e2 tts pytorch
1.7.1
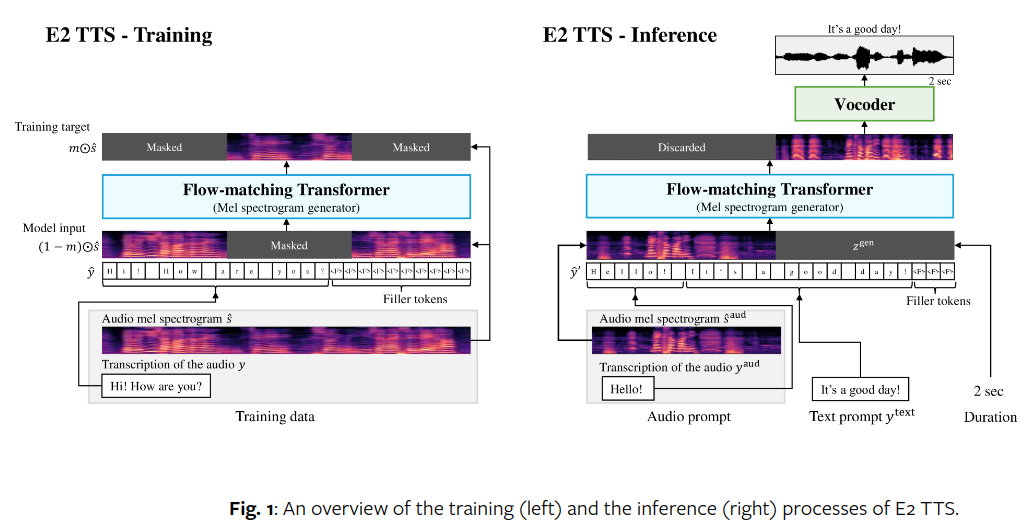
Реализация E2-TTS, невероятно простой, полностью неавторегрессивной TTS с нулевым выстрелом, в Pytorch
Репозиторий отличается от документа тем, что в нем используется многопоточный преобразователь для текста и звука, при этом обработка каждого блока преобразователя выполняется в стиле E2.
Он также включает в себя импровизацию, проверенную Мэнмэем, где текст просто интерполируется по длине звука для кондиционирования. Вы можете попробовать это, установив interpolated_text = True в E2TTS
Manmay за предоставленный работающий комплексный обучающий код!
Лукасу Ньюману за предоставленный код, полезные отзывы и за то, что поделился первым набором положительных экспериментов!
Цзин за то, что поделился вторым положительным результатом с многоязычным (английским и китайским) набором данных!
Койсу и Мэнмэю за отчет о третьем и четвертом успешных пробегах. Прощай, техника выравнивания
$ pip install e2-tts-pytorch import torch
from e2_tts_pytorch import (
E2TTS ,
DurationPredictor
)
duration_predictor = DurationPredictor (
transformer = dict (
dim = 512 ,
depth = 8 ,
)
)
mel = torch . randn ( 2 , 1024 , 100 )
text = [ 'Hello' , 'Goodbye' ]
loss = duration_predictor ( mel , text = text )
loss . backward ()
e2tts = E2TTS (
duration_predictor = duration_predictor ,
transformer = dict (
dim = 512 ,
depth = 8
),
)
out = e2tts ( mel , text = text )
out . loss . backward ()
sampled = e2tts . sample ( mel [:, : 5 ], text = text ) @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @article { Bao2022AllAW ,
title = { All are Worth Words: A ViT Backbone for Diffusion Models } ,
author = { Fan Bao and Shen Nie and Kaiwen Xue and Yue Cao and Chongxuan Li and Hang Su and Jun Zhu } ,
journal = { 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 22669-22679 } ,
url = { https://api.semanticscholar.org/CorpusID:253581703 }
} @article { Burtsev2021MultiStreamT ,
title = { Multi-Stream Transformers } ,
author = { Mikhail S. Burtsev and Anna Rumshisky } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2107.10342 } ,
url = { https://api.semanticscholar.org/CorpusID:236171087 }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
} @article { Gulati2020ConformerCT ,
title = { Conformer: Convolution-augmented Transformer for Speech Recognition } ,
author = { Anmol Gulati and James Qin and Chung-Cheng Chiu and Niki Parmar and Yu Zhang and Jiahui Yu and Wei Han and Shibo Wang and Zhengdong Zhang and Yonghui Wu and Ruoming Pang } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2005.08100 } ,
url = { https://api.semanticscholar.org/CorpusID:218674528 }
} @article { Yang2024ConsistencyFM ,
title = { Consistency Flow Matching: Defining Straight Flows with Velocity Consistency } ,
author = { Ling Yang and Zixiang Zhang and Zhilong Zhang and Xingchao Liu and Minkai Xu and Wentao Zhang and Chenlin Meng and Stefano Ermon and Bin Cui } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2407.02398 } ,
url = { https://api.semanticscholar.org/CorpusID:270878436 }
} @article { Li2024SwitchEA ,
title = { Switch EMA: A Free Lunch for Better Flatness and Sharpness } ,
author = { Siyuan Li and Zicheng Liu and Juanxi Tian and Ge Wang and Zedong Wang and Weiyang Jin and Di Wu and Cheng Tan and Tao Lin and Yang Liu and Baigui Sun and Stan Z. Li } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2402.09240 } ,
url = { https://api.semanticscholar.org/CorpusID:267657558 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
} @inproceedings { Duvvuri2024LASERAW ,
title = { LASER: Attention with Exponential Transformation } ,
author = { Sai Surya Duvvuri and Inderjit S. Dhillon } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273849947 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}

