PaLM rlhf pytorch
0.3.9
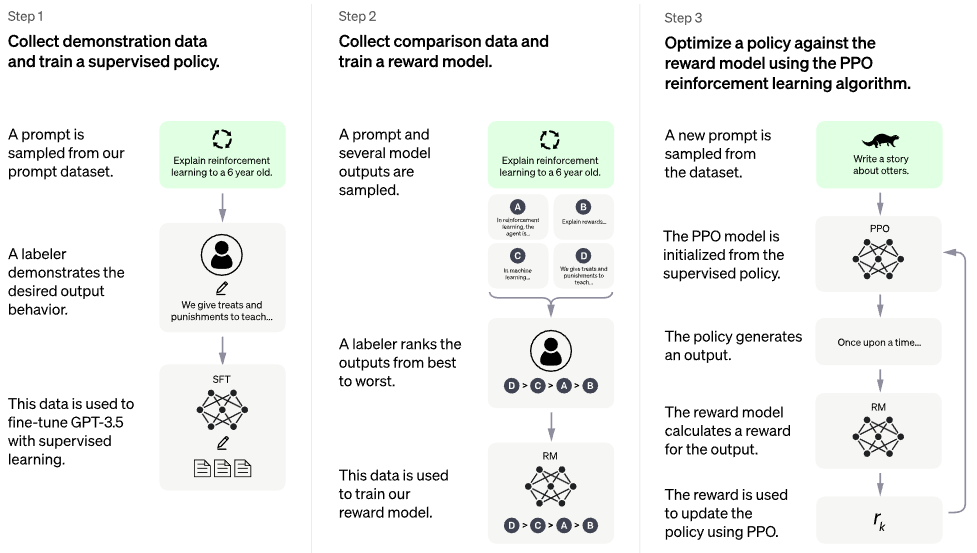
официальный блог чатгпт
Внедрение RLHF (обучение с подкреплением с обратной связью от человека) поверх архитектуры PaLM. Может, добавлю и поисковый функционал, а-ля РЕТРО
Если вы заинтересованы в открытом воспроизведении чего-то вроде ChatGPT, рассмотрите возможность присоединиться к Laion.
Потенциальный преемник: оптимизация прямых предпочтений — весь код в этом репозитории становится ~ потерей двоичной перекрестной энтропии, <5 лок. Вот и все о моделях вознаграждений и PPO.
Нет обученной модели. Это только корабль и общая карта. Нам все еще нужны миллионы долларов вычислений и данных, чтобы добраться до нужной точки в многомерном пространстве параметров. Даже в этом случае вам понадобятся профессиональные моряки (такие как Робин Ромбах из «Стабильной диффузии»), которые действительно проведут корабль через неспокойные времена к этой точке.
CarperAI работал над структурой RLHF для больших языковых моделей в течение многих месяцев до выпуска ChatGPT.
Янник Килчер также работает над реализацией с открытым исходным кодом.
Кофе-брейк AI с Летицией | Кодовый магазин | Code Emporium, часть 2
Stability.ai за щедрую спонсорскую поддержку передовых исследований в области искусственного интеллекта.
? Hugging Face и CarperAI за написание статьи в блоге «Иллюстрирование обучения с подкреплением на основе обратной связи с людьми» (RLHF), а также за их библиотеку ускорения.
@kisseternity и @taynoel84 за проверку кода и поиск ошибок.
Энрико за интеграцию Flash Attention из Pytorch 2.0.
$ pip install palm-rlhf-pytorch Сначала обучите PaLM , как и любой другой авторегрессионный преобразователь.
import torch
from palm_rlhf_pytorch import PaLM
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
flash_attn = True # https://arxiv.org/abs/2205.14135
). cuda ()
seq = torch . randint ( 0 , 20000 , ( 1 , 2048 )). cuda ()
loss = palm ( seq , return_loss = True )
loss . backward ()
# after much training, you can now generate sequences
generated = palm . generate ( 2048 ) # (1, 2048) Затем тренируйте свою модель вознаграждения, используя тщательно подобранную обратную связь от людей. В исходной статье они не могли получить модель вознаграждения, которую можно было бы точно настроить на основе предварительно обученного преобразователя без переобучения, но я все равно дал возможность точной настройки с помощью LoRA , поскольку это все еще открытое исследование.
