы эта технология находилась в руках немногих избранных. Надеемся, что этот репозиторий сведет работу к простому поиску необходимых вычислений и дополнению их собственным набором данных.
Что-либо! Имеет лицензию MIT. Другими словами, вы можете свободно копировать и вставлять данные для своих собственных исследований, создавая ремиксы для любой модальности, о которой вы только можете подумать. Тренируйте удивительные модели ради прибыли, для науки или просто для того, чтобы насытить свое личное удовольствие, наблюдая, как перед вами разворачивается нечто божественное.
Синтез эхокардиограммы [Код]
Синтез контактной матрицы SOTA Hi-C [Код]
Создание плана этажа
Слайды гистопатологии сверхвысокого разрешения
Синтетические лапароскопические изображения
Проектирование метаматериалов
Аудиодиффузия от Флавио Шнайдера
Мини-изображение от Райана О. | Описание сборки AI
используйте преобразователи Huggingface для встраивания небольшого текста T5
добавить динамическое пороговое определение
добавить динамическую пороговую обработку DALLE2 и хранилище видео-диффузии
позволить установить T5-большой (и, возможно, маленький заводской метод, позволяющий использовать любой трансформатор с обнимающимся лицом)
добавьте уровень шума низкого разрешения с помощью псевдокода в приложении и выясните, что это за развертка, которую они делают во время вывода.
портировать некоторый обучающий код из DALLE2
необходимо иметь возможность использовать разные графики шума для каждой сети (косинус использовался для базы, но линейный для SR)
просто создайте один настраиваемый мастером unet
полная блокировка резнета (вдохновление Биггана? но с групповой нормой) - полное внимание к себе
полный блок встраивания кондиционирования (и сделать его полностью настраиваемым, будь то внимание, фильм и т. д.)
рассмотрите возможность использования воспринимающего-ресэмплера из https://github.com/lucidrains/flamingo-pytorch вместо объединения внимания
добавить опцию объединения внимания в дополнение к перекрестному вниманию и съемке
добавить дополнительный график затухания косинуса с прогревом для каждого юнита в трейнер
переключиться на непрерывные временные шаги вместо дискретизированных, так как кажется, что именно это они использовали на всех этапах - сначала выясните случай графика линейного шума из вариационной статьи ddpm https://openreview.net/forum?id=2LdBqxc1Yv
выясните log(snr) для графика альфа-косинусного шума.
отключить предупреждение трансформаторов, поскольку используется только энкодер T5
разрешить настройку использования линейного внимания на слоях, где невозможно использовать полное внимание
заставить unets в случае непрерывного времени использовать условия без фурье (просто передайте журнал (snr) через MLP с дополнительными нормами слоев), поскольку это то, что я работаю локально
удалена изученная дисперсия
добавить взвешивание потерь p2 для непрерывного времени
убедитесь, что каскадный ddpm можно обучить без текстового условия, и убедитесь, что работает гауссова диффузия как с непрерывным, так и с дискретным временем.
используйте глубинные преобразования праймера для проекций qkv при линейном внимании (или используйте сдвиг токенов перед проекциями) - также используйте новый отсев, предложенный байесформером, поскольку он, кажется, хорошо работает с линейным вниманием
изучить возбуждение пропуска слоя в декодере unet
ускорить интеграцию
создать инструмент CLI и создать однострочное изображение
устранить любые проблемы, возникшие из-за ускорения
добавить возможность рисования с помощью ресэмплера из бумаги для перекраски https://arxiv.org/abs/2201.09865
создать простую систему контрольных точек, поддерживаемую папкой
добавить соединение пропуска из выходов всех блоков повышенной дискретизации, используемое в квадратной бумаге unet и некоторых предыдущих работах unet
добавить fsspec, рекомендованный Роменом @rom1504, для сохранения контрольных точек независимо от облачной/локальной файловой системы.
проверьте постоянство в gcs с помощью https://github.com/fsspec/gcsfs
распространиться на генерацию видео, используя внимание по осевому времени, как в статье Хо о видео ddpm.
позволяют выясненному изображению обобщать любую форму
позволить изображению обобщать любую форму
добавить динамическое позиционное смещение для наилучшего типа экстраполяции длины по времени видео
переместите видеокадры в функцию выборки, так как мы будем пытаться экстраполировать время
Смещение внимания к нулевому ключу/значению должно быть изученным скаляром размера головы
добавить самокондиционирование из бумаги с битовой диффузией, уже закодированной в ddpm-pytorch
добавить v-параметризацию (https://arxiv.org/abs/2202.00512) из изображения видеобумаги, единственное новое
включить все уроки, полученные при создании видео (https://makeavideo.studio/)
создать инструмент CLI для обучения, возобновить обучение из файла конфигурации
разрешить временную интерполяцию на определенных этапах
убедитесь, что временная интерполяция работает с рисованием
убедитесь, что можно настроить все режимы интерполяции (некоторые исследователи находят лучшие результаты при использовании трилинейной интерполяции)
imagen-video: позволяет настраивать предыдущие (и, возможно, будущие) кадры видео. время игнорирования не должно быть разрешено в этом сценарии
обязательно автоматически позаботьтесь о временной понижающей/повышающей дискретизации для обработки видеокадров, но оставьте возможность отключить ее
убедитесь, что рисование работает с видео
убедитесь, что маска рисования для видео может быть настроена для каждого кадра
добавить мгновенное внимание
перечитайте cogvideo и выясните, как можно использовать регулирование частоты кадров
привлечь внимание к слоям самообслуживания в unet3d
рассмотрите возможность привлечения 3D-сверточного внимания NUWA
рассмотреть воспоминания Transformer-XL в блоках временного внимания
рассмотрите воспринимающий подход к обращению к прошлому времени
выпадение кадров во время внимания для достижения как эффекта регуляризации, так и сокращения времени обучения
расследовать заявления Фрэнка Вуда https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch и либо добавить метод иерархической выборки, либо сообщить людям о его недостатках
предложить сложную движущуюся систему (с объектами-отвлекателями) в качестве однострочной обучаемой базовой линии, которую исследователи могут использовать для преобразования текста в видео
предварительное кодирование текста в встраивания, отображаемые в памяти
уметь создавать итераторы загрузчика данных на основе стиля старой эпохи, а также настраивать перетасовку и т. д.
иметь возможность также передавать аргументы (вместо того, чтобы требовать, чтобы вперед были все аргументы ключевых слов в модели)
добавьте обратимые блоки из revnets для 3d unet, чтобы уменьшить нагрузку на память
добавить возможность обучать только сеть сверхвысокого разрешения
прочитайте dpm-solver и посмотрите, применимо ли оно к гауссовой диффузии с непрерывным временем
разрешить кондиционирование видеокадров с произвольным абсолютным временем (вычисление RPE во время временного внимания)
тонкая настройка стенда мечты
добавить текстовую инверсию
самоподготовка очистки для извлечения при создании экземпляра изображения
убедитесь, что будущий Dreambooth работает с imagen-video
добавить настройку частоты кадров для распространения видео
убедитесь, что можно одновременно настроить видеокадры в качестве подсказки, а также некоторую настройку изображения для всех кадров
протестируйте и добавьте технику дистилляции на основе моделей консистенции
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

