make a video pytorch
0.4.0
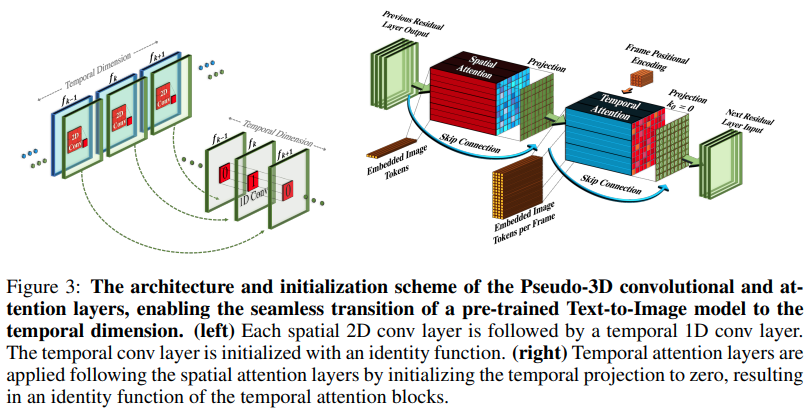
Реализация Make-A-Video, нового генератора текста SOTA в видео от Meta AI, в Pytorch. Они сочетают в себе псевдо-3D извилины (осевые извилины) и временное внимание и демонстрируют гораздо лучшее временное слияние.
Псевдо-3D-извилины — не новая концепция. Ранее это исследовалось в других контекстах, например, для предсказания контактов белков как «мерные гибридные остаточные сети».
Суть статьи сводится к тому, что нужно взять модель преобразования текста в изображение SOTA (здесь используется DALL-E2, но те же моменты обучения легко применить и к Imagen), внести несколько незначительных изменений для привлечения внимания во времени и другими способами. чтобы сэкономить на вычислительных затратах, правильно выполнить интерполяцию кадров и получить отличную видеомодель.
Объяснение кофе-брейка AI
Stability.ai за щедрую спонсорскую поддержку передовых исследований в области искусственного интеллекта.
Джонатану Хо за революцию в генеративном искусственном интеллекте благодаря своей основополагающей статье
Алекс для эйнопсов, абстракция просто гениальная. Другого слова для этого нет.
$ pip install make-a-video-pytorchПередача функций видео
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)При передаче изображений (если сначала предварительно обучить изображения), как временная свертка, так и внимание будут автоматически пропущены. Другими словами, вы можете напрямую использовать это в своем 2d Unet, а затем перенести его на 3d Unet, как только этот этап обучения будет завершен. Временные модули инициализируются для вывода идентичности, как это было сделано в статье.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)Вы также можете управлять двумя модулями, чтобы при подаче трехмерных функций обучение выполнялось только в пространстве.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16) Полный SpaceTimeUnet , который не зависит от изображений или видеообучения, и даже если передается видео, время можно игнорировать.
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )обратите внимание на лучшие исследования позиционных вложений, которые могут предложить
привлечь внимание
добавить мгновенное внимание
убедитесь, что dalle2-pytorch может принять SpaceTimeUnet для обучения
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