import torch
from palm_rlhf_pytorch import PaLM , RewardModel
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
causal = False
)
reward_model = RewardModel (
palm ,
num_binned_output = 5 # say rating from 1 to 5
). cuda ()
# mock data
seq = torch . randint ( 0 , 20000 , ( 1 , 1024 )). cuda ()
prompt_mask = torch . zeros ( 1 , 1024 ). bool (). cuda () # which part of the sequence is prompt, which part is response
labels = torch . randint ( 0 , 5 , ( 1 ,)). cuda ()
# train
loss = reward_model ( seq , prompt_mask = prompt_mask , labels = labels )
loss . backward ()
# after much training
reward = reward_model ( seq , prompt_mask = prompt_mask ) Затем вы передадите свой трансформер и модель вознаграждений RLHFTrainer
import torch
from palm_rlhf_pytorch import PaLM , RewardModel , RLHFTrainer
# load your pretrained palm
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12
). cuda ()
palm . load ( './path/to/pretrained/palm.pt' )
# load your pretrained reward model
reward_model = RewardModel (
palm ,
num_binned_output = 5
). cuda ()
reward_model . load ( './path/to/pretrained/reward_model.pt' )
# ready your list of prompts for reinforcement learning
prompts = torch . randint ( 0 , 256 , ( 50000 , 512 )). cuda () # 50k prompts
# pass it all to the trainer and train
trainer = RLHFTrainer (
palm = palm ,
reward_model = reward_model ,
prompt_token_ids = prompts
)
trainer . train ( num_episodes = 50000 )
# then, if it succeeded...
# generate say 10 samples and use the reward model to return the best one
answer = trainer . generate ( 2048 , prompt = prompts [ 0 ], num_samples = 10 ) # (<= 2048,) клон-база-трансформер с отдельной лорой для критика
также допускает точную настройку, не основанную на LoRA
повторить нормализацию, чтобы иметь возможность иметь замаскированную версию, не уверен, будет ли кто-нибудь когда-либо использовать вознаграждения/ценности за токен, но хорошая практика для реализации
оборудовать с лучшим вниманием
добавьте ускорение Hugging Face и опробуйте инструменты wandb
поищите литературу, чтобы выяснить, какая последняя версия SOTA для PPO, предполагая, что область RL все еще развивается.
протестируйте систему, используя предварительно обученную сеть настроений в качестве модели вознаграждения
записать память в PPO в файл numpy с памятью
получить выборку с работающими подсказками переменной длины, даже если в этом нет необходимости, учитывая, что узким местом является обратная связь от человека
разрешить точную настройку предпоследних N слоев только у актера или критика, при условии, что они предварительно обучены
включить некоторые обучающие моменты из Воробья, учитывая видео Летиции
простой веб-интерфейс с django + htmx для сбора отзывов людей
рассмотреть вопрос о RLAIF
@article { Stiennon2020LearningTS ,
title = { Learning to summarize from human feedback } ,
author = { Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan J. Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2009.01325 }
} @inproceedings { Chowdhery2022PaLMSL ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = {Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam M. Shazeer and Vinodkumar Prabhakaran and Emily Reif and Nan Du and Benton C. Hutchinson and Reiner Pope and James Bradbury and Jacob Austin and Michael Isard and Guy Gur-Ari and Pengcheng Yin and Toju Duke and Anselm Levskaya and Sanjay Ghemawat and Sunipa Dev and Henryk Michalewski and Xavier Garc{'i}a and Vedant Misra and Kevin Robinson and Liam Fedus and Denny Zhou and Daphne Ippolito and David Luan and Hyeontaek Lim and Barret Zoph and Alexander Spiridonov and Ryan Sepassi and David Dohan and Shivani Agrawal and Mark Omernick and Andrew M. Dai and Thanumalayan Sankaranarayana Pillai and Marie Pellat and Aitor Lewkowycz and Erica Oliveira Moreira and Rewon Child and Oleksandr Polozov and Katherine Lee and Zongwei Zhou and Xuezhi Wang and Brennan Saeta and Mark Diaz and Orhan Firat and Michele Catasta and Jason Wei and Kathleen S. Meier-Hellstern and Douglas Eck and Jeff Dean and Slav Petrov and Noah Fiedel},
year = { 2022 }
} @article { Hu2021LoRALA ,
title = { LoRA: Low-Rank Adaptation of Large Language Models } ,
author = { Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09685 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Yuan2024FreePR ,
title = { Free Process Rewards without Process Labels } ,
author = { Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:274445748 }
}

